 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-World Deepfake Attribution via Confidence-Aware Asymmetric Learning
Dec 14, 2025The proliferation of synthetic facial imagery has intensified the need for robust Open-World DeepFake Attribution (OW-DFA), which aims to attribute both known and unknown forgeries using labeled data for known types and unlabeled data containing a mixture of known and novel types. However, existing OW-DFA methods face two critical limitations: 1) A confidence skew that leads to unreliable pseudo-labels for novel forgeries, resulting in biased training. 2) An unrealistic assumption that the number of unknown forgery types is known *a priori*. To address these challenges, we propose a Confidence-Aware Asymmetric Learning (CAL) framework, which adaptively balances model confidence across known and novel forgery types. CAL mainly consists of two components: Confidence-Aware Consistency Regularization (CCR) and Asymmetric Confidence Reinforcement (ACR). CCR mitigates pseudo-label bias by dynamically scaling sample losses based on normalized confidence, gradually shifting the training focus from high- to low-confidence samples. ACR complements this by separately calibrating confidence for known and novel classes through selective learning on high-confidence samples, guided by their confidence gap. Together, CCR and ACR form a mutually reinforcing loop that significantly improves the model's OW-DFA performance. Moreover, we introduce a Dynamic Prototype Pruning (DPP) strategy that automatically estimates the number of novel forgery types in a coarse-to-fine manner, removing the need for unrealistic prior assumptions and enhancing the scalability of our methods to real-world OW-DFA scenarios. Extensive experiments on the standard OW-DFA benchmark and a newly extended benchmark incorporating advanced manipulations demonstrate that CAL consistently outperforms previous methods, achieving new state-of-the-art performance on both known and novel forgery attribution.
WeatherEdit: Controllable Weather Editing with 4D Gaussian Field
May 26, 2025In this work, we present WeatherEdit, a novel weather editing pipeline for generating realistic weather effects with controllable types and severity in 3D scenes. Our approach is structured into two key components: weather background editing and weather particle construction. For weather background editing, we introduce an all-in-one adapter that integrates multiple weather styles into a single pretrained diffusion model, enabling the generation of diverse weather effects in 2D image backgrounds. During inference, we design a Temporal-View (TV-) attention mechanism that follows a specific order to aggregate temporal and spatial information, ensuring consistent editing across multi-frame and multi-view images. To construct the weather particles, we first reconstruct a 3D scene using the edited images and then introduce a dynamic 4D Gaussian field to generate snowflakes, raindrops and fog in the scene. The attributes and dynamics of these particles are precisely controlled through physical-based modelling and simulation, ensuring realistic weather representation and flexible severity adjustments. Finally, we integrate the 4D Gaussian field with the 3D scene to render consistent and highly realistic weather effects. Experiments on multiple driving datasets demonstrate that WeatherEdit can generate diverse weather effects with controllable condition severity, highlighting its potential for autonomous driving simulation in adverse weather. See project page: https://jumponthemoon.github.io/w-edit
WeatherGS: 3D Scene Reconstruction in Adverse Weather Conditions via Gaussian Splatting
Dec 25, 2024



3D Gaussian Splatting (3DGS) has gained significant attention for 3D scene reconstruction, but still suffers from complex outdoor environments, especially under adverse weather. This is because 3DGS treats the artifacts caused by adverse weather as part of the scene and will directly reconstruct them, largely reducing the clarity of the reconstructed scene. To address this challenge, we propose WeatherGS, a 3DGS-based framework for reconstructing clear scenes from multi-view images under different weather conditions. Specifically, we explicitly categorize the multi-weather artifacts into the dense particles and lens occlusions that have very different characters, in which the former are caused by snowflakes and raindrops in the air, and the latter are raised by the precipitation on the camera lens. In light of this, we propose a dense-to-sparse preprocess strategy, which sequentially removes the dense particles by an Atmospheric Effect Filter (AEF) and then extracts the relatively sparse occlusion masks with a Lens Effect Detector (LED). Finally, we train a set of 3D Gaussians by the processed images and generated masks for excluding occluded areas, and accurately recover the underlying clear scene by Gaussian splatting. We conduct a diverse and challenging benchmark to facilitate the evaluation of 3D reconstruction under complex weather scenarios. Extensive experiments on this benchmark demonstrate that our WeatherGS consistently produces high-quality, clean scenes across various weather scenarios, outperforming existing state-of-the-art methods. See project page:https://jumponthemoon.github.io/weather-gs.
