 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Importance in Pedestrian Intention Prediction: A Context-Aware Review
Sep 11, 2024
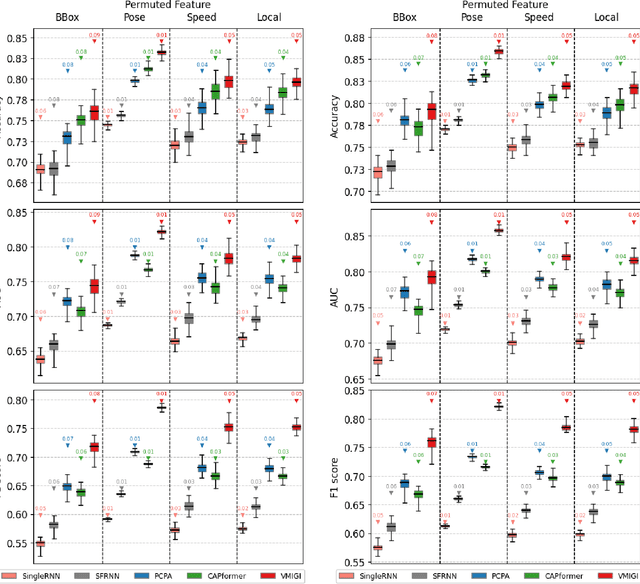
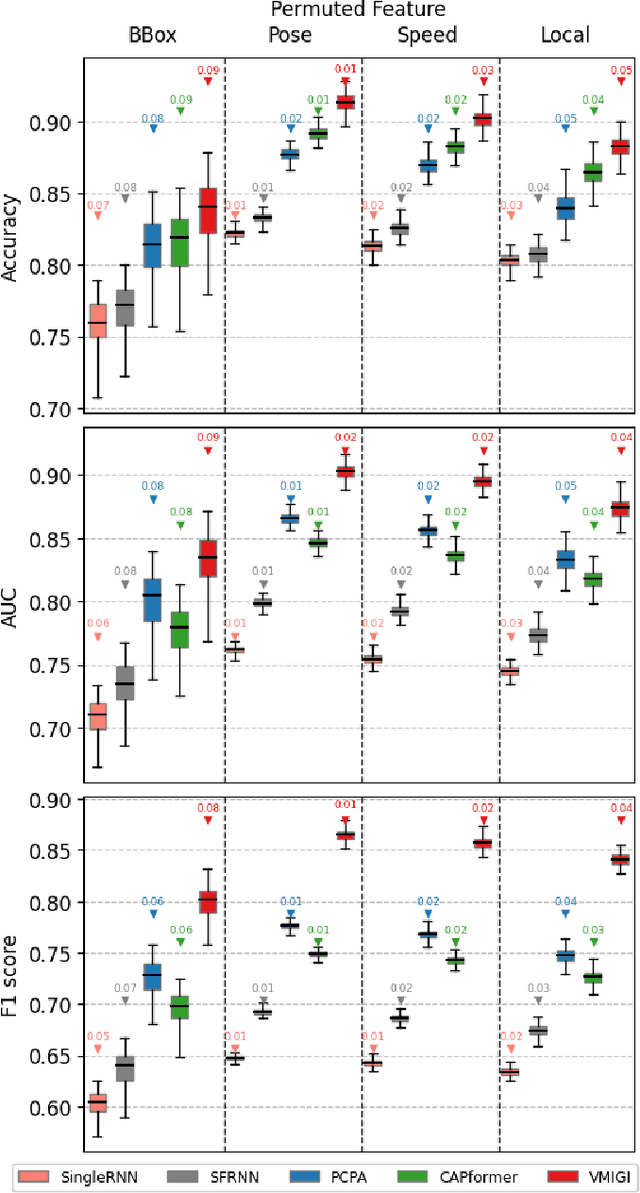
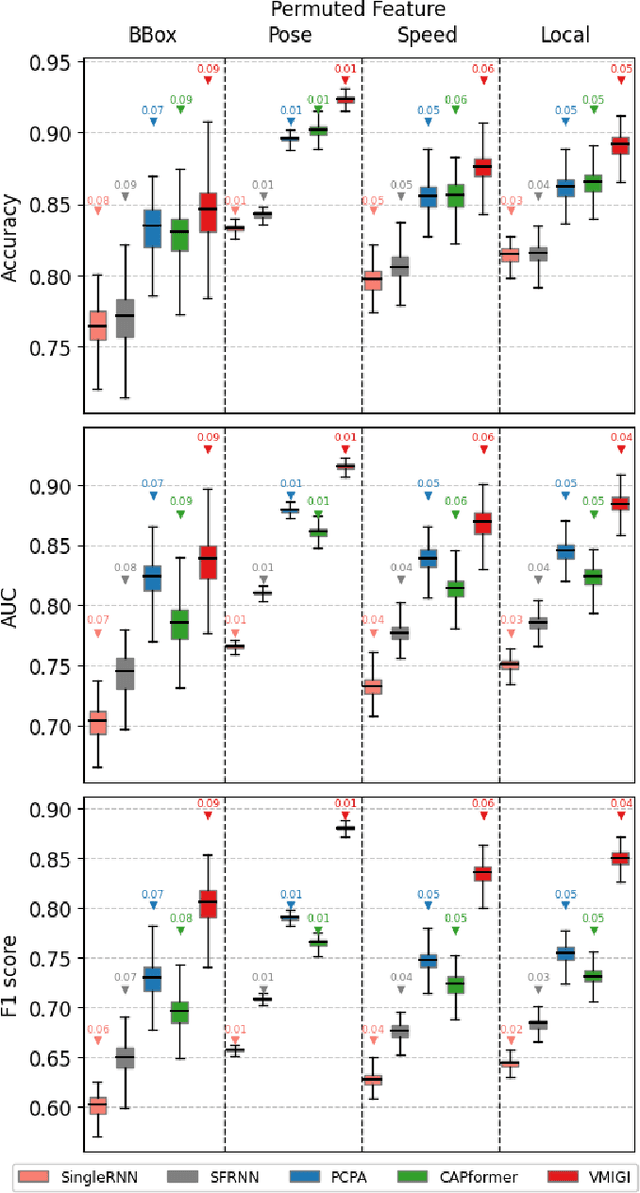
Recent advancements in predicting pedestrian crossing intentions for Autonomous Vehicles using Computer Vision and Deep Neural Networks are promising. However, the black-box nature of DNNs poses challenges in understanding how the model works and how input features contribute to final predictions. This lack of interpretability delimits the trust in model performance and hinders informed decisions on feature selection, representation, and model optimisation; thereby affecting the efficacy of future research in the field. To address this, we introduce Context-aware Permutation Feature Importance (CAPFI), a novel approach tailored for pedestrian intention prediction. CAPFI enables more interpretability and reliable assessments of feature importance by leveraging subdivided scenario contexts, mitigating the randomness of feature values through targeted shuffling. This aims to reduce variance and prevent biased estimations in importance scores during permutations. We divide the Pedestrian Intention Estimation (PIE) dataset into 16 comparable context sets, measure the baseline performance of five distinct neural network architectures for intention prediction in each context, and assess input feature importance using CAPFI. We observed nuanced differences among models across various contextual characteristics. The research reveals the critical role of pedestrian bounding boxes and ego-vehicle speed in predicting pedestrian intentions, and potential prediction biases due to the speed feature through cross-context permutation evaluation. We propose an alternative feature representation by considering proximity change rate for rendering dynamic pedestrian-vehicle locomotion, thereby enhancing the contributions of input features to intention prediction. These findings underscore the importance of contextual features and their diversity to develop accurate and robust intent-predictive models.
