 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-DiffuB: A Contextualized Sequence-to-Sequence Text Diffusion Model with Meta-Exploration
Oct 17, 2024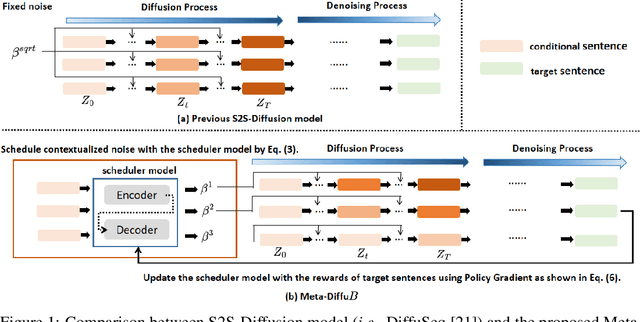

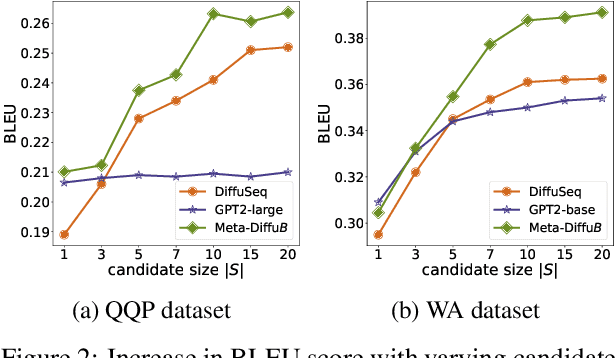
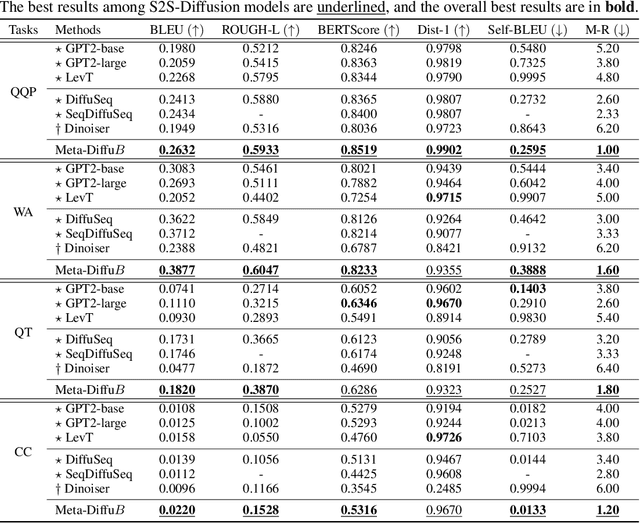
The diffusion model, a new generative modeling paradigm, has achieved significant success in generating images, audio, video, and text. It has been adapted for sequence-to-sequence text generation (Seq2Seq) through DiffuSeq, termed S2S Diffusion. Existing S2S-Diffusion models predominantly rely on fixed or hand-crafted rules to schedule noise during the diffusion and denoising processes. However, these models are limited by non-contextualized noise, which fails to fully consider the characteristics of Seq2Seq tasks. In this paper, we propose the Meta-DiffuB framework - a novel scheduler-exploiter S2S-Diffusion paradigm designed to overcome the limitations of existing S2S-Diffusion models. We employ Meta-Exploration to train an additional scheduler model dedicated to scheduling contextualized noise for each sentence. Our exploiter model, an S2S-Diffusion model, leverages the noise scheduled by our scheduler model for updating and generation. Meta-DiffuB achieves state-of-the-art performance compared to previous S2S-Diffusion models and fine-tuned pre-trained language models (PLMs) across four Seq2Seq benchmark datasets. We further investigate and visualize the impact of Meta-DiffuB's noise scheduling on the generation of sentences with varying difficulties. Additionally, our scheduler model can function as a "plug-and-play" model to enhance DiffuSeq without the need for fine-tuning during the inference stage.
