 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Pavement Crack Classification with Bidirectional Cascaded Neural Networks
Mar 27, 2025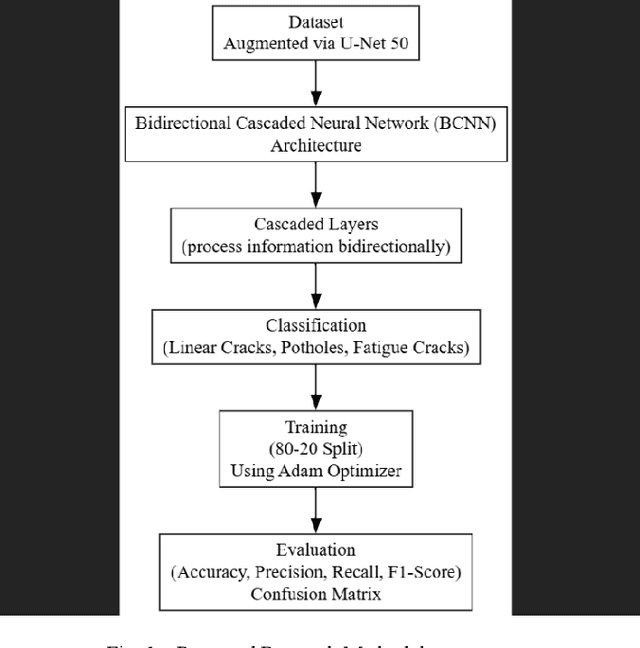

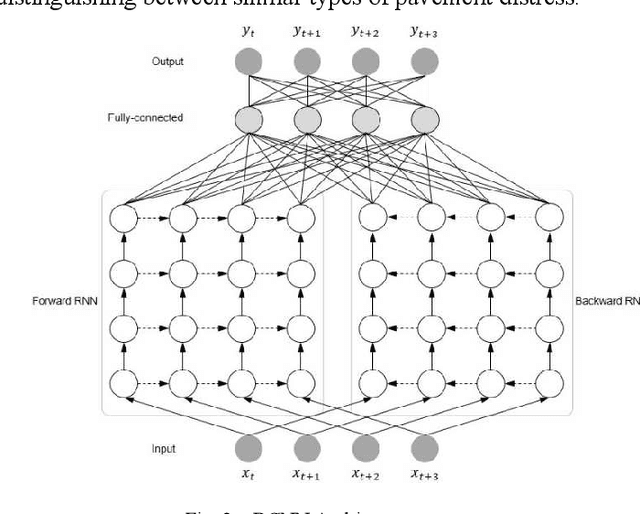
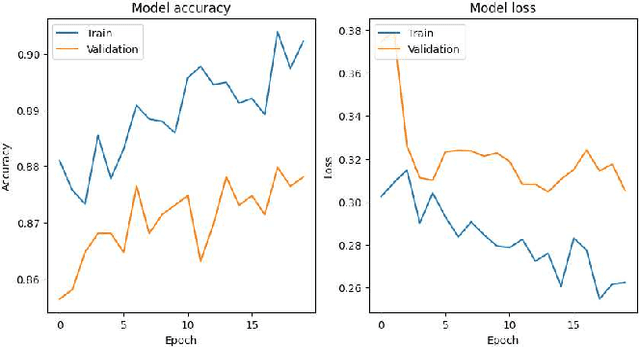
Pavement distress, such as cracks and potholes, is a significant issue affecting road safety and maintenance. In this study, we present the implementation and evaluation of Bidirectional Cascaded Neural Networks (BCNNs) for the classification of pavement crack images following image augmentation. We classified pavement cracks into three main categories: linear cracks, potholes, and fatigue cracks on an enhanced dataset utilizing U-Net 50 for image augmentation. The augmented dataset comprised 599 images. Our proposed BCNN model was designed to leverage both forward and backward information flows, with detection accuracy enhanced by its cascaded structure wherein each layer progressively refines the output of the preceding one. Our model achieved an overall accuracy of 87%, with precision, recall, and F1-score measures indicating high effectiveness across the categories. For fatigue cracks, the model recorded a precision of 0.87, recall of 0.83, and F1-score of 0.85 on 205 images. Linear cracks were detected with a precision of 0.81, recall of 0.89, and F1-score of 0.85 on 205 images, and potholes with a precision of 0.96, recall of 0.90, and F1-score of 0.93 on 189 images. The macro and weighted average of precision, recall, and F1-score were identical at 0.88, confirming the BCNN's excellent performance in classifying complex pavement crack patterns. This research demonstrates the potential of BCNNs to significantly enhance the accuracy and reliability of pavement distress classification, resulting in more effective and efficient pavement maintenance and management systems.
