 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlausibility Is Not Prediction: Contrastive Evidence for LLM-Based Cellular Perturbation Reasoning
May 31, 2026Perturbation experiments are central to understanding cellular mechanisms, but remain costly and sparse, motivating prediction of gene expression responses for unobserved conditions. A promising recent direction leverages large language models (LLMs) as "virtual cell" simulators-using stepwise, knowledge-grounded mechanistic reasoning to infer differential expression-pointing toward an interpretable, knowledge-driven paradigm that transcends purely data-driven approaches. However, we find that plausibility is not prediction: despite producing biologically plausible explanations, these methods fail to capture perturbation-specific effects: systematically overestimating differential expression, often underperforming a simple gene-frequency baseline in aggregate evaluations, and collapsing to chance-level performance at the per-gene level. This reveals a reliance on intrinsic gene response tendencies rather than true perturbation reasoning. We trace this failure to how evidence is presented: existing methods evaluate perturbation-gene pairs in isolation, without exposing how related perturbations differ in their effects on the same gene. To address this limitation, we introduce CORE (Contrastive Organization of Relational Evidence), which reframes prediction as a comparison task by organizing evidence into positive and negative outcomes from related perturbations. Using a biomedical knowledge graph for evidence retrieval, CORE improves calibration and substantially boosts perturbation-specific prediction in both LLM-based and non-LLM settings: for example, on drug-perturbation data, CORE-Reasoning improves Qwen3.5-9B aggregate metrics by up to 28.6%, while on generic perturbation data, CORE-Voting raises macro-per-gene AUROC from chance to 0.703 in average across four cell lines. This highlights contrastive evidence organization as essential to reliable LLM-based perturbation reasoning
A Unified Framework for the Evaluation of LLM Agentic Capabilities
May 27, 2026As LLMs are increasingly deployed as agents, reliable assessment of their agentic capabilities has become essential. However, reported benchmark scores often jointly reflect model capability and the implementation choices each benchmark is packaged with, making cross-benchmark results difficult to interpret as clean measurements of the underlying model. In this work, we present a unified framework for the fair evaluation of LLM agentic capabilities. Driven by a unified configuration system, the framework integrates diverse benchmarks into a standardized instruction--tool--environment format, executes agents through a fixed ReAct-style architecture within a controllable sandbox, and provides an optional offline setting that replaces volatile live environments with curated snapshots, so that framework effects and environment effects can be analyzed separately. Building on this, we unify the evaluation methodology under each benchmark's original task-success criteria, while introducing unified metrics for resource consumption and a taxonomy for decision- and execution-level failure attribution. Within this framework, we adapt 7 widely used benchmarks spanning 24 domains across single-agent, multi-agent, and safety-critical scenarios, and conduct a large-scale empirical analysis over 400K rollouts and 5B tokens on 15 models. The results show that scaffold choice and environmental volatility materially shift benchmark outcomes in both directions, allowing our framework to disentangle intrinsic LLM capabilities from framework- and environment-induced artifacts. We further demonstrate its extensibility as a secure testbed for safety-critical domains. Codes and benchmarks at are available at https://github.com/whfeLingYu/A-Unified-Framework-for-the-Evaluation-of-LLM-Agentic-Capabilities, https://huggingface.co/AgentFramework/Unified_Farmework.
On the (Generative) Linear Sketching Problem
Mar 15, 2026Sketch techniques have been extensively studied in recent years and are especially well-suited to data streaming scenarios, where the sketch summary is updated quickly and compactly. However, it is challenging to recover the current state from these summaries in a way that is accurate, fast, and real. In this paper, we seek a solution that reconciles this tension, aiming for near-perfect recovery with lightweight computational procedures. Focusing on linear sketching problems of the form $\boldsymbolΦf \rightarrow f$, our study proceeds in three stages. First, we dissect existing techniques and show the root cause of the sketching dilemma: an orthogonal information loss. Second, we examine how generative priors can be leveraged to bridge the information gap. Third, we propose FLORE, a novel generative sketching framework that embraces these analyses to achieve the best of all worlds. More importantly, FLORE can be trained without access to ground-truth data. Comprehensive evaluations demonstrate FLORE's ability to provide high-quality recovery, and support summary with low computing overhead, outperforming previous methods by up to 1000 times in error reduction and 100 times in processing speed compared to learning-based solutions.