GaitTAKE: Gait Recognition by Temporal Attention and Keypoint-guided Embedding
Jul 12, 2022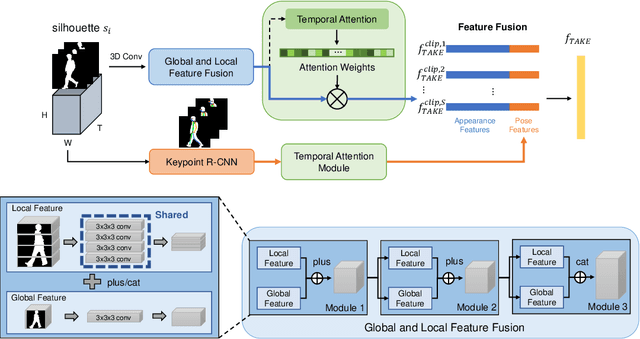
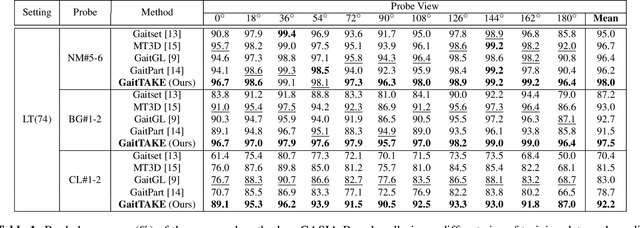

Gait recognition, which refers to the recognition or identification of a person based on their body shape and walking styles, derived from video data captured from a distance, is widely used in crime prevention, forensic identification, and social security. However, to the best of our knowledge, most of the existing methods use appearance, posture and temporal feautures without considering a learned temporal attention mechanism for global and local information fusion. In this paper, we propose a novel gait recognition framework, called Temporal Attention and Keypoint-guided Embedding (GaitTAKE), which effectively fuses temporal-attention-based global and local appearance feature and temporal aggregated human pose feature. Experimental results show that our proposed method achieves a new SOTA in gait recognition with rank-1 accuracy of 98.0% (normal), 97.5% (bag) and 92.2% (coat) on the CASIA-B gait dataset; 90.4% accuracy on the OU-MVLP gait dataset.
Package Theft Detection from Smart Home Security Cameras
May 24, 2022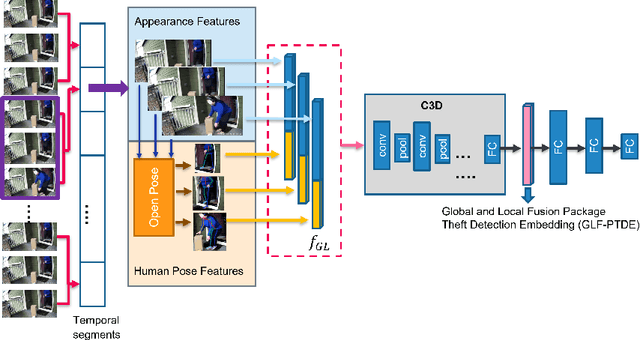

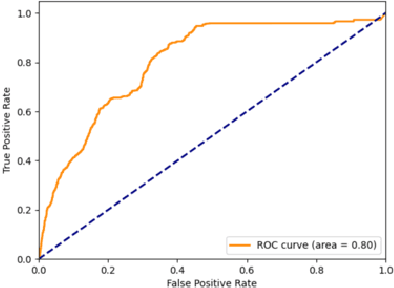

Package theft detection has been a challenging task mainly due to lack of training data and a wide variety of package theft cases in reality. In this paper, we propose a new Global and Local Fusion Package Theft Detection Embedding (GLF-PTDE) framework to generate package theft scores for each segment within a video to fulfill the real-world requirements on package theft detection. Moreover, we construct a novel Package Theft Detection dataset to facilitate the research on this task. Our method achieves 80% AUC performance on the newly proposed dataset, showing the effectiveness of the proposed GLF-PTDE framework and its robustness in different real scenes for package theft detection.