Vision-Language Models for Autonomous Driving: CLIP-Based Dynamic Scene Understanding
Jan 09, 2025



Scene understanding is essential for enhancing driver safety, generating human-centric explanations for Automated Vehicle (AV) decisions, and leveraging Artificial Intelligence (AI) for retrospective driving video analysis. This study developed a dynamic scene retrieval system using Contrastive Language-Image Pretraining (CLIP) models, which can be optimized for real-time deployment on edge devices. The proposed system outperforms state-of-the-art in-context learning methods, including the zero-shot capabilities of GPT-4o, particularly in complex scenarios. By conducting frame-level analysis on the Honda Scenes Dataset, which contains a collection of about 80 hours of annotated driving videos capturing diverse real-world road and weather conditions, our study highlights the robustness of CLIP models in learning visual concepts from natural language supervision. Results also showed that fine-tuning the CLIP models, such as ViT-L/14 and ViT-B/32, significantly improved scene classification, achieving a top F1 score of 91.1%. These results demonstrate the ability of the system to deliver rapid and precise scene recognition, which can be used to meet the critical requirements of Advanced Driver Assistance Systems (ADAS). This study shows the potential of CLIP models to provide scalable and efficient frameworks for dynamic scene understanding and classification. Furthermore, this work lays the groundwork for advanced autonomous vehicle technologies by fostering a deeper understanding of driver behavior, road conditions, and safety-critical scenarios, marking a significant step toward smarter, safer, and more context-aware autonomous driving systems.