PerturbDiff: Functional Diffusion for Single-Cell Perturbation Modeling
Feb 23, 2026Building Virtual Cells that can accurately simulate cellular responses to perturbations is a long-standing goal in systems biology. A fundamental challenge is that high-throughput single-cell sequencing is destructive: the same cell cannot be observed both before and after a perturbation. Thus, perturbation prediction requires mapping unpaired control and perturbed populations. Existing models address this by learning maps between distributions, but typically assume a single fixed response distribution when conditioned on observed cellular context (e.g., cell type) and the perturbation type. In reality, responses vary systematically due to unobservable latent factors such as microenvironmental fluctuations and complex batch effects, forming a manifold of possible distributions for the same observed conditions. To account for this variability, we introduce PerturbDiff, which shifts modeling from individual cells to entire distributions. By embedding distributions as points in a Hilbert space, we define a diffusion-based generative process operating directly over probability distributions. This allows PerturbDiff to capture population-level response shifts across hidden factors. Benchmarks on established datasets show that PerturbDiff achieves state-of-the-art performance in single-cell response prediction and generalizes substantially better to unseen perturbations. See our project page (https://katarinayuan.github.io/PerturbDiff-ProjectPage/), where code and data will be made publicly available (https://github.com/DeepGraphLearning/PerturbDiff).
Divide, Harmonize, Then Conquer It: Shooting Multi-Commodity Flow Problems with Multimodal Language Models
Feb 11, 2026The multi-commodity flow (MCF) problem is a fundamental topic in network flow and combinatorial optimization, with broad applications in transportation, communication, and logistics, etc. Nowadays, the rapid expansion of allocation systems has posed challenges for existing optimization engines in balancing optimality and tractability. In this paper, we present Pram, the first ML-based method that leverages the reasoning power of multimodal language models (MLMs) for addressing the trade-off dilemma -- a great need of service providers. As part of our proposal, Pram (i) quickly computes high-quality allocations by dividing the original problem into local subproblems, which are then resolved by an MLM-powered "agent", and (ii) ensures global consistency by harmonizing these subproblems via a multi-agent reinforcement learning algorithm. Theoretically, we show that Pram, which learns to perform gradient descent in context, provably converges to the optimum within the family of MCF problems. Empirically, on real-world datasets and public topologies, Pram achieves performance comparable to, and in some cases even surpassing, linear programming solvers (very close to the optimal solution), and substantially lower runtimes (1 to 2 orders of magnitude faster). Moreover, Pram exhibits strong robustness (<10\% performance degradation under link failures or flow bursts), demonstrating MLM's generalization ability to unforeseen events. Pram is objective-agnostic and seamlessly integrates with mainstream allocation systems, providing a practical and scalable solution for future networks.
Learning-based Sketches for Frequency Estimation in Data Streams without Ground Truth
Dec 04, 2024Estimating the frequency of items on the high-volume, fast data stream has been extensively studied in many areas, such as database and network measurement. Traditional sketch algorithms only allow to give very rough estimates with limited memory cost, whereas some learning-augmented algorithms have been proposed recently, their offline framework requires actual frequencies that are challenging to access in general for training, and speed is too slow for real-time processing, despite the still coarse-grained accuracy. To this end, we propose a more practical learning-based estimation framework namely UCL-sketch, by following the line of equation-based sketch to estimate per-key frequencies. In a nutshell, there are two key techniques: online training via equivalent learning without ground truth, and highly scalable architecture with logical estimation buckets. We implemented experiments on both real-world and synthetic datasets. The results demonstrate that our method greatly outperforms existing state-of-the-art sketches regarding per-key accuracy and distribution, while preserving resource efficiency. Our code is attached in the supplementary material, and will be made publicly available at https://github.com/Y-debug-sys/UCL-sketch.
