 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Large Language Models for Enhanced Traffic Safety: A Comprehensive Review and Future Trends
Apr 21, 2025Traffic safety remains a critical global challenge, with traditional Advanced Driver-Assistance Systems (ADAS) often struggling in dynamic real-world scenarios due to fragmented sensor processing and susceptibility to adversarial conditions. This paper reviews the transformative potential of Multimodal Large Language Models (MLLMs) in addressing these limitations by integrating cross-modal data such as visual, spatial, and environmental inputs to enable holistic scene understanding. Through a comprehensive analysis of MLLM-based approaches, we highlight their capabilities in enhancing perception, decision-making, and adversarial robustness, while also examining the role of key datasets (e.g., KITTI, DRAMA, ML4RoadSafety) in advancing research. Furthermore, we outline future directions, including real-time edge deployment, causality-driven reasoning, and human-AI collaboration. By positioning MLLMs as a cornerstone for next-generation traffic safety systems, this review underscores their potential to revolutionize the field, offering scalable, context-aware solutions that proactively mitigate risks and improve overall road safety.
Enhancing Pavement Crack Classification with Bidirectional Cascaded Neural Networks
Mar 27, 2025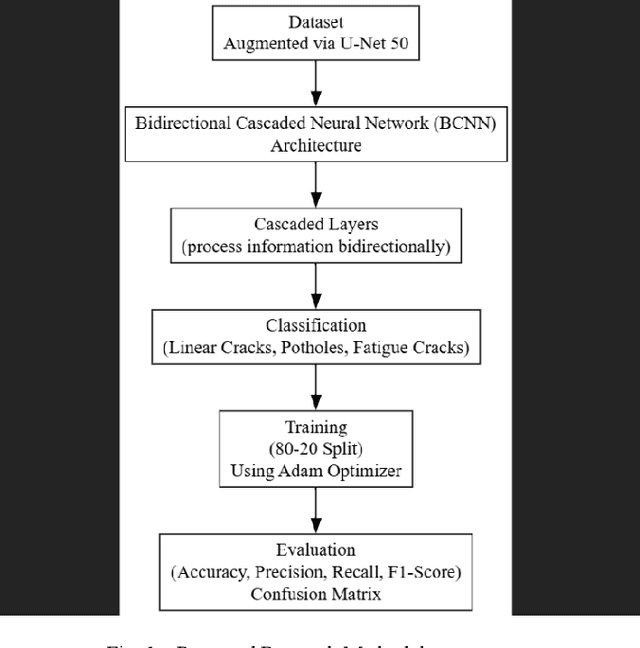

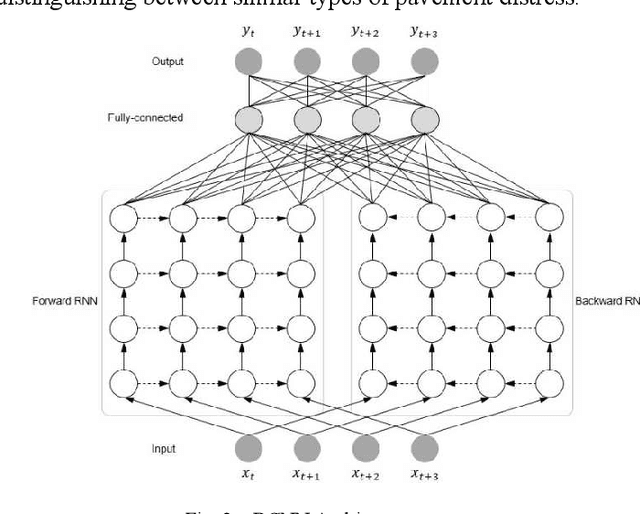
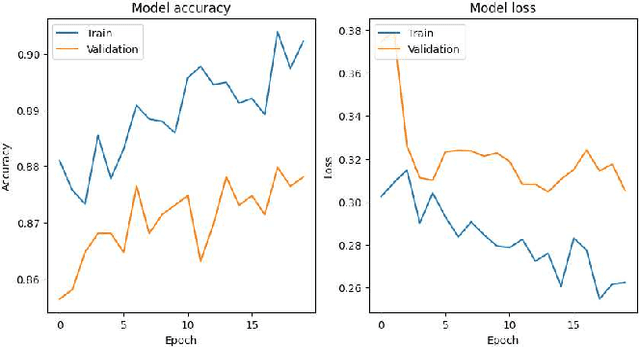
Pavement distress, such as cracks and potholes, is a significant issue affecting road safety and maintenance. In this study, we present the implementation and evaluation of Bidirectional Cascaded Neural Networks (BCNNs) for the classification of pavement crack images following image augmentation. We classified pavement cracks into three main categories: linear cracks, potholes, and fatigue cracks on an enhanced dataset utilizing U-Net 50 for image augmentation. The augmented dataset comprised 599 images. Our proposed BCNN model was designed to leverage both forward and backward information flows, with detection accuracy enhanced by its cascaded structure wherein each layer progressively refines the output of the preceding one. Our model achieved an overall accuracy of 87%, with precision, recall, and F1-score measures indicating high effectiveness across the categories. For fatigue cracks, the model recorded a precision of 0.87, recall of 0.83, and F1-score of 0.85 on 205 images. Linear cracks were detected with a precision of 0.81, recall of 0.89, and F1-score of 0.85 on 205 images, and potholes with a precision of 0.96, recall of 0.90, and F1-score of 0.93 on 189 images. The macro and weighted average of precision, recall, and F1-score were identical at 0.88, confirming the BCNN's excellent performance in classifying complex pavement crack patterns. This research demonstrates the potential of BCNNs to significantly enhance the accuracy and reliability of pavement distress classification, resulting in more effective and efficient pavement maintenance and management systems.