Advancing Object Detection in Transportation with Multimodal Large Language Models (MLLMs): A Comprehensive Review and Empirical Testing
Sep 26, 2024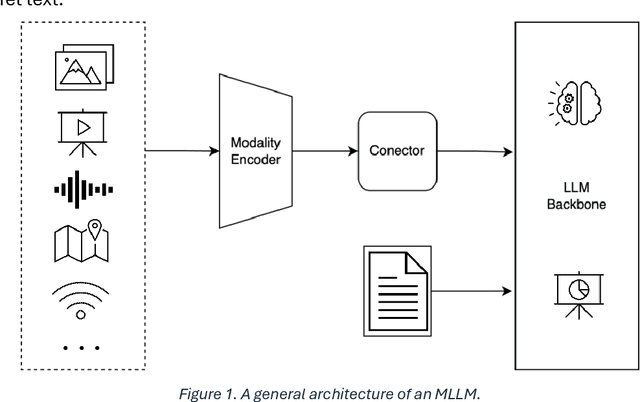
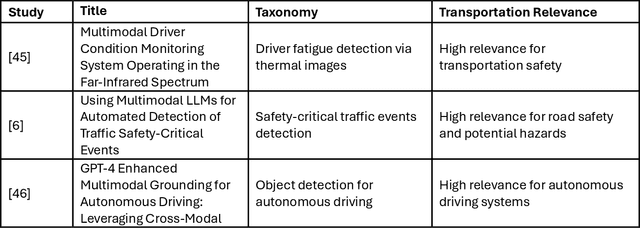
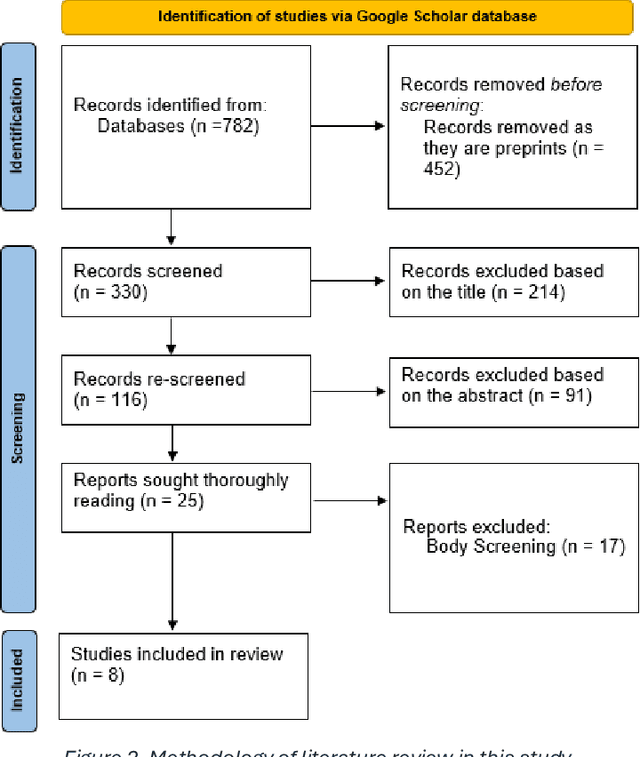
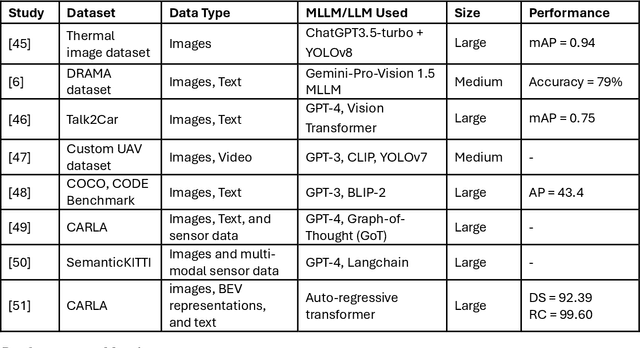
This study aims to comprehensively review and empirically evaluate the application of multimodal large language models (MLLMs) and Large Vision Models (VLMs) in object detection for transportation systems. In the first fold, we provide a background about the potential benefits of MLLMs in transportation applications and conduct a comprehensive review of current MLLM technologies in previous studies. We highlight their effectiveness and limitations in object detection within various transportation scenarios. The second fold involves providing an overview of the taxonomy of end-to-end object detection in transportation applications and future directions. Building on this, we proposed empirical analysis for testing MLLMs on three real-world transportation problems that include object detection tasks namely, road safety attributes extraction, safety-critical event detection, and visual reasoning of thermal images. Our findings provide a detailed assessment of MLLM performance, uncovering both strengths and areas for improvement. Finally, we discuss practical limitations and challenges of MLLMs in enhancing object detection in transportation, thereby offering a roadmap for future research and development in this critical area.