Diffusion Models Meet Network Management: Improving Traffic Matrix Analysis with Diffusion-based Approach
Nov 29, 2024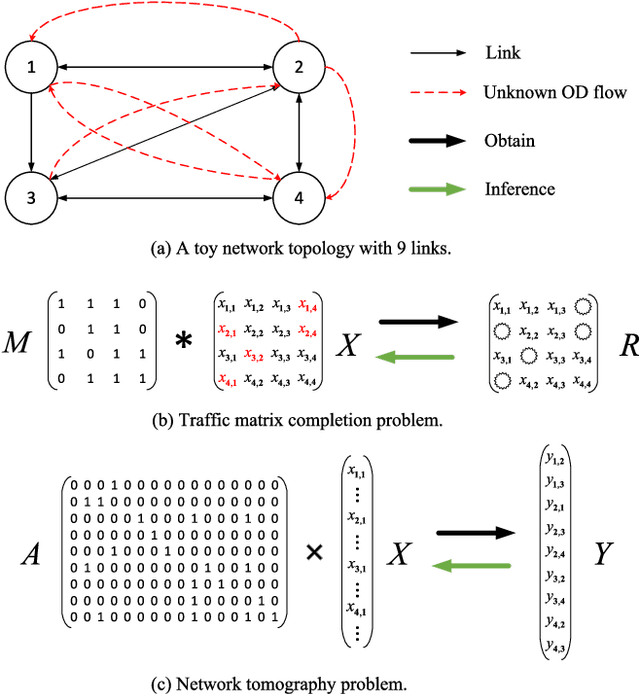
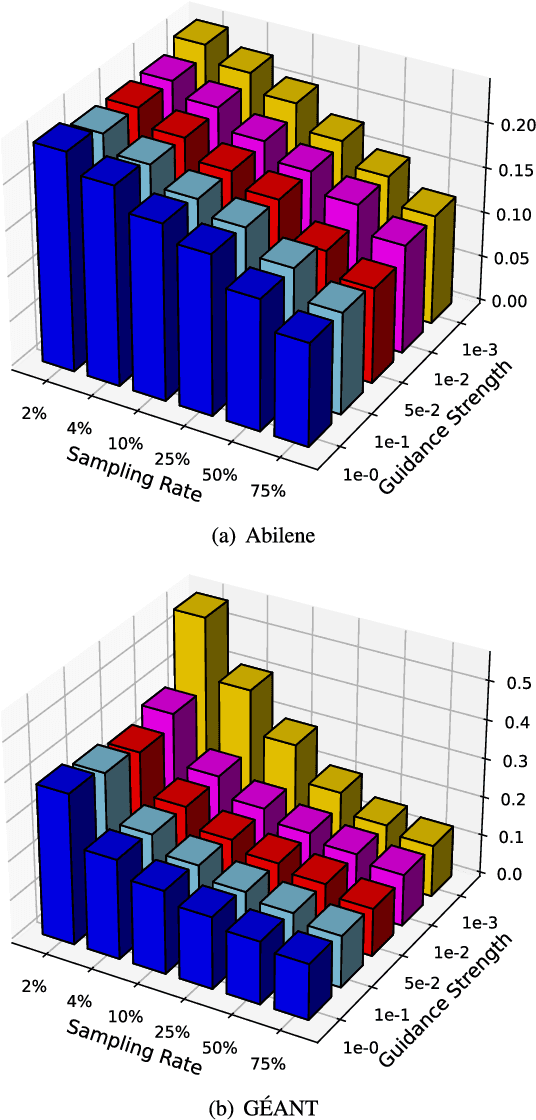
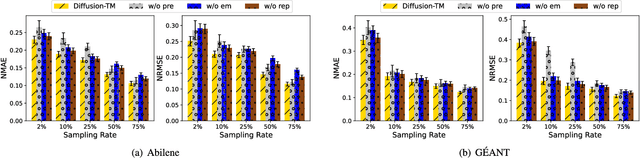
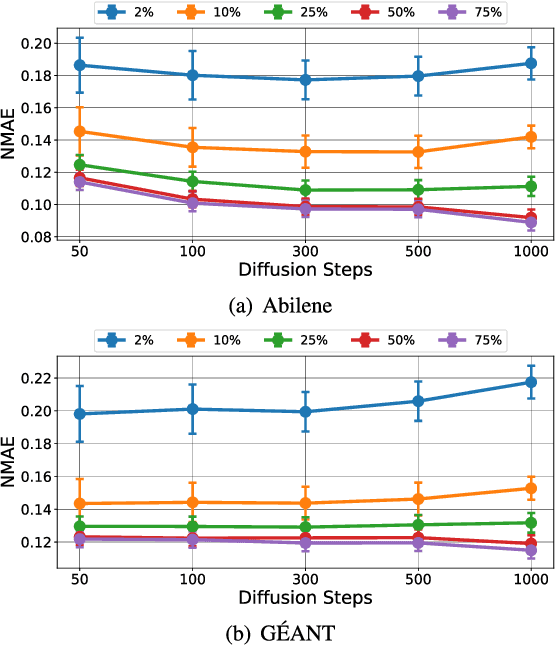
Due to network operation and maintenance relying heavily on network traffic monitoring, traffic matrix analysis has been one of the most crucial issues for network management related tasks. However, it is challenging to reliably obtain the precise measurement in computer networks because of the high measurement cost, and the unavoidable transmission loss. Although some methods proposed in recent years allowed estimating network traffic from partial flow-level or link-level measurements, they often perform poorly for traffic matrix estimation nowadays. Despite strong assumptions like low-rank structure and the prior distribution, existing techniques are usually task-specific and tend to be significantly worse as modern network communication is extremely complicated and dynamic. To address the dilemma, this paper proposed a diffusion-based traffic matrix analysis framework named Diffusion-TM, which leverages problem-agnostic diffusion to notably elevate the estimation performance in both traffic distribution and accuracy. The novel framework not only takes advantage of the powerful generative ability of diffusion models to produce realistic network traffic, but also leverages the denoising process to unbiasedly estimate all end-to-end traffic in a plug-and-play manner under theoretical guarantee. Moreover, taking into account that compiling an intact traffic dataset is usually infeasible, we also propose a two-stage training scheme to make our framework be insensitive to missing values in the dataset. With extensive experiments with real-world datasets, we illustrate the effectiveness of Diffusion-TM on several tasks. Moreover, the results also demonstrate that our method can obtain promising results even with $5\%$ known values left in the datasets.