NTIRE 2021 Multi-modal Aerial View Object Classification Challenge
Jul 02, 2021
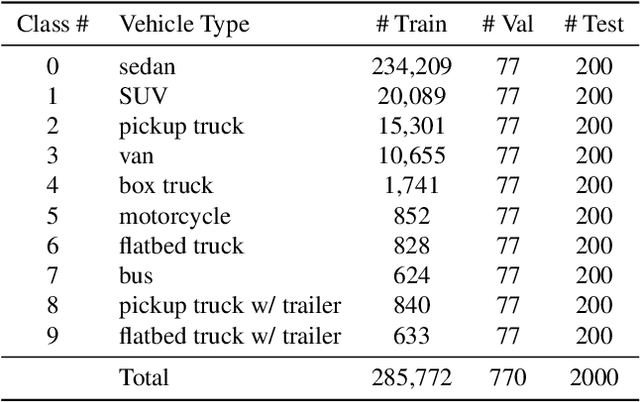
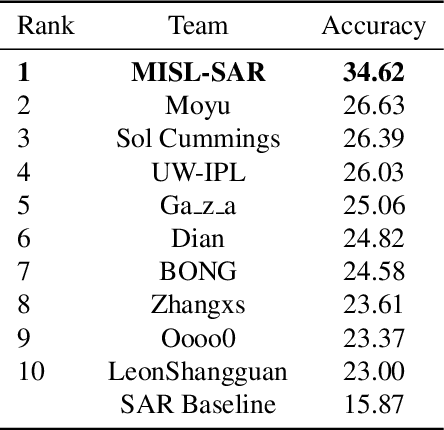
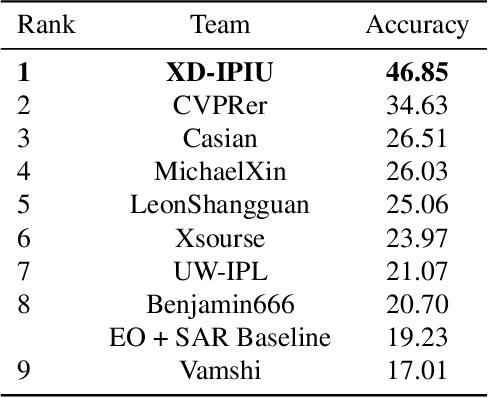
In this paper, we introduce the first Challenge on Multi-modal Aerial View Object Classification (MAVOC) in conjunction with the NTIRE 2021 workshop at CVPR. This challenge is composed of two different tracks using EO andSAR imagery. Both EO and SAR sensors possess different advantages and drawbacks. The purpose of this competition is to analyze how to use both sets of sensory information in complementary ways. We discuss the top methods submitted for this competition and evaluate their results on our blind test set. Our challenge results show significant improvement of more than 15% accuracy from our current baselines for each track of the competition
* 10 pages, 1 figure. Conference on Computer Vision and Pattern Recognition
Rethinking of Radar's Role: A Camera-Radar Dataset and Systematic Annotator via Coordinate Alignment
May 11, 2021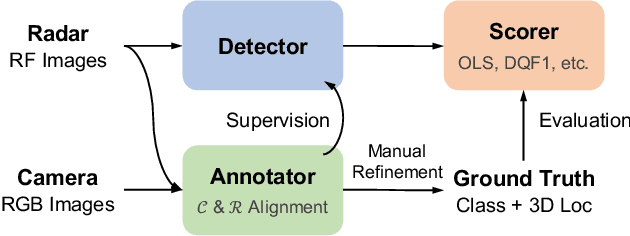
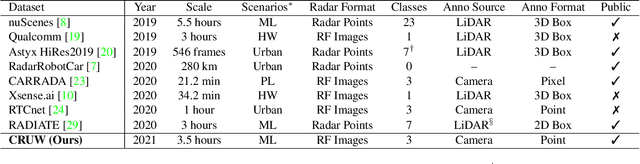
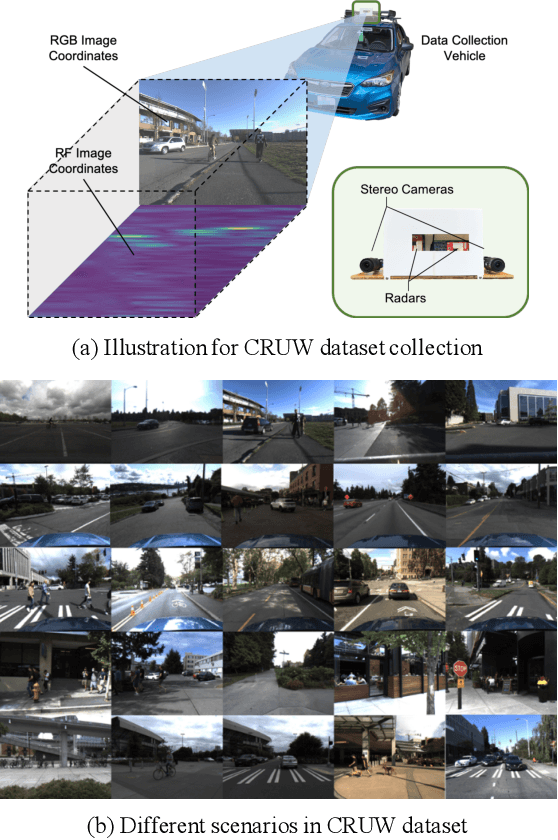
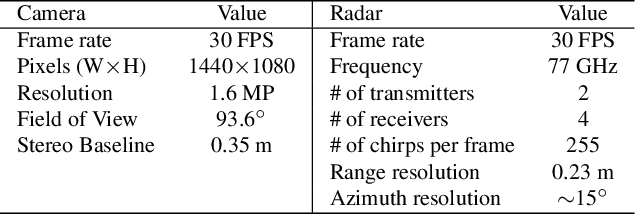
Radar has long been a common sensor on autonomous vehicles for obstacle ranging and speed estimation. However, as a robust sensor to all-weather conditions, radar's capability has not been well-exploited, compared with camera or LiDAR. Instead of just serving as a supplementary sensor, radar's rich information hidden in the radio frequencies can potentially provide useful clues to achieve more complicated tasks, like object classification and detection. In this