 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Reasoning and Multi-Agent Approach in Multimodal Large Language Models (MLLMs): Solving TSP and mTSP Combinatorial Challenges
Jun 26, 2024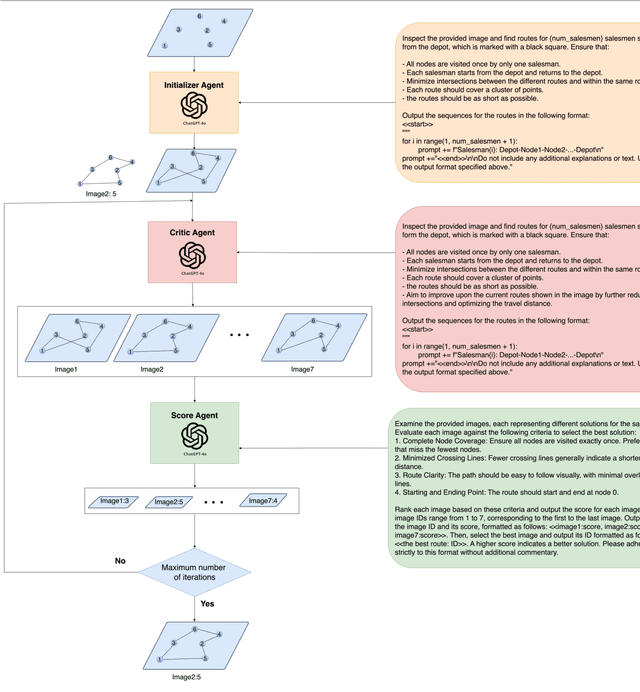
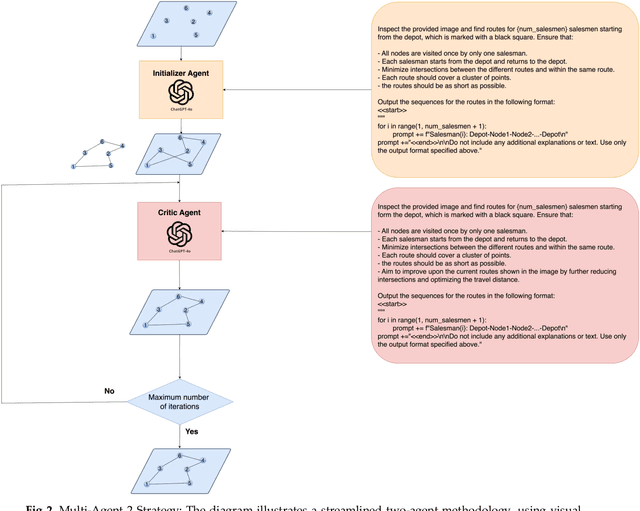
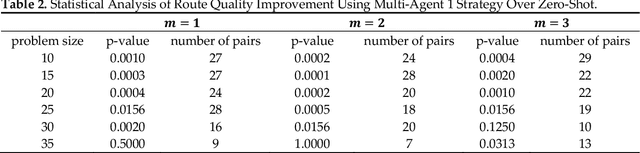
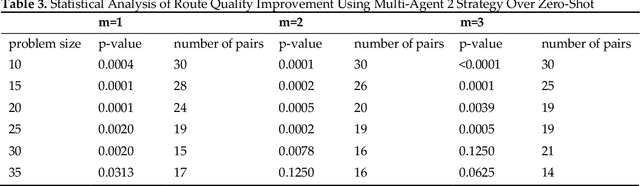
Multimodal Large Language Models (MLLMs) harness comprehensive knowledge spanning text, images, and audio to adeptly tackle complex problems, including zero-shot in-context learning scenarios. This study explores the ability of MLLMs in visually solving the Traveling Salesman Problem (TSP) and Multiple Traveling Salesman Problem (mTSP) using images that portray point distributions on a two-dimensional plane. We introduce a novel approach employing multiple specialized agents within the MLLM framework, each dedicated to optimizing solutions for these combinatorial challenges. Our experimental investigation includes rigorous evaluations across zero-shot settings and introduces innovative multi-agent zero-shot in-context scenarios. The results demonstrated that both multi-agent models. Multi-Agent 1, which includes the Initializer, Critic, and Scorer agents, and Multi-Agent 2, which comprises only the Initializer and Critic agents; significantly improved solution quality for TSP and mTSP problems. Multi-Agent 1 excelled in environments requiring detailed route refinement and evaluation, providing a robust framework for sophisticated optimizations. In contrast, Multi-Agent 2, focusing on iterative refinements by the Initializer and Critic, proved effective for rapid decision-making scenarios. These experiments yield promising outcomes, showcasing the robust visual reasoning capabilities of MLLMs in addressing diverse combinatorial problems. The findings underscore the potential of MLLMs as powerful tools in computational optimization, offering insights that could inspire further advancements in this promising field. Project link: https://github.com/ahmed-abdulhuy/Solving-TSP-and-mTSP-Combinatorial-Challenges-using-Visual-Reasoning-and-Multi-Agent-Approach-MLLMs-.git
Eyeballing Combinatorial Problems: A Case Study of Using Multimodal Large Language Models to Solve Traveling Salesman Problems
Jun 11, 2024



Multimodal Large Language Models (MLLMs) have demonstrated proficiency in processing di-verse modalities, including text, images, and audio. These models leverage extensive pre-existing knowledge, enabling them to address complex problems with minimal to no specific training examples, as evidenced in few-shot and zero-shot in-context learning scenarios. This paper investigates the use of MLLMs' visual capabilities to 'eyeball' solutions for the Traveling Salesman Problem (TSP) by analyzing images of point distributions on a two-dimensional plane. Our experiments aimed to validate the hypothesis that MLLMs can effectively 'eyeball' viable TSP routes. The results from zero-shot, few-shot, self-ensemble, and self-refine zero-shot evaluations show promising outcomes. We anticipate that these findings will inspire further exploration into MLLMs' visual reasoning abilities to tackle other combinatorial problems.