HazardNet: A Small-Scale Vision Language Model for Real-Time Traffic Safety Detection at Edge Devices
Feb 27, 2025



Traffic safety remains a vital concern in contemporary urban settings, intensified by the increase of vehicles and the complicated nature of road networks. Traditional safety-critical event detection systems predominantly rely on sensor-based approaches and conventional machine learning algorithms, necessitating extensive data collection and complex training processes to adhere to traffic safety regulations. This paper introduces HazardNet, a small-scale Vision Language Model designed to enhance traffic safety by leveraging the reasoning capabilities of advanced language and vision models. We built HazardNet by fine-tuning the pre-trained Qwen2-VL-2B model, chosen for its superior performance among open-source alternatives and its compact size of two billion parameters. This helps to facilitate deployment on edge devices with efficient inference throughput. In addition, we present HazardQA, a novel Vision Question Answering (VQA) dataset constructed specifically for training HazardNet on real-world scenarios involving safety-critical events. Our experimental results show that the fine-tuned HazardNet outperformed the base model up to an 89% improvement in F1-Score and has comparable results with improvement in some cases reach up to 6% when compared to larger models, such as GPT-4o. These advancements underscore the potential of HazardNet in providing real-time, reliable traffic safety event detection, thereby contributing to reduced accidents and improved traffic management in urban environments. Both HazardNet model and the HazardQA dataset are available at https://huggingface.co/Tami3/HazardNet and https://huggingface.co/datasets/Tami3/HazardQA, respectively.
Visual Reasoning at Urban Intersections: FineTuning GPT-4o for Traffic Conflict Detection
Feb 27, 2025Traffic control in unsignalized urban intersections presents significant challenges due to the complexity, frequent conflicts, and blind spots. This study explores the capability of leveraging Multimodal Large Language Models (MLLMs), such as GPT-4o, to provide logical and visual reasoning by directly using birds-eye-view videos of four-legged intersections. In this proposed method, GPT-4o acts as intelligent system to detect conflicts and provide explanations and recommendations for the drivers. The fine-tuned model achieved an accuracy of 77.14%, while the manual evaluation of the true predicted values of the fine-tuned GPT-4o showed significant achievements of 89.9% accuracy for model-generated explanations and 92.3% for the recommended next actions. These results highlight the feasibility of using MLLMs for real-time traffic management using videos as inputs, offering scalable and actionable insights into intersections traffic management and operation. Code used in this study is available at https://github.com/sarimasri3/Traffic-Intersection-Conflict-Detection-using-images.git.