AllWeatherNet:Unified Image enhancement for autonomous driving under adverse weather and lowlight-conditions
Sep 03, 2024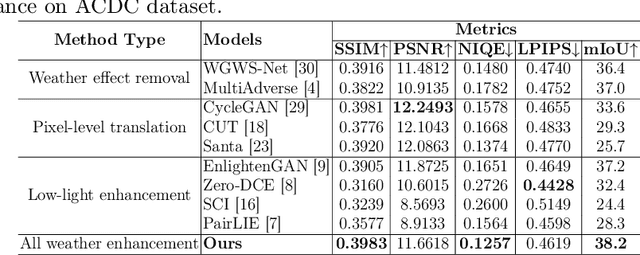

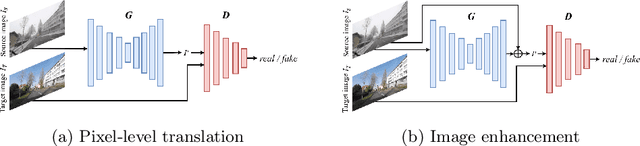
Adverse conditions like snow, rain, nighttime, and fog, pose challenges for autonomous driving perception systems. Existing methods have limited effectiveness in improving essential computer vision tasks, such as semantic segmentation, and often focus on only one specific condition, such as removing rain or translating nighttime images into daytime ones. To address these limitations, we propose a method to improve the visual quality and clarity degraded by such adverse conditions. Our method, AllWeather-Net, utilizes a novel hierarchical architecture to enhance images across all adverse conditions. This architecture incorporates information at three semantic levels: scene, object, and texture, by discriminating patches at each level. Furthermore, we introduce a Scaled Illumination-aware Attention Mechanism (SIAM) that guides the learning towards road elements critical for autonomous driving perception. SIAM exhibits robustness, remaining unaffected by changes in weather conditions or environmental scenes. AllWeather-Net effectively transforms images into normal weather and daytime scenes, demonstrating superior image enhancement results and subsequently enhancing the performance of semantic segmentation, with up to a 5.3% improvement in mIoU in the trained domain. We also show our model's generalization ability by applying it to unseen domains without re-training, achieving up to 3.9% mIoU improvement. Code can be accessed at: https://github.com/Jumponthemoon/AllWeatherNet.