Diffusion Models Meet Network Management: Improving Traffic Matrix Analysis with Diffusion-based Approach
Nov 29, 2024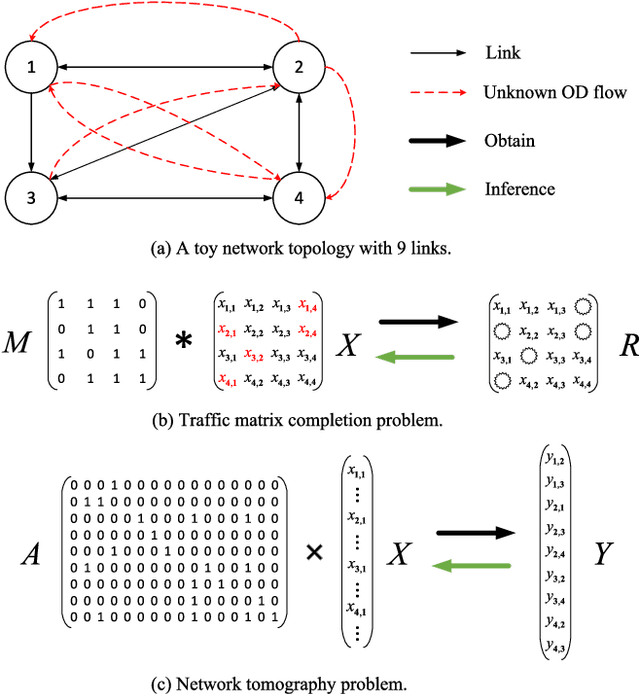
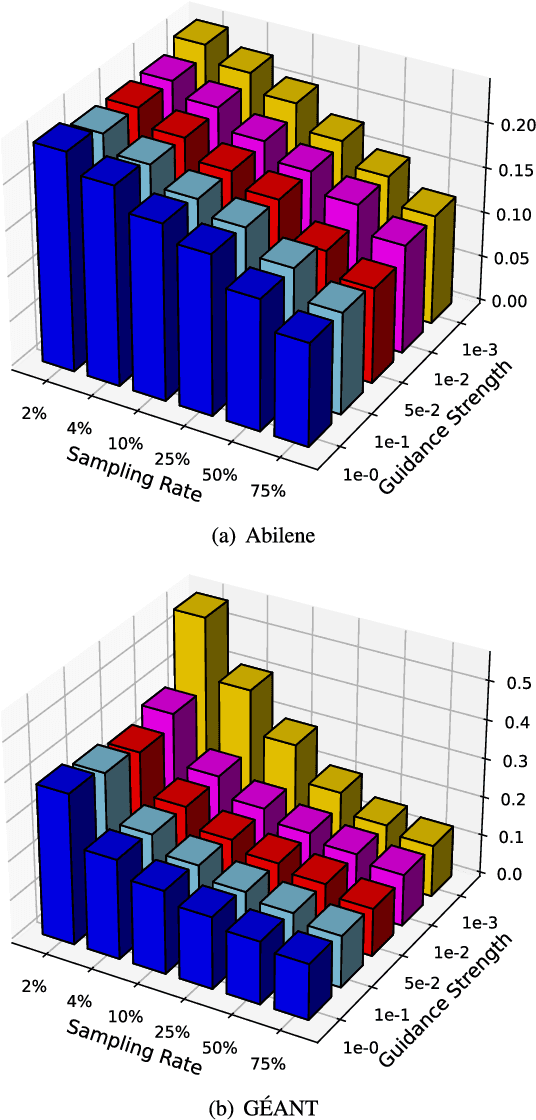
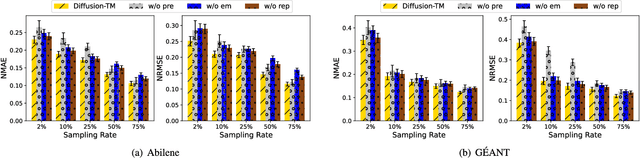
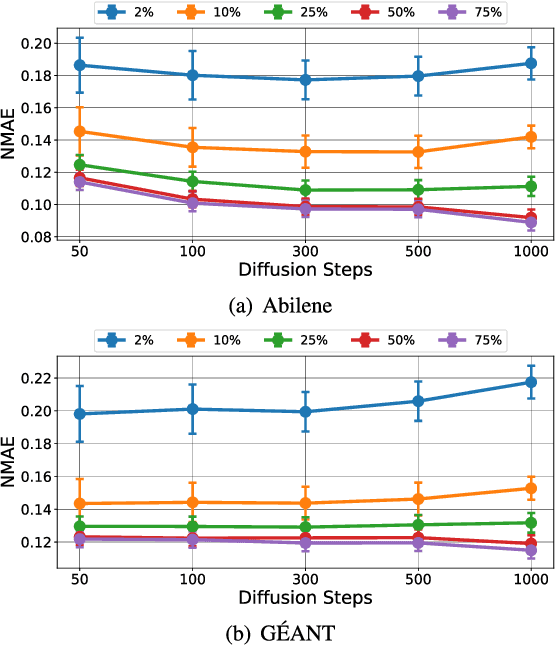
Due to network operation and maintenance relying heavily on network traffic monitoring, traffic matrix analysis has been one of the most crucial issues for network management related tasks. However, it is challenging to reliably obtain the precise measurement in computer networks because of the high measurement cost, and the unavoidable transmission loss. Although some methods proposed in recent years allowed estimating network traffic from partial flow-level or link-level measurements, they often perform poorly for traffic matrix estimation nowadays. Despite strong assumptions like low-rank structure and the prior distribution, existing techniques are usually task-specific and tend to be significantly worse as modern network communication is extremely complicated and dynamic. To address the dilemma, this paper proposed a diffusion-based traffic matrix analysis framework named Diffusion-TM, which leverages problem-agnostic diffusion to notably elevate the estimation performance in both traffic distribution and accuracy. The novel framework not only takes advantage of the powerful generative ability of diffusion models to produce realistic network traffic, but also leverages the denoising process to unbiasedly estimate all end-to-end traffic in a plug-and-play manner under theoretical guarantee. Moreover, taking into account that compiling an intact traffic dataset is usually infeasible, we also propose a two-stage training scheme to make our framework be insensitive to missing values in the dataset. With extensive experiments with real-world datasets, we illustrate the effectiveness of Diffusion-TM on several tasks. Moreover, the results also demonstrate that our method can obtain promising results even with $5\%$ known values left in the datasets.
Generative AI Enabled Matching for 6G Multiple Access
Oct 29, 2024In wireless networks, applying deep learning models to solve matching problems between different entities has become a mainstream and effective approach. However, the complex network topology in 6G multiple access presents significant challenges for the real-time performance and stability of matching generation. Generative artificial intelligence (GenAI) has demonstrated strong capabilities in graph feature extraction, exploration, and generation, offering potential for graph-structured matching generation. In this paper, we propose a GenAI-enabled matching generation framework to support 6G multiple access. Specifically, we first summarize the classical matching theory, discuss