 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Reasoning and Multi-Agent Approach in Multimodal Large Language Models (MLLMs): Solving TSP and mTSP Combinatorial Challenges
Jun 26, 2024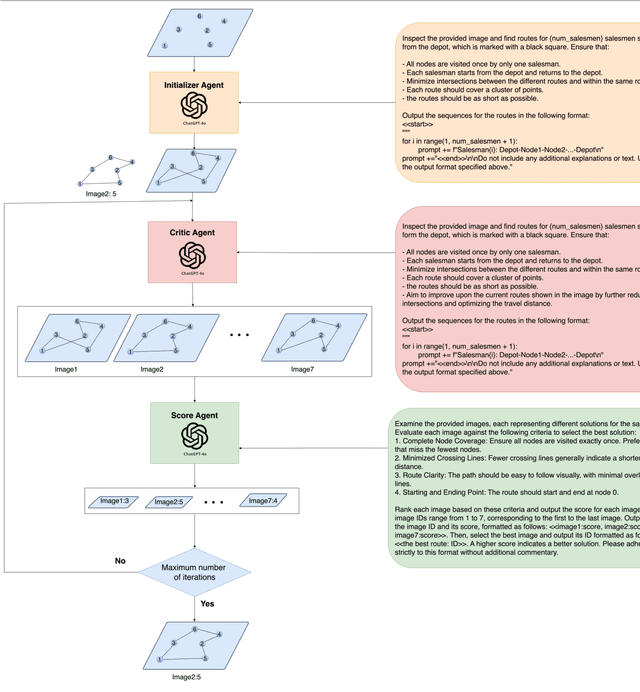
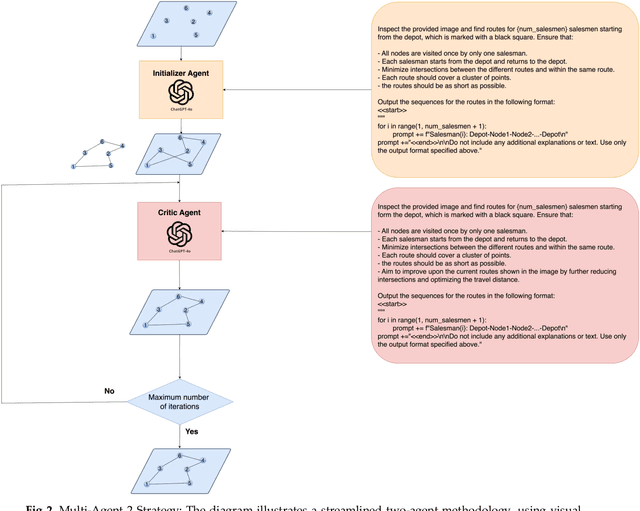
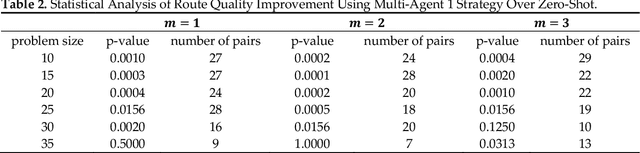
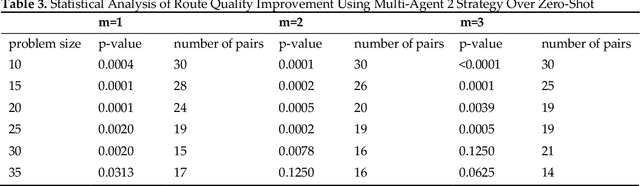
Multimodal Large Language Models (MLLMs) harness comprehensive knowledge spanning text, images, and audio to adeptly tackle complex problems, including zero-shot in-context learning scenarios. This study explores the ability of MLLMs in visually solving the Traveling Salesman Problem (TSP) and Multiple Traveling Salesman Problem (mTSP) using images that portray point distributions on a two-dimensional plane. We introduce a novel approach employing multiple specialized agents within the MLLM framework, each dedicated to optimizing solutions for these combinatorial challenges. Our experimental investigation includes rigorous evaluations across zero-shot settings and introduces innovative multi-agent zero-shot in-context scenarios. The results demonstrated that both multi-agent models. Multi-Agent 1, which includes the Initializer, Critic, and Scorer agents, and Multi-Agent 2, which comprises only the Initializer and Critic agents; significantly improved solution quality for TSP and mTSP problems. Multi-Agent 1 excelled in environments requiring detailed route refinement and evaluation, providing a robust framework for sophisticated optimizations. In contrast, Multi-Agent 2, focusing on iterative refinements by the Initializer and Critic, proved effective for rapid decision-making scenarios. These experiments yield promising outcomes, showcasing the robust visual reasoning capabilities of MLLMs in addressing diverse combinatorial problems. The findings underscore the potential of MLLMs as powerful tools in computational optimization, offering insights that could inspire further advancements in this promising field. Project link: https://github.com/ahmed-abdulhuy/Solving-TSP-and-mTSP-Combinatorial-Challenges-using-Visual-Reasoning-and-Multi-Agent-Approach-MLLMs-.git
Eyeballing Combinatorial Problems: A Case Study of Using Multimodal Large Language Models to Solve Traveling Salesman Problems
Jun 11, 2024



Multimodal Large Language Models (MLLMs) have demonstrated proficiency in processing di-verse modalities, including text, images, and audio. These models leverage extensive pre-existing knowledge, enabling them to address complex problems with minimal to no specific training examples, as evidenced in few-shot and zero-shot in-context learning scenarios. This paper investigates the use of MLLMs' visual capabilities to 'eyeball' solutions for the Traveling Salesman Problem (TSP) by analyzing images of point distributions on a two-dimensional plane. Our experiments aimed to validate the hypothesis that MLLMs can effectively 'eyeball' viable TSP routes. The results from zero-shot, few-shot, self-ensemble, and self-refine zero-shot evaluations show promising outcomes. We anticipate that these findings will inspire further exploration into MLLMs' visual reasoning abilities to tackle other combinatorial problems.