Visual Reasoning and Multi-Agent Approach in Multimodal Large Language Models (MLLMs): Solving TSP and mTSP Combinatorial Challenges
Jun 26, 2024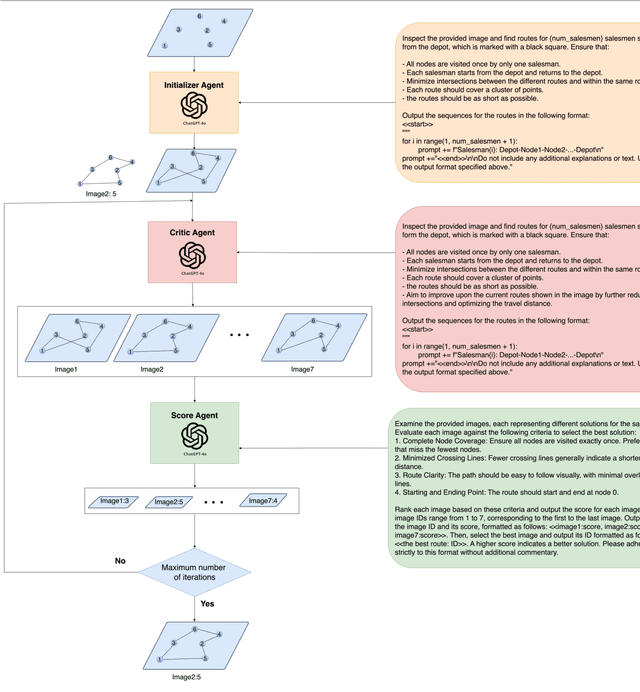
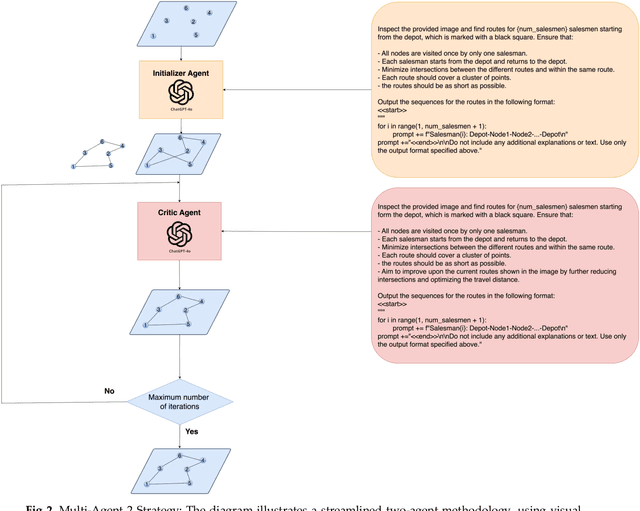
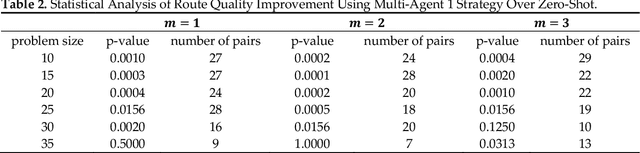
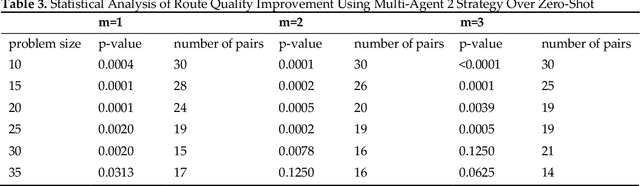
Multimodal Large Language Models (MLLMs) harness comprehensive knowledge spanning text, images, and audio to adeptly tackle complex problems, including zero-shot in-context learning scenarios. This study explores the ability of MLLMs in visually solving the Traveling Salesman Problem (TSP) and Multiple Traveling Salesman Problem (mTSP) using images that portray point distributions on a two-dimensional plane. We introduce a novel approach employing multiple specialized agents within the MLLM framework, each dedicated to optimizing solutions for these combinatorial challenges. Our experimental investigation includes rigorous evaluations across zero-shot settings and introduces innovative multi-agent zero-shot in-context scenarios. The results demonstrated that both multi-agent models. Multi-Agent 1, which includes the Initializer, Critic, and Scorer agents, and Multi-Agent 2, which comprises only the Initializer and Critic agents; significantly improved solution quality for TSP and mTSP problems. Multi-Agent 1 excelled in environments requiring detailed route refinement and evaluation, providing a robust framework for sophisticated optimizations. In contrast, Multi-Agent 2, focusing on iterative refinements by the Initializer and Critic, proved effective for rapid decision-making scenarios. These experiments yield promising outcomes, showcasing the robust visual reasoning capabilities of MLLMs in addressing diverse combinatorial problems. The findings underscore the potential of MLLMs as powerful tools in computational optimization, offering insights that could inspire further advancements in this promising field. Project link: https://github.com/ahmed-abdulhuy/Solving-TSP-and-mTSP-Combinatorial-Challenges-using-Visual-Reasoning-and-Multi-Agent-Approach-MLLMs-.git
Object Detection using Oriented Window Learning Vi-sion Transformer: Roadway Assets Recognition
Jun 15, 2024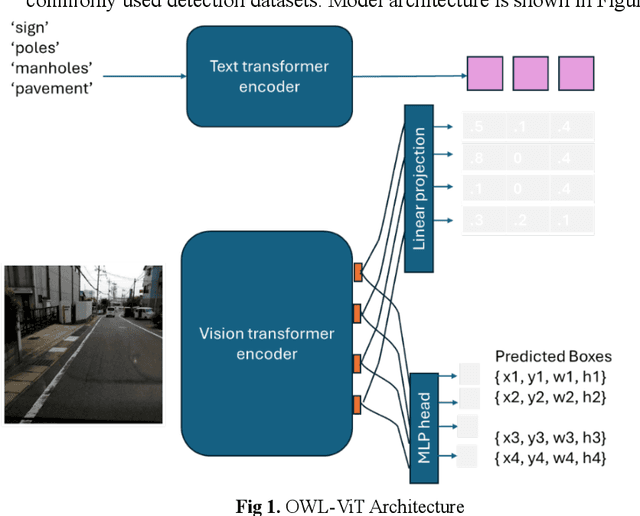
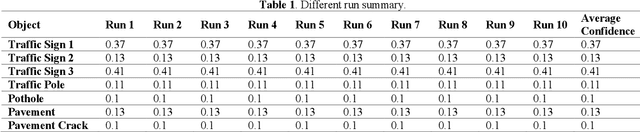