common GenAI models and applications from the perspective of matching generation. Then, we propose a framework based on generative diffusion models (GDMs) that iteratively denoises toward reward maximization to generate a matching strategy that meets specific requirements. Experimental results show that, compared to decision-based AI approaches, our framework can generate more effective matching strategies based on given conditions and predefined rewards, helping to solve complex problems in 6G multiple access, such as task allocation.
Prototypical Hash Encoding for On-the-Fly Fine-Grained Category Discovery
Oct 24, 2024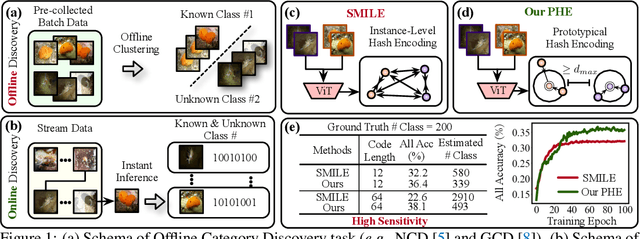

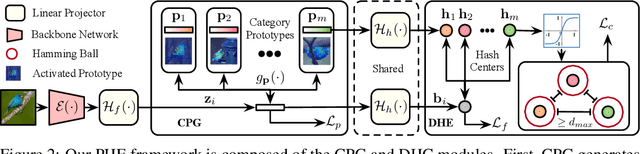
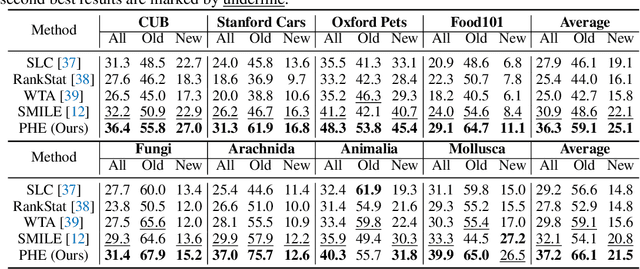
In this paper, we study a practical yet challenging task, On-the-fly Category Discovery (OCD), aiming to online discover the newly-coming stream data that belong to both known and unknown classes, by leveraging only known category knowledge contained in labeled data. Previous OCD methods employ the hash-based technique to represent old/new categories by hash codes for instance-wise inference. However, directly mapping features into low-dimensional hash space not only inevitably damages the ability to distinguish classes and but also causes "high sensitivity" issue, especially for fine-grained classes, leading to inferior performance. To address these issues, we propose a novel Prototypical Hash Encoding (PHE) framework consisting of Category-aware Prototype Generation (CPG) and Discriminative Category Encoding (DCE) to mitigate the sensitivity of hash code while preserving rich discriminative information contained in high-dimension feature space, in a two-stage projection fashion. CPG enables the model to fully capture the intra-category diversity by representing each category with multiple prototypes. DCE boosts the discrimination ability of hash code with the guidance of the generated category prototypes and the constraint of minimum separation distance. By jointly optimizing CPG and DCE, we demonstrate that these two components are mutually beneficial towards an effective OCD. Extensive experiments show the significant superiority of our PHE over previous methods, e.g., obtaining an improvement of +5.3% in ALL ACC averaged on all datasets. Moreover, due to the nature of the interpretable prototypes, we visually analyze the underlying mechanism of how PHE helps group certain samples into either known or unknown categories. Code is available at https://github.com/HaiyangZheng/PHE.
WeatherDG: LLM-assisted Procedural Weather Generation for Domain-Generalized Semantic Segmentation
