 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting SAM 2 for Visual Object Tracking: 1st Place Solution for MMVPR Challenge Multi-Modal Tracking
May 23, 2025We present an effective approach for adapting the Segment Anything Model 2 (SAM2) to the Visual Object Tracking (VOT) task. Our method leverages the powerful pre-trained capabilities of SAM2 and incorporates several key techniques to enhance its performance in VOT applications. By combining SAM2 with our proposed optimizations, we achieved a first place AUC score of 89.4 on the 2024 ICPR Multi-modal Object Tracking challenge, demonstrating the effectiveness of our approach. This paper details our methodology, the specific enhancements made to SAM2, and a comprehensive analysis of our results in the context of VOT solutions along with the multi-modality aspect of the dataset.
EQ-CBM: A Probabilistic Concept Bottleneck with Energy-based Models and Quantized Vectors
Sep 22, 2024



The demand for reliable AI systems has intensified the need for interpretable deep neural networks. Concept bottleneck models (CBMs) have gained attention as an effective approach by leveraging human-understandable concepts to enhance interpretability. However, existing CBMs face challenges due to deterministic concept encoding and reliance on inconsistent concepts, leading to inaccuracies. We propose EQ-CBM, a novel framework that enhances CBMs through probabilistic concept encoding using energy-based models (EBMs) with quantized concept activation vectors (qCAVs). EQ-CBM effectively captures uncertainties, thereby improving prediction reliability and accuracy. By employing qCAVs, our method selects homogeneous vectors during concept encoding, enabling more decisive task performance and facilitating higher levels of human intervention. Empirical results using benchmark datasets demonstrate that our approach outperforms the state-of-the-art in both concept and task accuracy.
SurgT challenge: Benchmark of Soft-Tissue Trackers for Robotic Surgery
Feb 28, 2023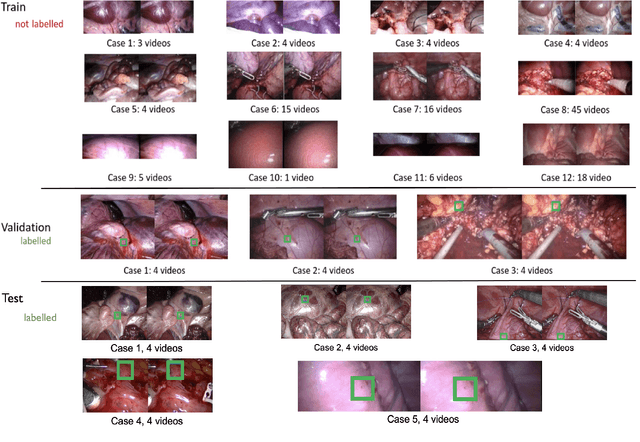
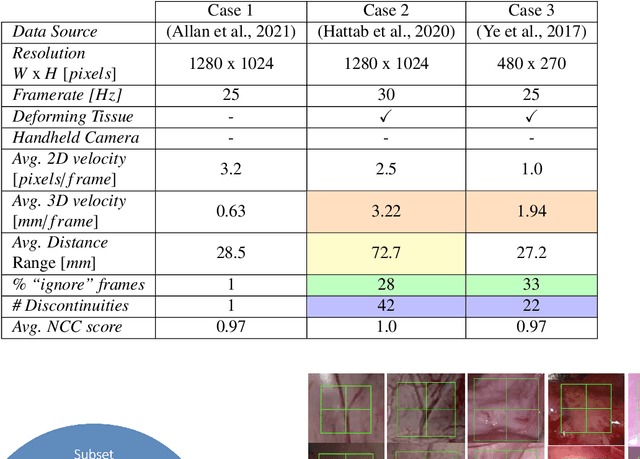
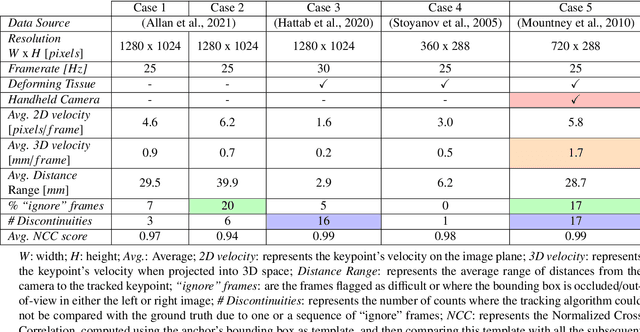
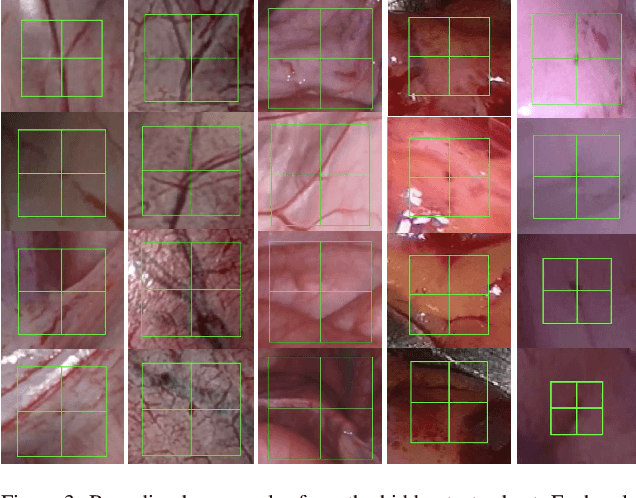