PIP-Net: Pedestrian Intention Prediction in the Wild
Mar 01, 2024Accurate pedestrian intention prediction (PIP) by Autonomous Vehicles (AVs) is one of the current research challenges in this field. In this article, we introduce PIP-Net, a novel framework designed to predict pedestrian crossing intentions by AVs in real-world urban scenarios. We offer two variants of PIP-Net designed for different camera mounts and setups. Leveraging both kinematic data and spatial features from the driving scene, the proposed model employs a recurrent and temporal attention-based solution, outperforming state-of-the-art performance. To enhance the visual representation of road users and their proximity to the ego vehicle, we introduce a categorical depth feature map, combined with a local motion flow feature, providing rich insights into the scene dynamics. Additionally, we explore the impact of expanding the camera's field of view, from one to three cameras surrounding the ego vehicle, leading to enhancement in the model's contextual perception. Depending on the traffic scenario and road environment, the model excels in predicting pedestrian crossing intentions up to 4 seconds in advance which is a breakthrough in current research studies in pedestrian intention prediction. Finally, for the first time, we present the Urban-PIP dataset, a customised pedestrian intention prediction dataset, with multi-camera annotations in real-world automated driving scenarios.
Evaluating Driver Readiness in Conditionally Automated Vehicles from Eye-Tracking Data and Head Pose
Jan 20, 2024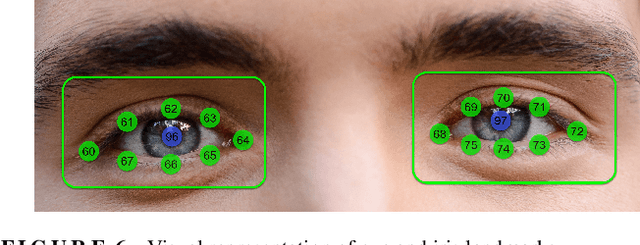
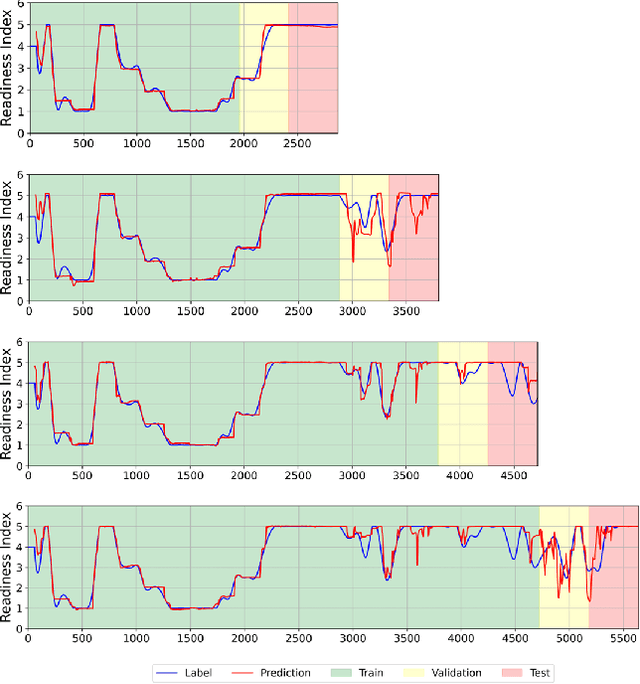
As automated driving technology advances, the role of the driver to resume control of the vehicle in conditionally automated vehicles becomes increasingly critical. In the SAE Level 3 or partly automated vehicles, the driver needs to be available and ready to intervene when necessary. This makes it essential to evaluate their readiness accurately. This article presents a comprehensive analysis of driver readiness assessment by combining head pose features and eye-tracking data. The study explores the effectiveness of predictive models in evaluating driver readiness, addressing the challenges of dataset limitations and limited ground truth labels. Machine learning techniques, including LSTM architectures, are utilised to model driver readiness based on the Spatio-temporal status of the driver's head pose and eye gaze. The experiments in this article revealed that a Bidirectional LSTM architecture, combining both feature sets, achieves a mean absolute error of 0.363 on the DMD dataset, demonstrating superior performance in assessing driver readiness. The modular architecture of the proposed model also allows the integration of additional driver-specific features, such as steering wheel activity, enhancing its adaptability and real-world applicability.