paper, we propose a new dataset, named CRUW, with a systematic annotator and performance evaluation system to address the radar object detection (ROD) task, which aims to classify and localize the objects in 3D purely from radar's radio frequency (RF) images. To the best of our knowledge, CRUW is the first public large-scale dataset with a systematic annotation and evaluation system, which involves camera RGB images and radar RF images, collected in various driving scenarios.
Multi-Target Multi-Camera Tracking of Vehicles using Metadata-Aided Re-ID and Trajectory-Based Camera Link Model
May 03, 2021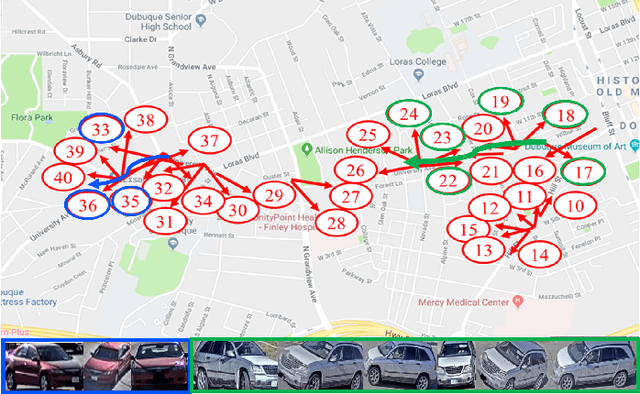

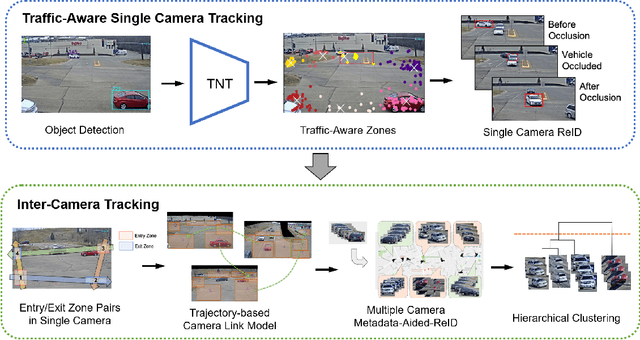
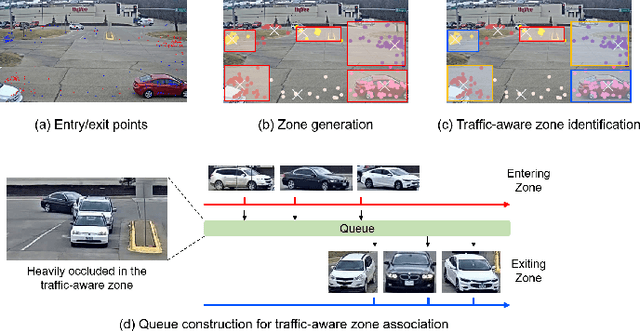
In this paper, we propose a novel framework for multi-target multi-camera tracking (MTMCT) of vehicles based on metadata-aided re-identification (MA-ReID) and the trajectory-based camera link model (TCLM). Given a video sequence and the corresponding frame-by-frame vehicle detections, we first address the isolated tracklets issue from single camera tracking (SCT) by the proposed traffic-aware single-camera tracking (TSCT). Then, after automatically constructing the TCLM, we solve MTMCT by the MA-ReID. The TCLM is generated from camera topological configuration to obtain the spatial and temporal information to improve the performance of MTMCT by reducing the candidate search of ReID. We also use the temporal attention model to create more discriminative embeddings of trajectories from each camera to achieve robust distance measures for vehicle ReID. Moreover, we train a metadata classifier for MTMCT to obtain the metadata feature, which is