Oct 15, 2024In this work, we propose a novel approach, namely WeatherDG, that can generate realistic, weather-diverse, and driving-screen images based on the cooperation of two foundation models, i.e, Stable Diffusion (SD) and Large Language Model (LLM). Specifically, we first fine-tune the SD with source data, aligning the content and layout of generated samples with real-world driving scenarios. Then, we propose a procedural prompt generation method based on LLM, which can enrich scenario descriptions and help SD automatically generate more diverse, detailed images. In addition, we introduce a balanced generation strategy, which encourages the SD to generate high-quality objects of tailed classes under various weather conditions, such as riders and motorcycles. This segmentation-model-agnostic method can improve the generalization ability of existing models by additionally adapting them with the generated synthetic data. Experiments on three challenging datasets show that our method can significantly improve the segmentation performance of different state-of-the-art models on target domains. Notably, in the setting of ''Cityscapes to ACDC'', our method improves the baseline HRDA by 13.9% in mIoU.
AllWeatherNet:Unified Image enhancement for autonomous driving under adverse weather and lowlight-conditions
Sep 03, 2024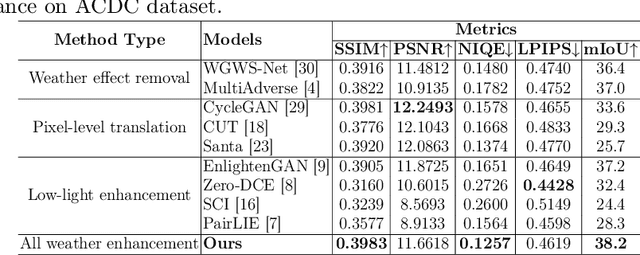

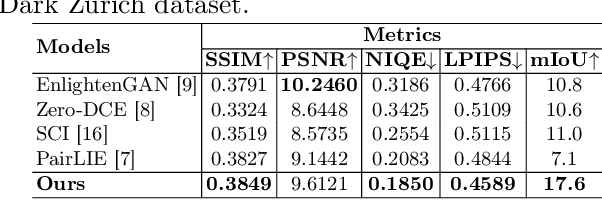
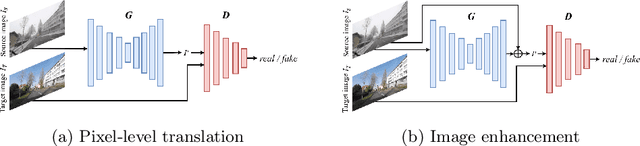
Adverse conditions like snow, rain, nighttime, and fog, pose challenges for autonomous driving perception systems. Existing methods have limited effectiveness in improving essential computer vision tasks, such as semantic segmentation, and often focus on only one specific condition, such as removing rain or translating nighttime images into daytime ones. To address these limitations, we propose a method to improve the visual quality and clarity degraded by such adverse conditions. Our method, AllWeather-Net, utilizes a novel hierarchical architecture to enhance images across all adverse conditions. This architecture incorporates information at three semantic levels: scene, object, and texture, by discriminating patches at each level. Furthermore, we introduce a Scaled Illumination-aware Attention Mechanism (SIAM) that guides the learning towards road elements critical for autonomous driving perception. SIAM exhibits robustness, remaining unaffected by changes in weather conditions or environmental scenes. AllWeather-Net effectively transforms images into normal weather and daytime scenes, demonstrating superior image enhancement results and subsequently enhancing the performance of semantic segmentation, with up to a 5.3% improvement in mIoU in the trained domain. We also show our model's generalization ability by applying it to unseen domains without re-training, achieving up to 3.9% mIoU improvement. Code can be accessed at: https://github.com/Jumponthemoon/AllWeatherNet.