Local and Global Contextual Features Fusion for Pedestrian Intention Prediction
May 01, 2023


Autonomous vehicles (AVs) are becoming an indispensable part of future transportation. However, safety challenges and lack of reliability limit their real-world deployment. Towards boosting the appearance of AVs on the roads, the interaction of AVs with pedestrians including "prediction of the pedestrian crossing intention" deserves extensive research. This is a highly challenging task as involves multiple non-linear parameters. In this direction, we extract and analyse spatio-temporal visual features of both pedestrian and traffic contexts. The pedestrian features include body pose and local context features that represent the pedestrian's behaviour. Additionally, to understand the global context, we utilise location, motion, and environmental information using scene parsing technology that represents the pedestrian's surroundings, and may affect the pedestrian's intention. Finally, these multi-modality features are intelligently fused for effective intention prediction learning. The experimental results of the proposed model on the JAAD dataset show a superior result on the combined AUC and F1-score compared to the state-of-the-art.
Traffic-Net: 3D Traffic Monitoring Using a Single Camera
Sep 19, 2021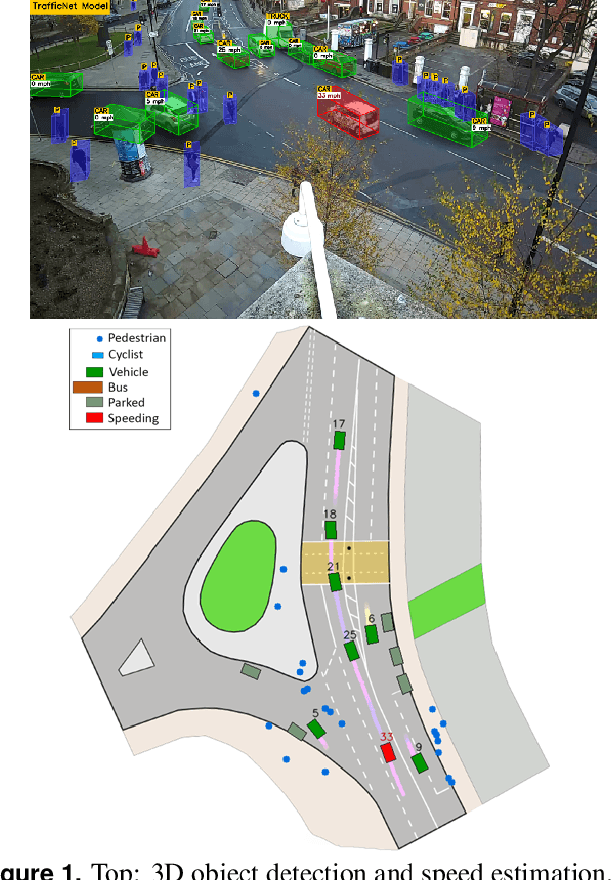
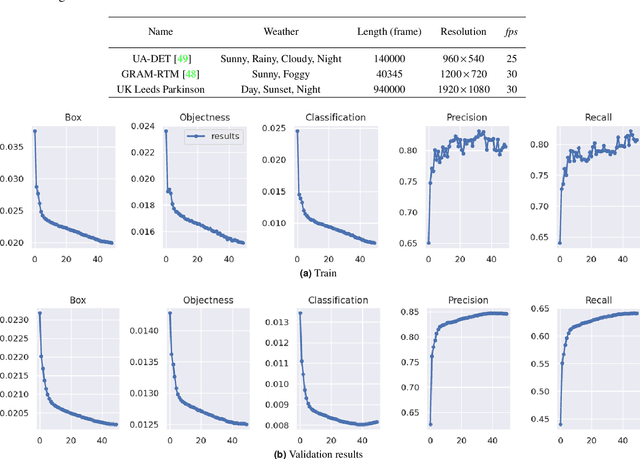
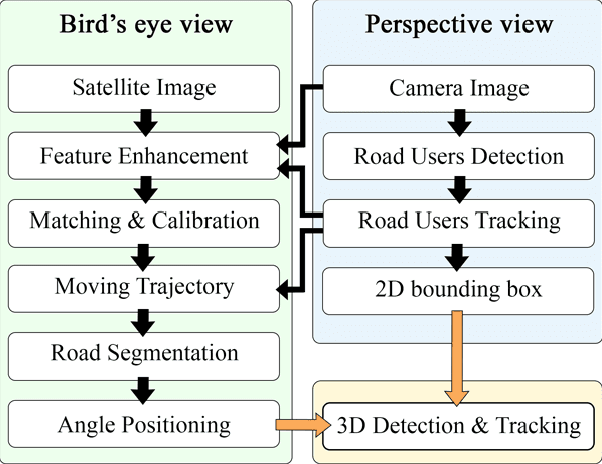
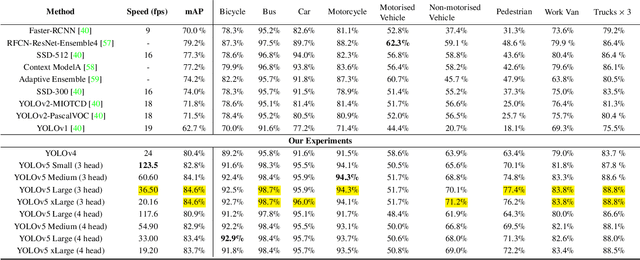
Computer Vision has played a major role in Intelligent Transportation Systems (ITS) and traffic surveillance. Along with the rapidly growing automated vehicles and crowded cities, the automated and advanced traffic management systems (ATMS) using video surveillance infrastructures have been evolved by the implementation of Deep Neural Networks. In this research, we provide a practical platform for real-time traffic monitoring, including 3D vehicle/pedestrian detection, speed detection, trajectory estimation, congestion detection, as well as monitoring the interaction of vehicles and pedestrians, all using a single CCTV traffic camera. We adapt a custom YOLOv5 deep neural network model for vehicle/pedestrian detection and an enhanced