 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Combinatorial Problem Solving with Large Language Models: A Case Study on the Travelling Salesman Problem Using GPT-3.5 Turbo
May 03, 2024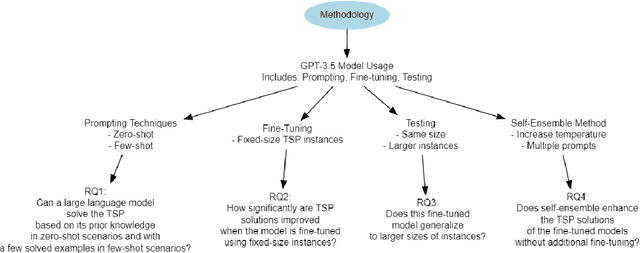
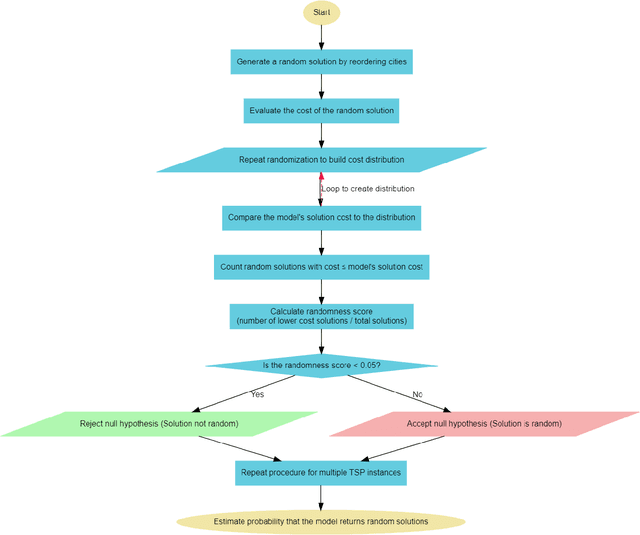
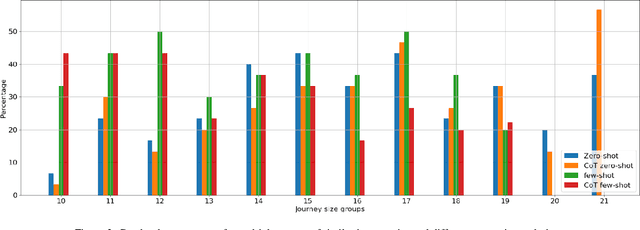
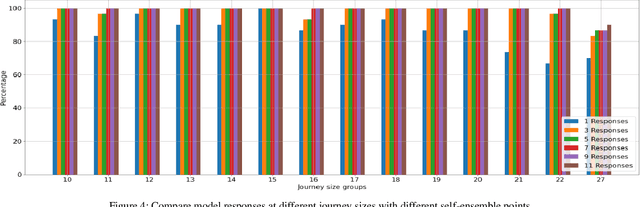
Large Language Models (LLMs) are deep learning models designed to generate text based on textual input. Although researchers have been developing these models for more complex tasks such as code generation and general reasoning, few efforts have explored how LLMs can be applied to combinatorial problems. In this research, we investigate the potential of LLMs to solve the Travelling Salesman Problem (TSP). Utilizing GPT-3.5 Turbo, we conducted experiments employing various approaches, including zero-shot in-context learning, few-shot in-context learning, and chain-of-thoughts (CoT). Consequently, we fine-tuned GPT-3.5 Turbo to solve a specific problem size and tested it using a set of various instance sizes. The fine-tuned models demonstrated promising performance on problems identical in size to the training instances and generalized well to larger problems. Furthermore, to improve the performance of the fine-tuned model without incurring additional training costs, we adopted a self-ensemble approach to improve the quality of the solutions.
