 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Detection using Oriented Window Learning Vi-sion Transformer: Roadway Assets Recognition
Paper and Code
Jun 15, 2024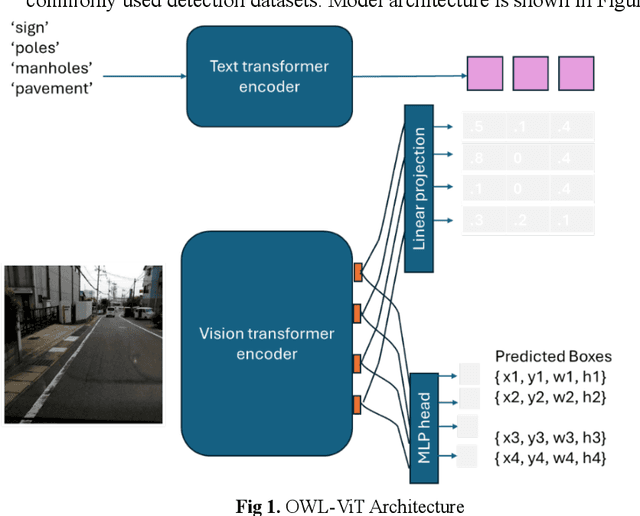
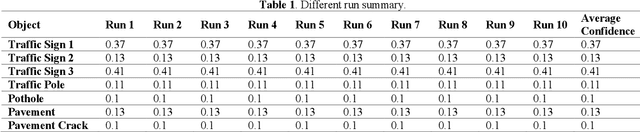
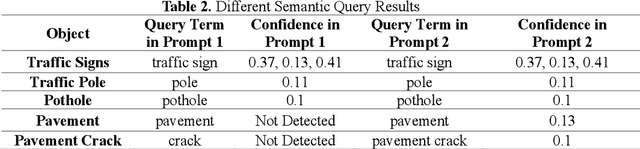

Object detection is a critical component of transportation systems, particularly for applications such as autonomous driving, traffic monitoring, and infrastructure maintenance. Traditional object detection methods often struggle with limited data and variability in object appearance. The Oriented Window Learning Vision Transformer (OWL-ViT) offers a novel approach by adapting window orientations to the geometry and existence of objects, making it highly suitable for detecting diverse roadway assets. This study leverages OWL-ViT within a one-shot learning framework to recognize transportation infrastructure components, such as traffic signs, poles, pavement, and cracks. This study presents a novel method for roadway asset detection using OWL-ViT. We conducted a series of experiments to evaluate the performance of the model in terms of detection consistency, semantic flexibility, visual context adaptability, resolution robustness, and impact of non-max suppression. The results demonstrate the high efficiency and reliability of the OWL-ViT across various scenarios, underscoring its potential to enhance the safety and efficiency of intelligent transportation systems.