concatenated with the temporal attention based embeddings. Finally, the TCLM and hierarchical clustering are jointly applied for global ID assignment. The proposed method is evaluated on the CityFlow dataset, achieving IDF1 76.77%, which outperforms the state-of-the-art MTMCT methods.
Traffic-Aware Multi-Camera Tracking of Vehicles Based on ReID and Camera Link Model
Aug 30, 2020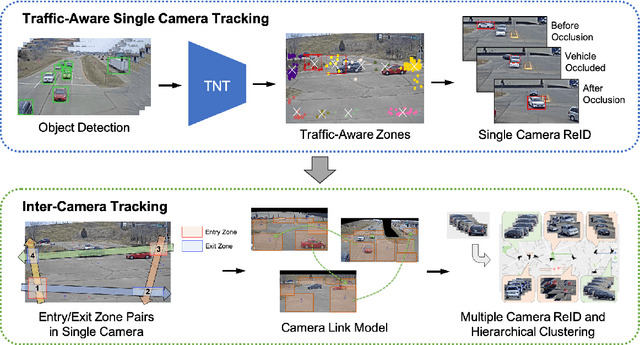
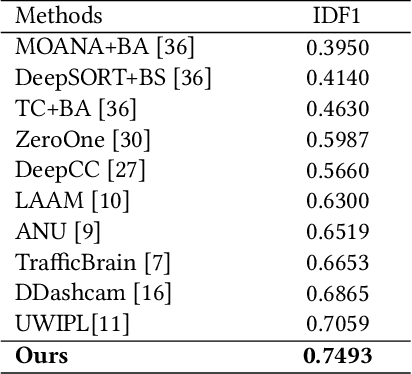
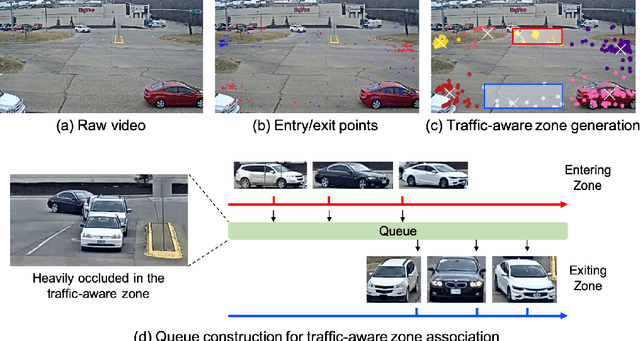
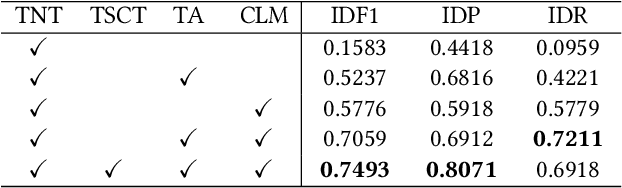
Multi-target multi-camera tracking (MTMCT), i.e., tracking multiple targets across multiple cameras, is a crucial technique for smart city applications. In this paper, we propose an effective and reliable MTMCT framework for vehicles, which consists of a traffic-aware single camera tracking (TSCT) algorithm, a trajectory-based camera link model (CLM) for vehicle re-identification (ReID), and a hierarchical clustering algorithm to obtain the cross camera vehicle trajectories. First, the TSCT, which jointly considers vehicle appearance, geometric features, and some common traffic scenarios, is proposed to track the vehicles in each camera separately. Second, the trajectory-based CLM is adopted to facilitate the relationship between each pair of adjacently connected cameras and add spatio-temporal constraints for the subsequent vehicle ReID with temporal attention. Third, the hierarchical clustering algorithm is used to merge the vehicle trajectories among all the cameras to obtain the final MTMCT results. Our proposed MTMCT is evaluated on the CityFlow dataset and achieves a new state-of-the-art performance with IDF1 of 74.93%.
