 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-DiffuB: A Contextualized Sequence-to-Sequence Text Diffusion Model with Meta-Exploration
Oct 17, 2024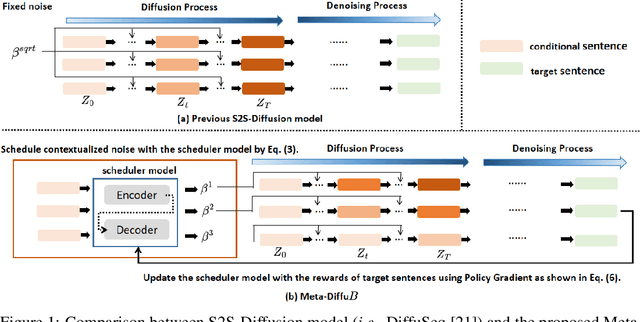

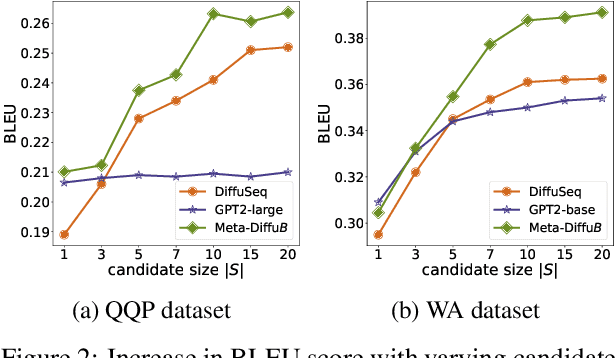
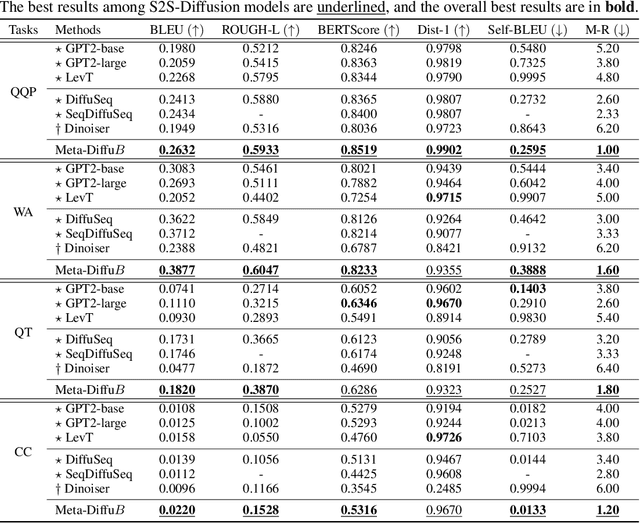
The diffusion model, a new generative modeling paradigm, has achieved significant success in generating images, audio, video, and text. It has been adapted for sequence-to-sequence text generation (Seq2Seq) through DiffuSeq, termed S2S Diffusion. Existing S2S-Diffusion models predominantly rely on fixed or hand-crafted rules to schedule noise during the diffusion and denoising processes. However, these models are limited by non-contextualized noise, which fails to fully consider the characteristics of Seq2Seq tasks. In this paper, we propose the Meta-DiffuB framework - a novel scheduler-exploiter S2S-Diffusion paradigm designed to overcome the limitations of existing S2S-Diffusion models. We employ Meta-Exploration to train an additional scheduler model dedicated to scheduling contextualized noise for each sentence. Our exploiter model, an S2S-Diffusion model, leverages the noise scheduled by our scheduler model for updating and generation. Meta-DiffuB achieves state-of-the-art performance compared to previous S2S-Diffusion models and fine-tuned pre-trained language models (PLMs) across four Seq2Seq benchmark datasets. We further investigate and visualize the impact of Meta-DiffuB's noise scheduling on the generation of sentences with varying difficulties. Additionally, our scheduler model can function as a "plug-and-play" model to enhance DiffuSeq without the need for fine-tuning during the inference stage.