PIP-Net: Pedestrian Intention Prediction in the Wild
Mar 01, 2024Accurate pedestrian intention prediction (PIP) by Autonomous Vehicles (AVs) is one of the current research challenges in this field. In this article, we introduce PIP-Net, a novel framework designed to predict pedestrian crossing intentions by AVs in real-world urban scenarios. We offer two variants of PIP-Net designed for different camera mounts and setups. Leveraging both kinematic data and spatial features from the driving scene, the proposed model employs a recurrent and temporal attention-based solution, outperforming state-of-the-art performance. To enhance the visual representation of road users and their proximity to the ego vehicle, we introduce a categorical depth feature map, combined with a local motion flow feature, providing rich insights into the scene dynamics. Additionally, we explore the impact of expanding the camera's field of view, from one to three cameras surrounding the ego vehicle, leading to enhancement in the model's contextual perception. Depending on the traffic scenario and road environment, the model excels in predicting pedestrian crossing intentions up to 4 seconds in advance which is a breakthrough in current research studies in pedestrian intention prediction. Finally, for the first time, we present the Urban-PIP dataset, a customised pedestrian intention prediction dataset, with multi-camera annotations in real-world automated driving scenarios.
Hybrid Pointer Networks for Traveling Salesman Problems Optimization
Oct 13, 2021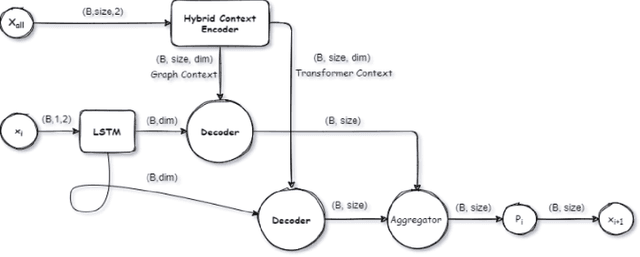
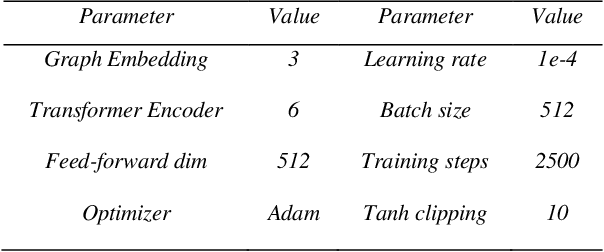
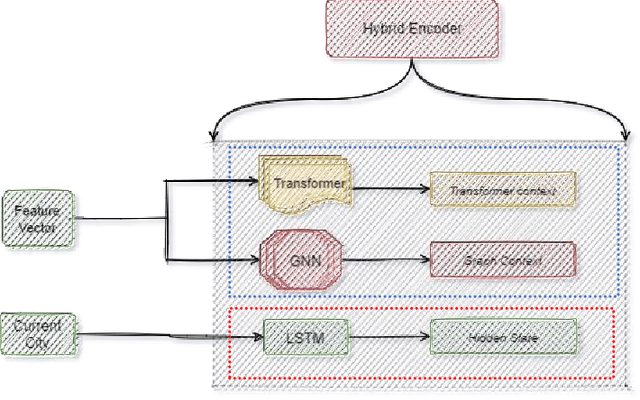
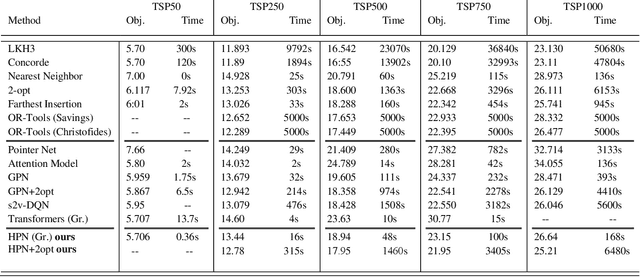
In this work, a novel idea is presented for combinatorial optimization problems, a hybrid network, which results in a superior outcome. We applied this method to graph pointer networks [1], expanding its capabilities to a higher level. We proposed a hybrid pointer network (HPN) to solve the travelling salesman problem trained by reinforcement learning. Furthermore, HPN builds upon graph pointer networks which is an extension of pointer networks with an additional graph embedding layer. HPN outperforms the graph pointer network in solution quality due to the hybrid encoder, which provides our model with a verity encoding type, allowing our model to converge to a better policy. Our network significantly outperforms the original graph pointer network for small and large-scale problems increasing its performance for TSP50 from 5.959 to 5.706 without utilizing 2opt, Pointer networks, Attention model, and a wide range of models, producing results comparable to highly tuned and specialized algorithms. We make our data, models, and code publicly available [2].