 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Reasoning and Multi-Agent Approach in Multimodal Large Language Models (MLLMs): Solving TSP and mTSP Combinatorial Challenges
Jun 26, 2024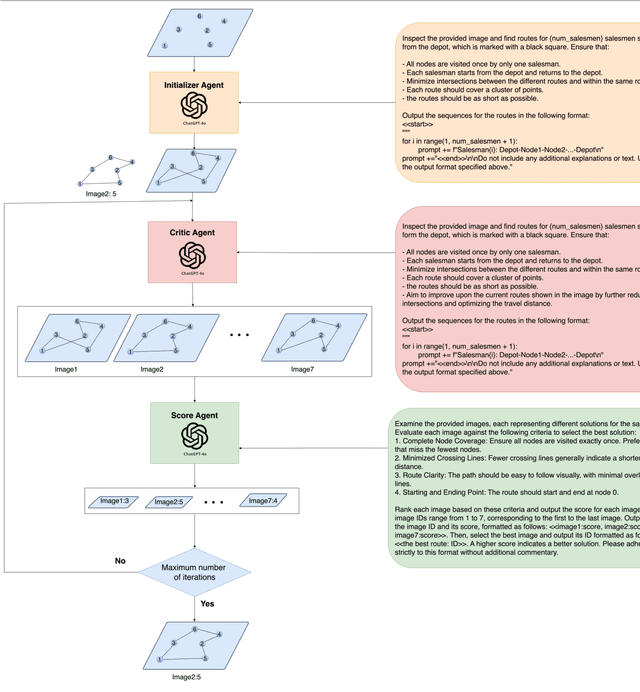
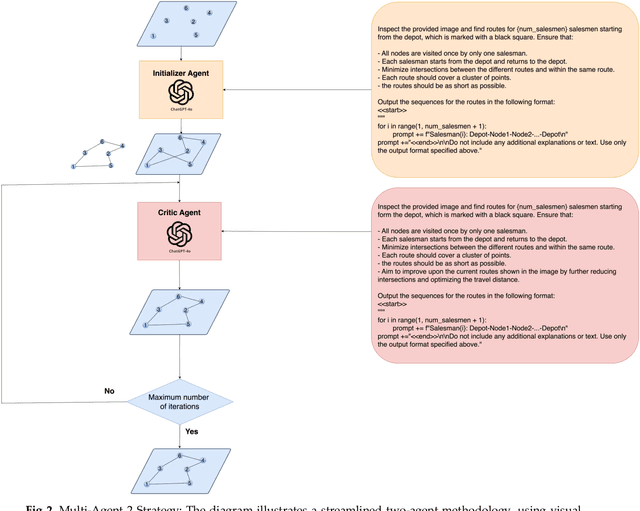
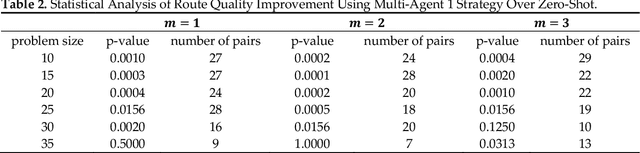
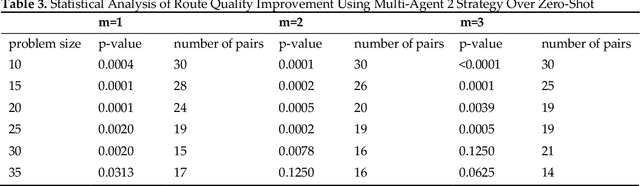
Multimodal Large Language Models (MLLMs) harness comprehensive knowledge spanning text, images, and audio to adeptly tackle complex problems, including zero-shot in-context learning scenarios. This study explores the ability of MLLMs in visually solving the Traveling Salesman Problem (TSP) and Multiple Traveling Salesman Problem (mTSP) using images that portray point distributions on a two-dimensional plane. We introduce a novel approach employing multiple specialized agents within the MLLM framework, each dedicated to optimizing solutions for these combinatorial challenges. Our experimental investigation includes rigorous evaluations across zero-shot settings and introduces innovative multi-agent zero-shot in-context scenarios. The results demonstrated that both multi-agent models. Multi-Agent 1, which includes the Initializer, Critic, and Scorer agents, and Multi-Agent 2, which comprises only the Initializer and Critic agents; significantly improved solution quality for TSP and mTSP problems. Multi-Agent 1 excelled in environments requiring detailed route refinement and evaluation, providing a robust framework for sophisticated optimizations. In contrast, Multi-Agent 2, focusing on iterative refinements by the Initializer and Critic, proved effective for rapid decision-making scenarios. These experiments yield promising outcomes, showcasing the robust visual reasoning capabilities of MLLMs in addressing diverse combinatorial problems. The findings underscore the potential of MLLMs as powerful tools in computational optimization, offering insights that could inspire further advancements in this promising field. Project link: https://github.com/ahmed-abdulhuy/Solving-TSP-and-mTSP-Combinatorial-Challenges-using-Visual-Reasoning-and-Multi-Agent-Approach-MLLMs-.git