 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Visual Representation Learning through Perceptual Understanding
Dec 30, 2022



We present an extension to masked autoencoders (MAE) which improves on the representations learnt by the model by explicitly encouraging the learning of higher scene-level features. We do this by: (i) the introduction of a perceptual similarity term between generated and real images (ii) incorporating several techniques from the adversarial training literature including multi-scale training and adaptive discriminator augmentation. The combination of these results in not only better pixel reconstruction but also representations which appear to capture better higher-level details within images. More consequentially, we show how our method, Perceptual MAE, leads to better performance when used for downstream tasks outperforming previous methods. We achieve 78.1% top-1 accuracy linear probing on ImageNet-1K and up to 88.1% when fine-tuning, with similar results for other downstream tasks, all without use of additional pre-trained models or data.
Efficient On-the-fly Category Retrieval using ConvNets and GPUs
Nov 17, 2014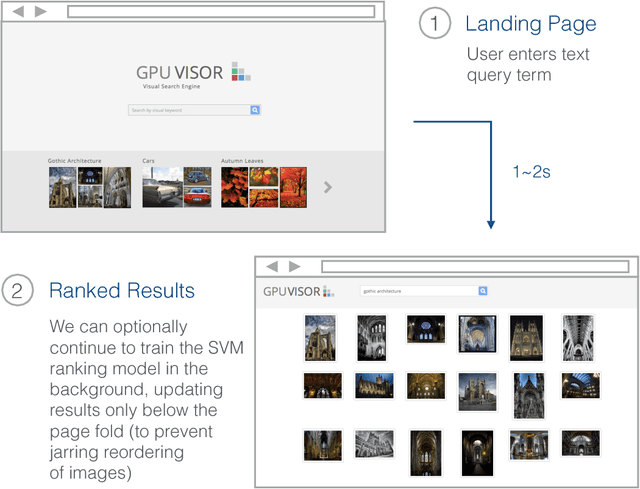
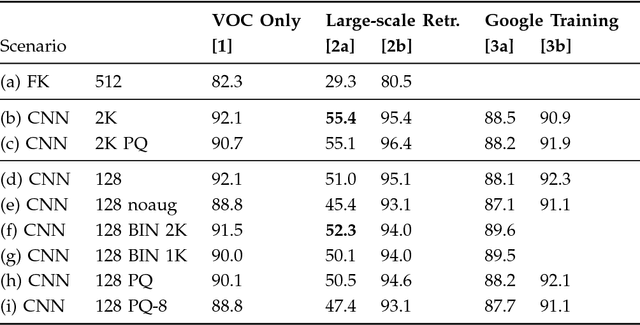
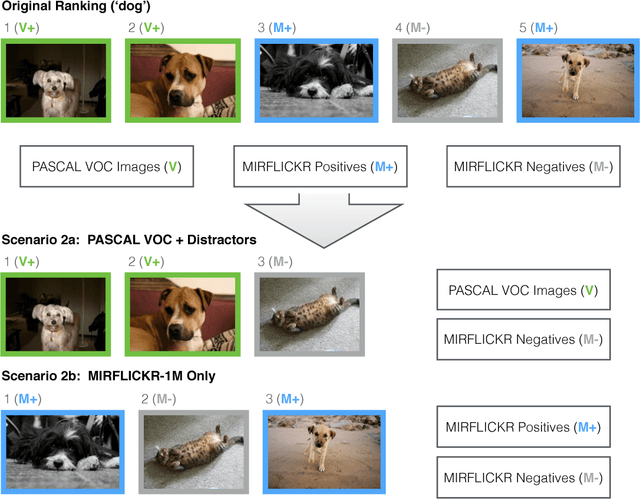
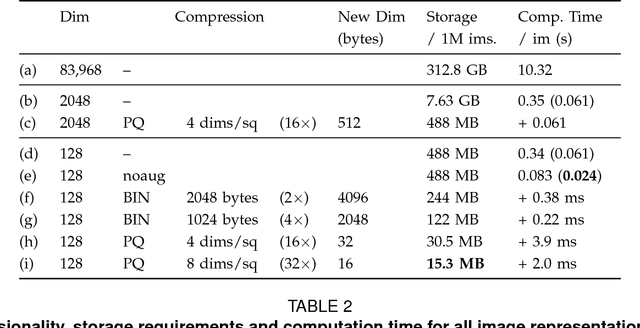
We investigate the gains in precision and speed, that can be obtained by using Convolutional Networks (ConvNets) for on-the-fly retrieval - where classifiers are learnt at run time for a textual query from downloaded images, and used to rank large image or video datasets. We make three contributions: (i) we present an evaluation of state-of-the-art image representations for object category retrieval over standard benchmark datasets containing 1M+ images; (ii) we show that ConvNets can be used to obtain features which are incredibly performant, and yet much lower dimensional than previous state-of-the-art image representations, and that their dimensionality can be reduced further without loss in performance by compression using product quantization or binarization. Consequently, features with the state-of-the-art performance on large-scale datasets of millions of images can fit in the memory of even a commodity GPU card; (iii) we show that an SVM classifier can be learnt within a ConvNet framework on a GPU in parallel with downloading the new training images, allowing for a continuous refinement of the model as more images become available, and simultaneous training and ranking. The outcome is an on-the-fly system that significantly outperforms its predecessors in terms of: precision of retrieval, memory requirements, and speed, facilitating accurate on-the-fly learning and ranking in under a second on a single GPU.