Exploring Combinatorial Problem Solving with Large Language Models: A Case Study on the Travelling Salesman Problem Using GPT-3.5 Turbo
May 03, 2024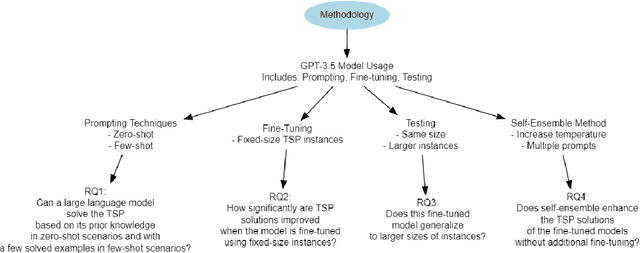
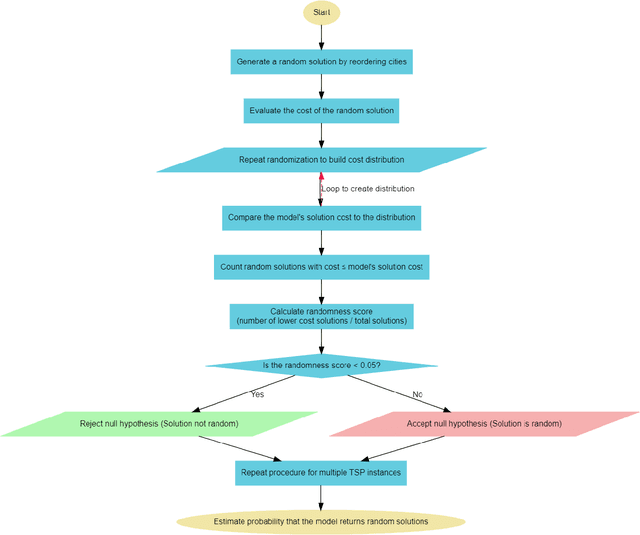
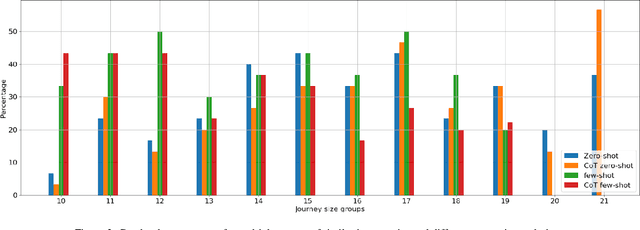
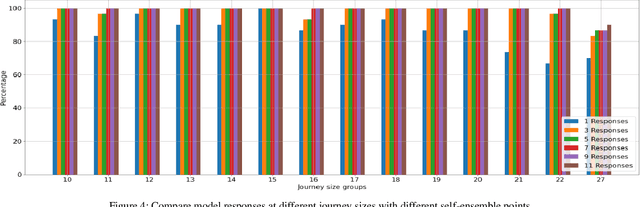
Large Language Models (LLMs) are deep learning models designed to generate text based on textual input. Although researchers have been developing these models for more complex tasks such as code generation and general reasoning, few efforts have explored how LLMs can be applied to combinatorial problems. In this research, we investigate the potential of LLMs to solve the Travelling Salesman Problem (TSP). Utilizing GPT-3.5 Turbo, we conducted experiments employing various approaches, including zero-shot in-context learning, few-shot in-context learning, and chain-of-thoughts (CoT). Consequently, we fine-tuned GPT-3.5 Turbo to solve a specific problem size and tested it using a set of various instance sizes. The fine-tuned models demonstrated promising performance on problems identical in size to the training instances and generalized well to larger problems. Furthermore, to improve the performance of the fine-tuned model without incurring additional training costs, we adopted a self-ensemble approach to improve the quality of the solutions.