Vision-Language Models for Autonomous Driving: CLIP-Based Dynamic Scene Understanding
Jan 09, 2025



Scene understanding is essential for enhancing driver safety, generating human-centric explanations for Automated Vehicle (AV) decisions, and leveraging Artificial Intelligence (AI) for retrospective driving video analysis. This study developed a dynamic scene retrieval system using Contrastive Language-Image Pretraining (CLIP) models, which can be optimized for real-time deployment on edge devices. The proposed system outperforms state-of-the-art in-context learning methods, including the zero-shot capabilities of GPT-4o, particularly in complex scenarios. By conducting frame-level analysis on the Honda Scenes Dataset, which contains a collection of about 80 hours of annotated driving videos capturing diverse real-world road and weather conditions, our study highlights the robustness of CLIP models in learning visual concepts from natural language supervision. Results also showed that fine-tuning the CLIP models, such as ViT-L/14 and ViT-B/32, significantly improved scene classification, achieving a top F1 score of 91.1%. These results demonstrate the ability of the system to deliver rapid and precise scene recognition, which can be used to meet the critical requirements of Advanced Driver Assistance Systems (ADAS). This study shows the potential of CLIP models to provide scalable and efficient frameworks for dynamic scene understanding and classification. Furthermore, this work lays the groundwork for advanced autonomous vehicle technologies by fostering a deeper understanding of driver behavior, road conditions, and safety-critical scenarios, marking a significant step toward smarter, safer, and more context-aware autonomous driving systems.
Large Language Models (LLMs) as Traffic Control Systems at Urban Intersections: A New Paradigm
Nov 16, 2024



This study introduces a novel approach for traffic control systems by using Large Language Models (LLMs) as traffic controllers. The study utilizes their logical reasoning, scene understanding, and decision-making capabilities to optimize throughput and provide feedback based on traffic conditions in real-time. LLMs centralize traditionally disconnected traffic control processes and can integrate traffic data from diverse sources to provide context-aware decisions. LLMs can also deliver tailored outputs using various means such as wireless signals and visuals to drivers, infrastructures, and autonomous vehicles. To evaluate LLMs ability as traffic controllers, this study proposed a four-stage methodology. The methodology includes data creation and environment initialization, prompt engineering, conflict identification, and fine-tuning. We simulated multi-lane four-leg intersection scenarios and generates detailed datasets to enable conflict detection using LLMs and Python simulation as a ground truth. We used chain-of-thought prompts to lead LLMs in understanding the context, detecting conflicts, resolving them using traffic rules, and delivering context-sensitive traffic management solutions. We evaluated the prformance GPT-mini, Gemini, and Llama as traffic controllers. Results showed that the fine-tuned GPT-mini achieved 83% accuracy and an F1-score of 0.84. GPT-mini model exhibited a promising performance in generating actionable traffic management insights, with high ROUGE-L scores across conflict identification of 0.95, decision-making of 0.91, priority assignment of 0.94, and waiting time optimization of 0.92. We demonstrated that LLMs can offer precise recommendations to drivers in real-time including yielding, slowing, or stopping based on vehicle dynamics.