Return of the Devil in the Details: Delving Deep into Convolutional Nets
Nov 05, 2014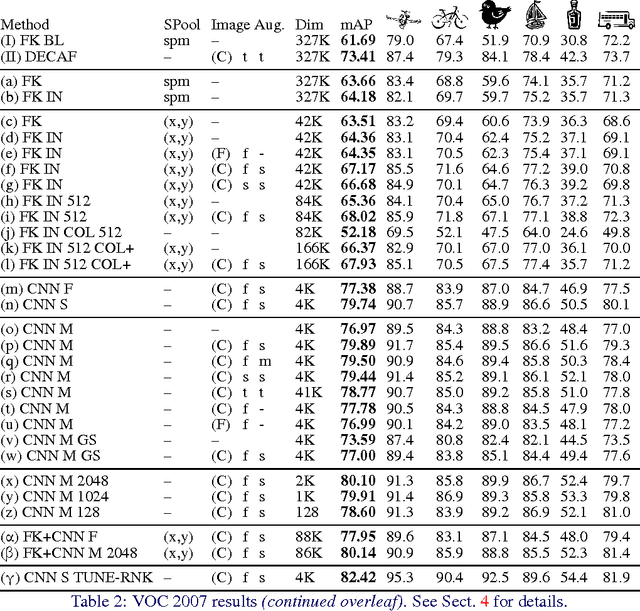
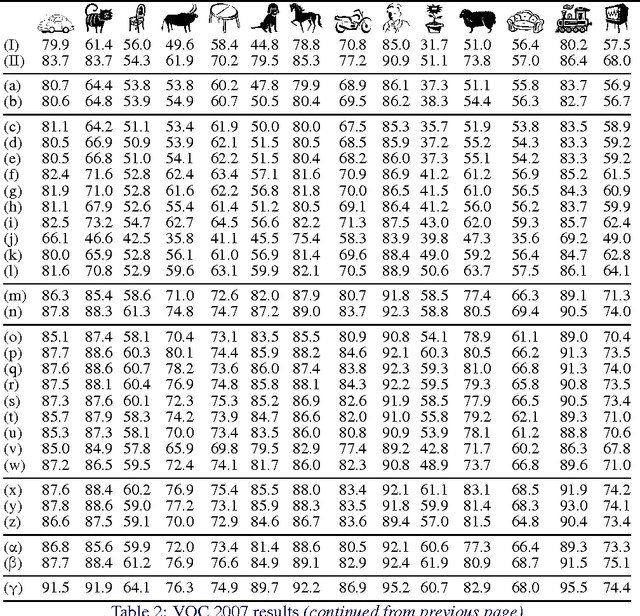
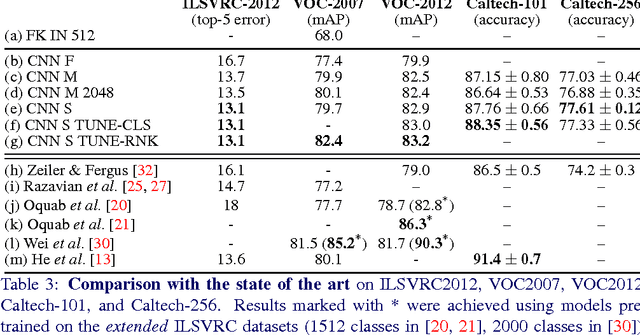
The latest generation of Convolutional Neural Networks (CNN) have achieved impressive results in challenging benchmarks on image recognition and object detection, significantly raising the interest of the community in these methods. Nevertheless, it is still unclear how different CNN methods compare with each other and with previous state-of-the-art shallow representations such as the Bag-of-Visual-Words and the Improved Fisher Vector. This paper conducts a rigorous evaluation of these new techniques, exploring different deep architectures and comparing them on a common ground, identifying and disclosing important implementation details. We identify several useful properties of CNN-based representations, including the fact that the dimensionality of the CNN output layer can be reduced significantly without having an adverse effect on performance. We also identify aspects of deep and shallow methods that can be successfully shared. In particular, we show that the data augmentation techniques commonly applied to CNN-based methods can also be applied to shallow methods, and result in an analogous performance boost. Source code and models to reproduce the experiments in the paper is made publicly available.