This paper introduces the "SurgT: Surgical Tracking" challenge which was organised in conjunction with the 25th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2022). There were two purposes for the creation of this challenge: (1) the establishment of the first standardised benchmark for the research community to assess soft-tissue trackers; and (2) to encourage the development of unsupervised deep learning methods, given the lack of annotated data in surgery. A dataset of 157 stereo endoscopic videos from 20 clinical cases, along with stereo camera calibration parameters, have been provided. The participants were tasked with the development of algorithms to track a bounding box on stereo endoscopic videos. At the end of the challenge, the developed methods were assessed on a previously hidden test subset. This assessment uses benchmarking metrics that were purposely developed for this challenge and are now available online. The teams were ranked according to their Expected Average Overlap (EAO) score, which is a weighted average of the Intersection over Union (IoU) scores. The performance evaluation study verifies the efficacy of unsupervised deep learning algorithms in tracking soft-tissue. The best-performing method achieved an EAO score of 0.583 in the test subset. The dataset and benchmarking tool created for this challenge have been made publicly available. This challenge is expected to contribute to the development of autonomous robotic surgery and other digital surgical technologies.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
GaitTAKE: Gait Recognition by Temporal Attention and Keypoint-guided Embedding
Jul 12, 2022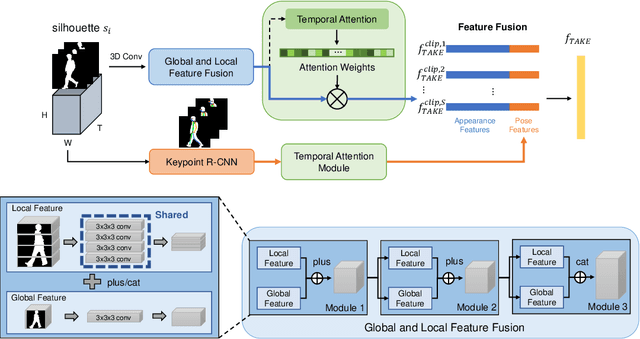
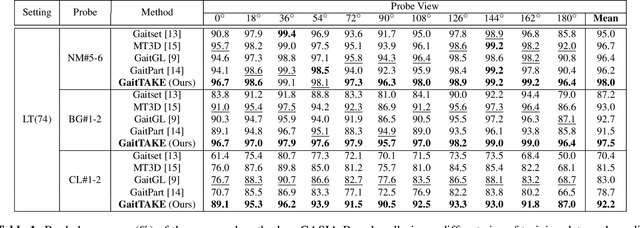

Gait recognition, which refers to the recognition or identification of a person based on their body shape and walking styles, derived from video data captured from a distance, is widely used in crime prevention, forensic identification, and social security. However, to the best of our knowledge, most of the existing methods use appearance, posture and temporal feautures without considering a learned temporal attention mechanism for global and local information fusion. In this paper, we propose a novel gait recognition framework, called Temporal Attention and Keypoint-guided Embedding (GaitTAKE), which effectively fuses temporal-attention-based global and local appearance feature and temporal aggregated human pose feature. Experimental results show that our proposed method achieves a new SOTA in gait recognition with rank-1 accuracy of 98.0% (normal), 97.5% (bag) and 92.2% (coat) on the CASIA-B gait dataset; 90.4% accuracy on the OU-MVLP gait dataset.