Revolutionizing Wireless Networks with Self-Supervised Learning: A Pathway to Intelligent Communications
Jun 11, 2024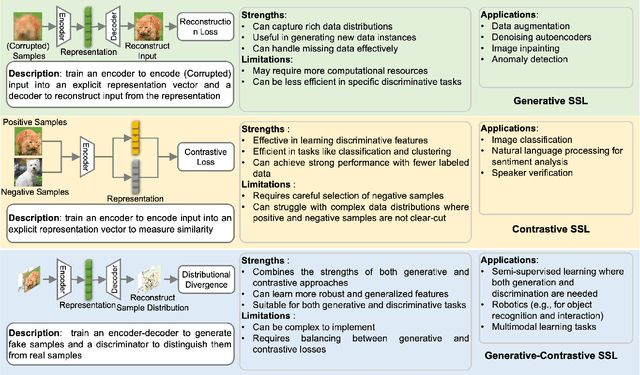
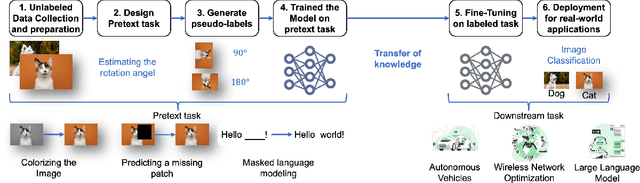

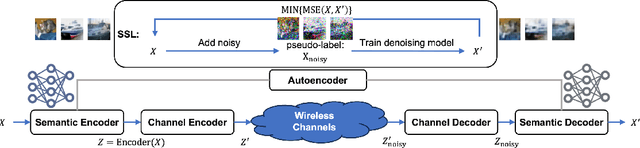
With the rapid proliferation of mobile devices and data, next-generation wireless communication systems face stringent requirements for ultra-low latency, ultra-high reliability, and massive connectivity. Traditional AI-driven wireless network designs, while promising, often suffer from limitations such as dependency on labeled data and poor generalization. To address these challenges, we present an integration of self-supervised learning (SSL) into wireless networks. SSL leverages large volumes of unlabeled data to train models, enhancing scalability, adaptability, and generalization. This paper offers a comprehensive overview of SSL, categorizing its application scenarios in wireless network optimization and presenting a case study on its impact on semantic communication. Our findings highlight the potentials of SSL to significantly improve wireless network performance without extensive labeled data, paving the way for more intelligent and efficient communication systems.
Textual Knowledge Matters: Cross-Modality Co-Teaching for Generalized Visual Class Discovery
Mar 12, 2024In this paper, we study the problem of Generalized Category Discovery (GCD), which aims to cluster unlabeled data from both known and unknown categories using the knowledge of labeled data from known categories. Current GCD methods rely on only visual cues, which however neglect the multi-modality perceptive nature of human cognitive processes in discovering novel visual categories. To address this, we propose a two-phase TextGCD framework to accomplish multi-modality GCD by exploiting powerful Visual-Language Models. TextGCD mainly includes a retrieval-based text generation (RTG) phase and a cross-modality co-teaching (CCT) phase. First, RTG constructs a visual lexicon using category tags from diverse datasets and attributes from Large Language Models, generating descriptive texts for images in a retrieval manner. Second, CCT leverages disparities between textual and visual modalities to foster mutual learning, thereby enhancing visual GCD. In addition, we design an adaptive class aligning strategy to ensure the alignment of category perceptions between modalities as well as a soft-voting mechanism to integrate multi-modality cues. Experiments on eight datasets show the large superiority of our approach over state-of-the-art methods. Notably, our approach outperforms the best competitor, by 7.7% and 10.8% in All accuracy on ImageNet-1k and CUB, respectively.