Advancing Object Detection in Transportation with Multimodal Large Language Models (MLLMs): A Comprehensive Review and Empirical Testing
Sep 26, 2024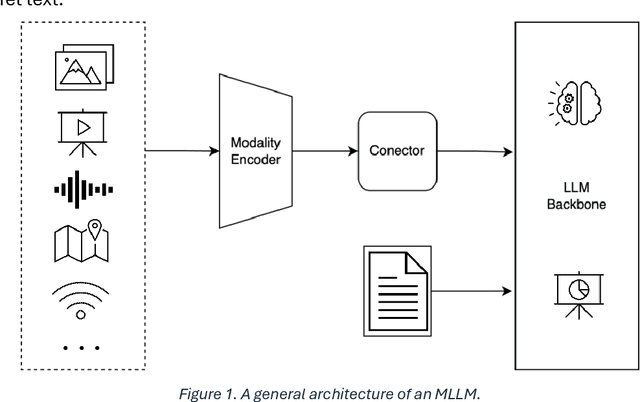
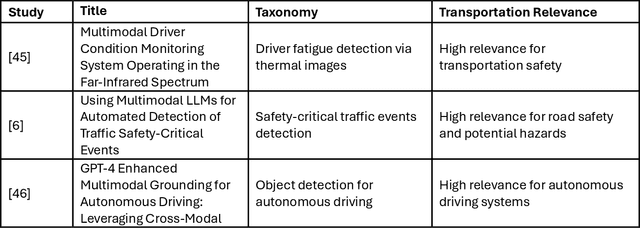
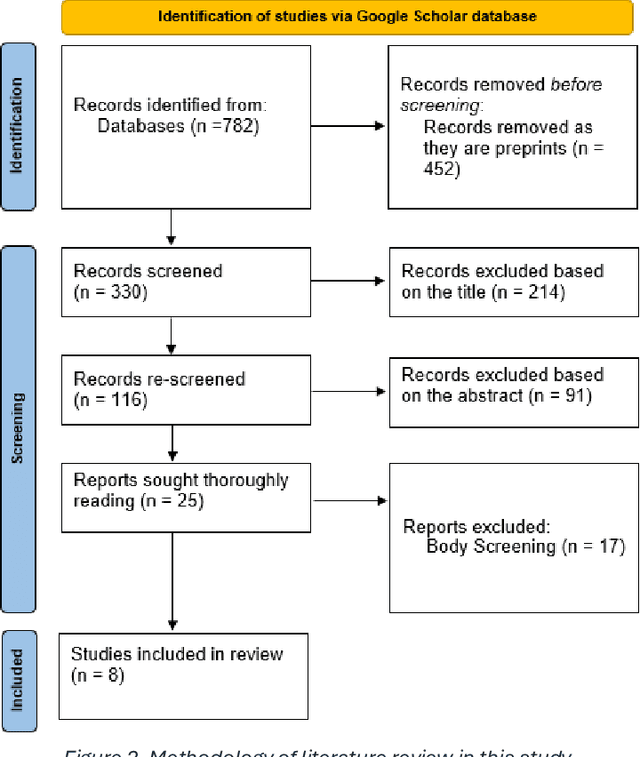
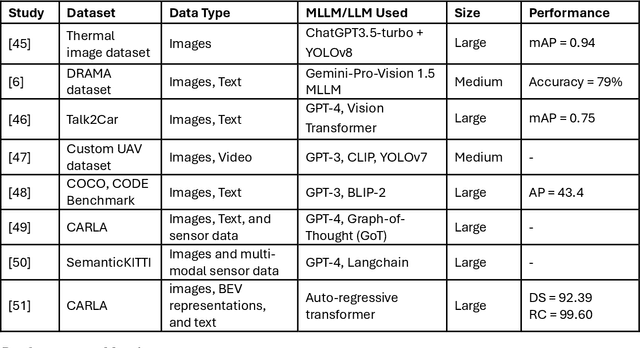
This study aims to comprehensively review and empirically evaluate the application of multimodal large language models (MLLMs) and Large Vision Models (VLMs) in object detection for transportation systems. In the first fold, we provide a background about the potential benefits of MLLMs in transportation applications and conduct a comprehensive review of current MLLM technologies in previous studies. We highlight their effectiveness and limitations in object detection within various transportation scenarios. The second fold involves providing an overview of the taxonomy of end-to-end object detection in transportation applications and future directions. Building on this, we proposed empirical analysis for testing MLLMs on three real-world transportation problems that include object detection tasks namely, road safety attributes extraction, safety-critical event detection, and visual reasoning of thermal images. Our findings provide a detailed assessment of MLLM performance, uncovering both strengths and areas for improvement. Finally, we discuss practical limitations and challenges of MLLMs in enhancing object detection in transportation, thereby offering a roadmap for future research and development in this critical area.