IA-MOT: Instance-Aware Multi-Object Tracking with Motion Consistency
Jun 24, 2020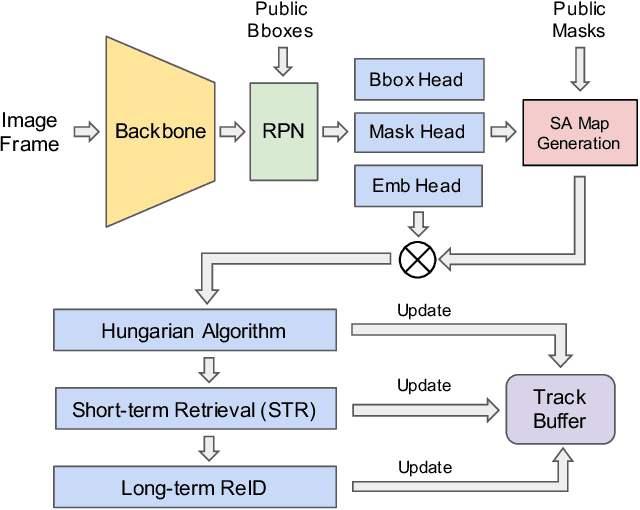
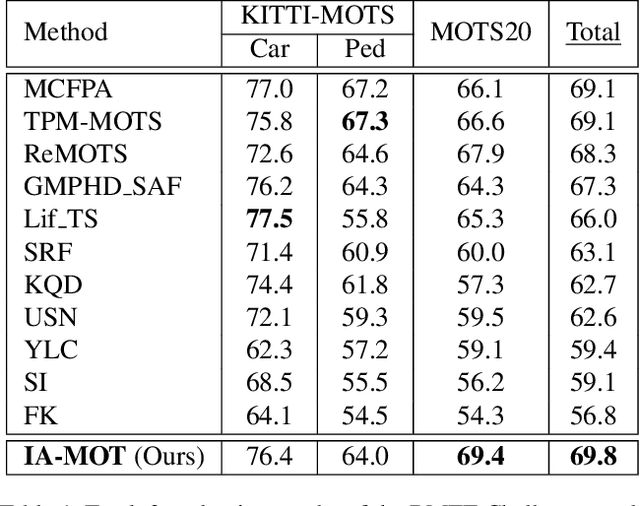

Multiple object tracking (MOT) is a crucial task in computer vision society. However, most tracking-by-detection MOT methods, with available detected bounding boxes, cannot effectively handle static, slow-moving and fast-moving camera scenarios simultaneously due to ego-motion and frequent occlusion. In this work, we propose a novel tracking framework, called "instance-aware MOT" (IA-MOT), that can track multiple objects in either static or moving cameras by jointly considering the instance-level features and object motions. First, robust appearance features are extracted from a variant of Mask R-CNN detector with an additional embedding head, by sending the given detections as the region proposals. Meanwhile, the spatial attention, which focuses on the foreground within the bounding boxes, is generated from the given instance masks and applied to the extracted embedding features. In the tracking stage, object instance masks are aligned by feature similarity and motion consistency using the Hungarian association algorithm. Moreover, object re-identification (ReID) is incorporated to recover ID switches caused by long-term occlusion or missing detection. Overall, when evaluated on the MOTS20 and KITTI-MOTS dataset, our proposed method won the first place in Track 3 of the BMTT Challenge in CVPR2020 workshops.