Multi-Target Multi-Camera Tracking of Vehicles using Metadata-Aided Re-ID and Trajectory-Based Camera Link Model
May 03, 2021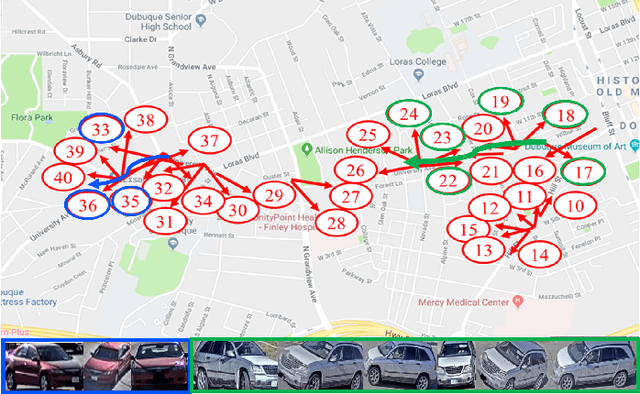

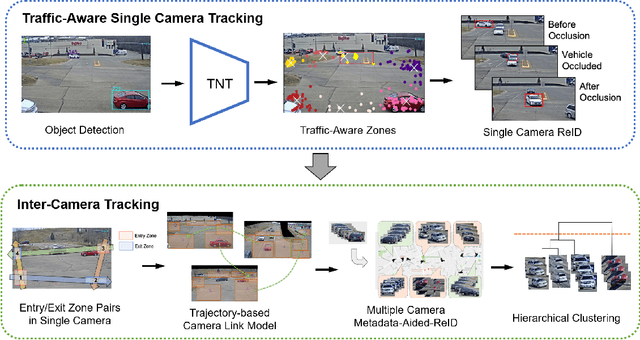
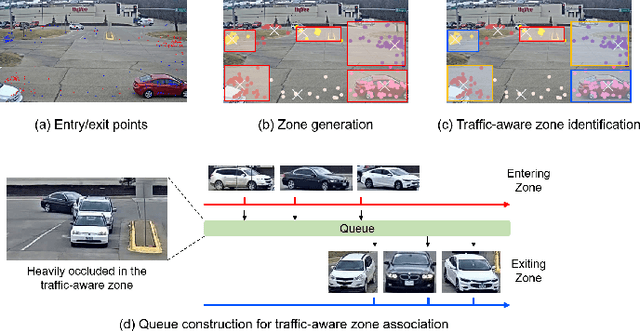
In this paper, we propose a novel framework for multi-target multi-camera tracking (MTMCT) of vehicles based on metadata-aided re-identification (MA-ReID) and the trajectory-based camera link model (TCLM). Given a video sequence and the corresponding frame-by-frame vehicle detections, we first address the isolated tracklets issue from single camera tracking (SCT) by the proposed traffic-aware single-camera tracking (TSCT). Then, after automatically constructing the TCLM, we solve MTMCT by the MA-ReID. The TCLM is generated from camera topological configuration to obtain the spatial and temporal information to improve the performance of MTMCT by reducing the candidate search of ReID. We also use the temporal attention model to create more discriminative embeddings of trajectories from each camera to achieve robust distance measures for vehicle ReID. Moreover, we train a metadata classifier for MTMCT to obtain the metadata feature, which is concatenated with the temporal attention based embeddings. Finally, the TCLM and hierarchical clustering are jointly applied for global ID assignment. The proposed method is evaluated on the CityFlow dataset, achieving IDF1 76.77%, which outperforms the state-of-the-art MTMCT methods.