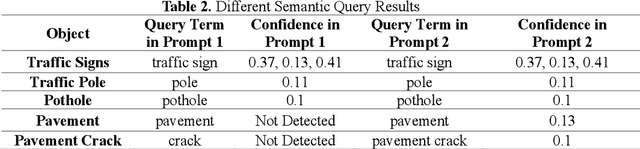

Object detection is a critical component of transportation systems, particularly for applications such as autonomous driving, traffic monitoring, and infrastructure maintenance. Traditional object detection methods often struggle with limited data and variability in object appearance. The Oriented Window Learning Vision Transformer (OWL-ViT) offers a novel approach by adapting window orientations to the geometry and existence of objects, making it highly suitable for detecting diverse roadway assets. This study leverages OWL-ViT within a one-shot learning framework to recognize transportation infrastructure components, such as traffic signs, poles, pavement, and cracks. This study presents a novel method for roadway asset detection using OWL-ViT. We conducted a series of experiments to evaluate the performance of the model in terms of detection consistency, semantic flexibility, visual context adaptability, resolution robustness, and impact of non-max suppression. The results demonstrate the high efficiency and reliability of the OWL-ViT across various scenarios, underscoring its potential to enhance the safety and efficiency of intelligent transportation systems.
Eyeballing Combinatorial Problems: A Case Study of Using Multimodal Large Language Models to Solve Traveling Salesman Problems
Jun 11, 2024



Multimodal Large Language Models (MLLMs) have demonstrated proficiency in processing di-verse modalities, including text, images, and audio. These models leverage extensive pre-existing knowledge, enabling them to address complex problems with minimal to no specific training examples, as evidenced in few-shot and zero-shot in-context learning scenarios. This paper investigates the use of MLLMs' visual capabilities to 'eyeball' solutions for the Traveling Salesman Problem (TSP) by analyzing images of point distributions on a two-dimensional plane. Our experiments aimed to validate the hypothesis that MLLMs can effectively 'eyeball' viable TSP routes. The results from zero-shot, few-shot, self-ensemble, and self-refine zero-shot evaluations show promising outcomes. We anticipate that these findings will inspire further exploration into MLLMs' visual reasoning abilities to tackle other combinatorial problems.