Leveraging Large Language Models (LLMs) for Traffic Management at Urban Intersections: The Case of Mixed Traffic Scenarios
Aug 01, 2024



Urban traffic management faces significant challenges due to the dynamic environments, and traditional algorithms fail to quickly adapt to this environment in real-time and predict possible conflicts. This study explores the ability of a Large Language Model (LLM), specifically, GPT-4o-mini to improve traffic management at urban intersections. We recruited GPT-4o-mini to analyze, predict position, detect and resolve the conflicts at an intersection in real-time for various basic scenarios. The key findings of this study to investigate whether LLMs can logically reason and understand the scenarios to enhance the traffic efficiency and safety by providing real-time analysis. The study highlights the potential of LLMs in urban traffic management creating more intelligent and more adaptive systems. Results showed the GPT-4o-mini was effectively able to detect and resolve conflicts in heavy traffic, congestion, and mixed-speed conditions. The complex scenario of multiple intersections with obstacles and pedestrians saw successful conflict management as well. Results show that the integration of LLMs promises to improve the effectiveness of traffic control for safer and more efficient urban intersection management.
Visual Reasoning and Multi-Agent Approach in Multimodal Large Language Models (MLLMs): Solving TSP and mTSP Combinatorial Challenges
Jun 26, 2024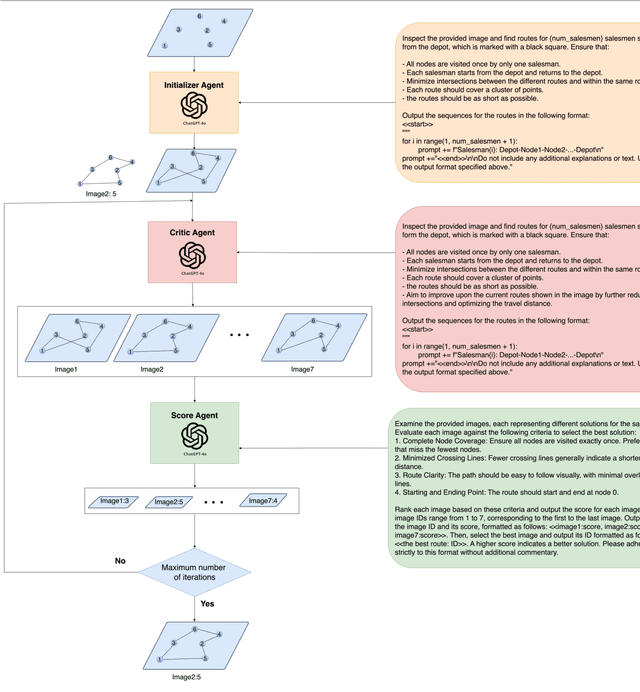
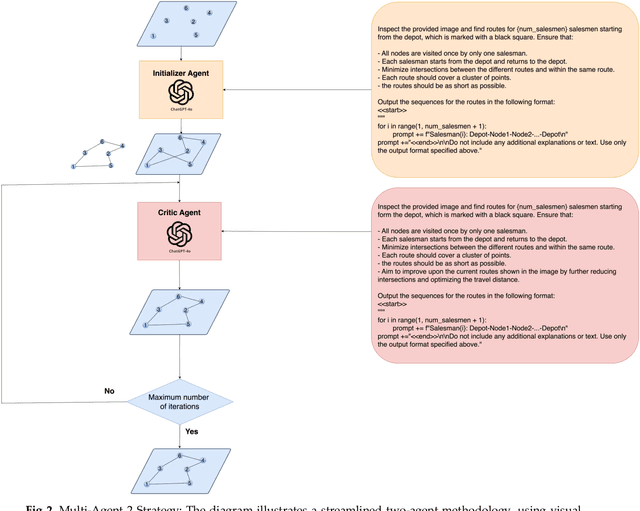
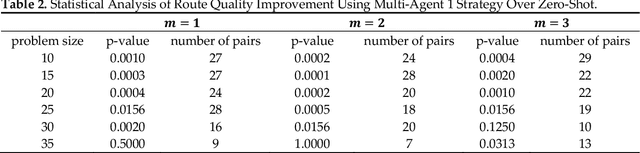
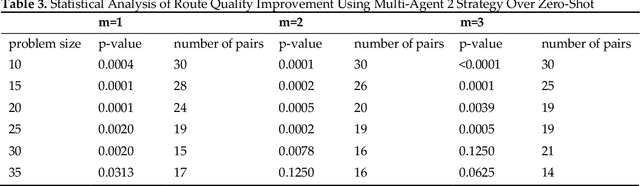
Multimodal Large Language Models (MLLMs) harness comprehensive knowledge spanning text, images, and audio to adeptly tackle complex problems, including zero-shot in-context learning scenarios. This study explores the ability of MLLMs in visually solving the Traveling Salesman Problem (TSP) and Multiple Traveling Salesman Problem (mTSP) using images that portray point distributions on a two-dimensional plane. We introduce a novel approach employing multiple specialized agents within the MLLM framework, each dedicated to optimizing solutions for these combinatorial challenges. Our experimental investigation includes rigorous evaluations across zero-shot settings and introduces innovative multi-agent zero-shot in-context scenarios. The