Traffic Matrix Estimation based on Denoising Diffusion Probabilistic Model
Oct 21, 2024



The traffic matrix estimation (TME) problem has been widely researched for decades of years. Recent progresses in deep generative models offer new opportunities to tackle TME problems in a more advanced way. In this paper, we leverage the powerful ability of denoising diffusion probabilistic models (DDPMs) on distribution learning, and for the first time adopt DDPM to address the TME problem. To ensure a good performance of DDPM on learning the distributions of TMs, we design a preprocessing module to reduce the dimensions of TMs while keeping the data variety of each OD flow. To improve the estimation accuracy, we parameterize the noise factors in DDPM and transform the TME problem into a gradient-descent optimization problem. Finally, we compared our method with the state-of-the-art TME methods using two real-world TM datasets, the experimental results strongly demonstrate the superiority of our method on both TM synthesis and TM estimation.
Cell-ontology guided transcriptome foundation model
Aug 22, 2024



Transcriptome foundation models TFMs hold great promises of deciphering the transcriptomic language that dictate diverse cell functions by self-supervised learning on large-scale single-cell gene expression data, and ultimately unraveling the complex mechanisms of human diseases. However, current TFMs treat cells as independent samples and ignore the taxonomic relationships between cell types, which are available in cell ontology graphs. We argue that effectively leveraging this ontology information during the TFM pre-training can improve learning biologically meaningful gene co-expression patterns while preserving TFM as a general purpose foundation model for downstream zero-shot and fine-tuning tasks. To this end, we present \textbf{s}ingle \textbf{c}ell, \textbf{Cell}-\textbf{o}ntology guided TFM scCello. We introduce cell-type coherence loss and ontology alignment loss, which are minimized along with the masked gene expression prediction loss during the pre-training. The novel loss component guide scCello to learn the cell-type-specific representation and the structural relation between cell types from the cell ontology graph, respectively. We pre-trained scCello on 22 million cells from CellxGene database leveraging their cell-type labels mapped to the cell ontology graph from Open Biological and Biomedical Ontology Foundry. Our TFM demonstrates competitive generalization and transferability performance over the existing TFMs on biologically important tasks including identifying novel cell types of unseen cells, prediction of cell-type-specific marker genes, and cancer drug responses.
Diffusion-TS: Interpretable Diffusion for General Time Series Generation
Mar 14, 2024Denoising diffusion probabilistic models (DDPMs) are becoming the leading paradigm for generative models. It has recently shown breakthroughs in audio synthesis, time series imputation and forecasting. In this paper, we propose Diffusion-TS, a novel diffusion-based framework that generates multivariate time series samples of high quality by using an encoder-decoder transformer with disentangled temporal representations, in which the decomposition technique guides Diffusion-TS to capture the semantic meaning of time series while transformers mine detailed sequential information from the noisy model input. Different from existing diffusion-based approaches, we train the model to directly reconstruct the sample instead of the noise in each diffusion step, combining a Fourier-based loss term. Diffusion-TS is expected to generate time series satisfying both interpretablity and realness. In addition, it is shown that the proposed Diffusion-TS can be easily extended to conditional generation tasks, such as forecasting and imputation, without any model changes. This also motivates us to further explore the performance of Diffusion-TS under irregular settings. Finally, through qualitative and quantitative experiments, results show that Diffusion-TS achieves the state-of-the-art results on various realistic analyses of time series.