SORT tracking algorithm. For the first time, a hybrid satellite-ground based inverse perspective mapping (SG-IPM) method for camera auto-calibration is also developed which leads to an accurate 3D object detection and visualisation. We also develop a hierarchical traffic modelling solution based on short- and long-term temporal video data stream to understand the traffic flow, bottlenecks, and risky spots for vulnerable road users. Several experiments on real-world scenarios and comparisons with state-of-the-art are conducted using various traffic monitoring datasets, including MIO-TCD, UA-DETRAC and GRAM-RTM collected from highways, intersections, and urban areas under different lighting and weather conditions.
DeepSOCIAL: Social Distancing Monitoring and Infection Risk Assessment in COVID-19 Pandemic
Aug 31, 2020

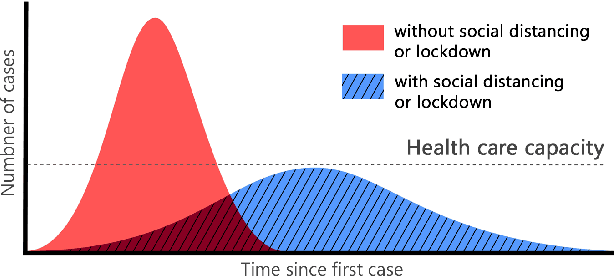

Social distancing is a recommended solution by the World Health Organisation (WHO) to minimise the spread of COVID-19 in public places. The majority of governments and national health authorities have set the 2-meter physical distancing as a mandatory safety measure in shopping centres, schools and other covered areas. In this research, we develop a generic Deep Neural Network-Based model for automated people detection, tracking, and inter-people distances estimation in the crowd, using common CCTV security cameras. The proposed model includes a YOLOv4-based framework and inverse perspective mapping for accurate people detection and social distancing monitoring in challenging conditions, including people occlusion, partial visibility, and lighting variations. We also provide an online risk assessment scheme by statistical analysis of the Spatio-temporal data from the moving trajectories and the rate of social distancing violations. We identify high-risk zones with the highest possibility of virus spread and infections. This may help authorities to redesign the layout of a public place or to take precaution actions to mitigate high-risk zones. The efficiency of the proposed methodology is evaluated on the Oxford Town Centre dataset, with superior performance in terms of accuracy and speed compared to three state-of-the-art methods.