results demonstrated that both multi-agent models. Multi-Agent 1, which includes the Initializer, Critic, and Scorer agents, and Multi-Agent 2, which comprises only the Initializer and Critic agents; significantly improved solution quality for TSP and mTSP problems. Multi-Agent 1 excelled in environments requiring detailed route refinement and evaluation, providing a robust framework for sophisticated optimizations. In contrast, Multi-Agent 2, focusing on iterative refinements by the Initializer and Critic, proved effective for rapid decision-making scenarios. These experiments yield promising outcomes, showcasing the robust visual reasoning capabilities of MLLMs in addressing diverse combinatorial problems. The findings underscore the potential of MLLMs as powerful tools in computational optimization, offering insights that could inspire further advancements in this promising field. Project link: https://github.com/ahmed-abdulhuy/Solving-TSP-and-mTSP-Combinatorial-Challenges-using-Visual-Reasoning-and-Multi-Agent-Approach-MLLMs-.git
The Use of Multimodal Large Language Models to Detect Objects from Thermal Images: Transportation Applications
Jun 20, 2024The integration of thermal imaging data with Multimodal Large Language Models (MLLMs) constitutes an exciting opportunity for improving the safety and functionality of autonomous driving systems and many Intelligent Transportation Systems (ITS) applications. This study investigates whether MLLMs can understand complex images from RGB and thermal cameras and detect objects directly. Our goals were to 1) assess the ability of the MLLM to learn from information from various sets, 2) detect objects and identify elements in thermal cameras, 3) determine whether two independent modality images show the same scene, and 4) learn all objects using different modalities. The findings showed that both GPT-4 and Gemini were effective in detecting and classifying objects in thermal images. Similarly, the Mean Absolute Percentage Error (MAPE) for pedestrian classification was 70.39% and 81.48%, respectively. Moreover, the MAPE for bike, car, and motorcycle detection were 78.4%, 55.81%, and 96.15%, respectively. Gemini produced MAPE of 66.53%, 59.35% and 78.18% respectively. This finding further demonstrates that MLLM can identify thermal images and can be employed in advanced imaging automation technologies for ITS applications.