Hybrid Pointer Networks for Traveling Salesman Problems Optimization
Oct 13, 2021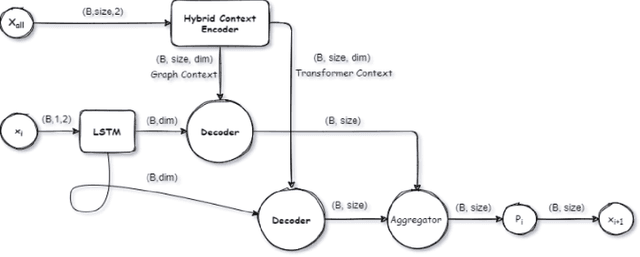
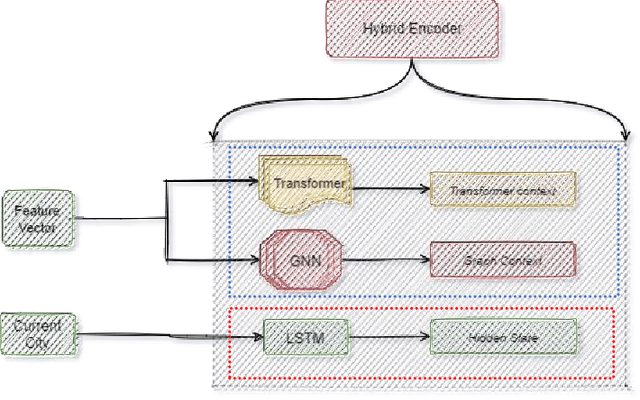
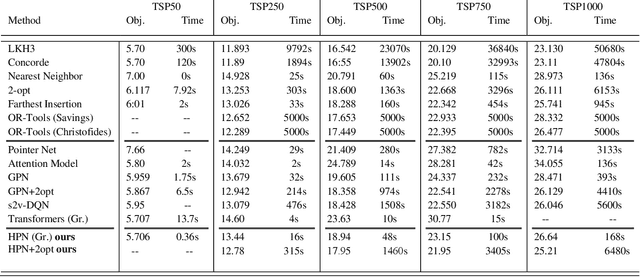
In this work, a novel idea is presented for combinatorial optimization problems, a hybrid network, which results in a superior outcome. We applied this method to graph pointer networks [1], expanding its capabilities to a higher level. We proposed a hybrid pointer network (HPN) to solve the travelling salesman problem trained by reinforcement learning. Furthermore, HPN builds upon graph pointer networks which is an extension of pointer networks with an additional graph embedding layer. HPN outperforms the graph pointer network in solution quality due to the hybrid encoder, which provides our model with a verity encoding type, allowing our model to converge to a better policy. Our network significantly outperforms the original graph pointer network for small and large-scale problems increasing its performance for TSP50 from 5.959 to 5.706 without utilizing 2opt, Pointer networks, Attention model, and a wide range of models, producing results comparable to highly tuned and specialized algorithms. We make our data, models, and code publicly available [2].
A Review on Drivers Red Light Running and Turning Behaviour Prediction
Aug 15, 2020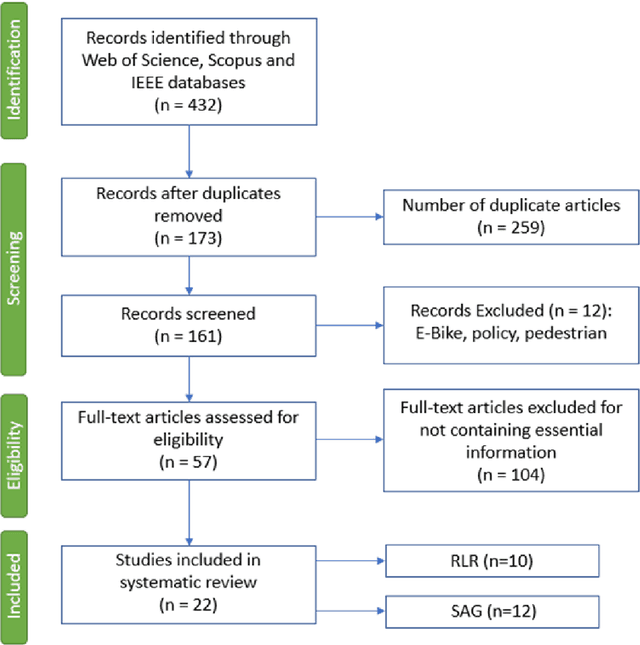


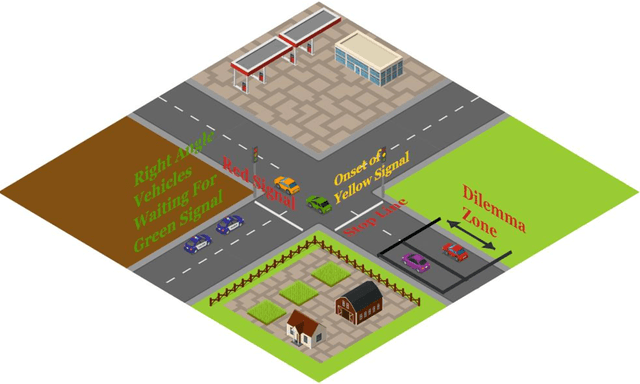
Drivers behaviour prediction has been an unceasing concern for transportation safety divisions all over the world. A massive amount of lives and properties losses due to the adversities at intersections and pedestrian crossings. Especially for countries with poor road safety technologies, this toll knows no bounds. A myriad of research and studies have been mastered for technological evaluation and model representation over this issue. Instead, little comprehensive review has been made on the drivers behaviour prediction at signalised intersections on red-light running and turning. This Paper aims at incorporating previous researches on drivers behaviour prediction and the prediction parameters leading to traffic violation like red-light running and turning at intersection and pedestrian crossing. The review also covers the probable crash scenarios by red-light running and turning and analyses the innovation of counter-crash technologies with future research directions.
Vulnerable Road User Detection Using Smartphone Sensors and Recurrence Quantification Analysis
Jun 12, 2020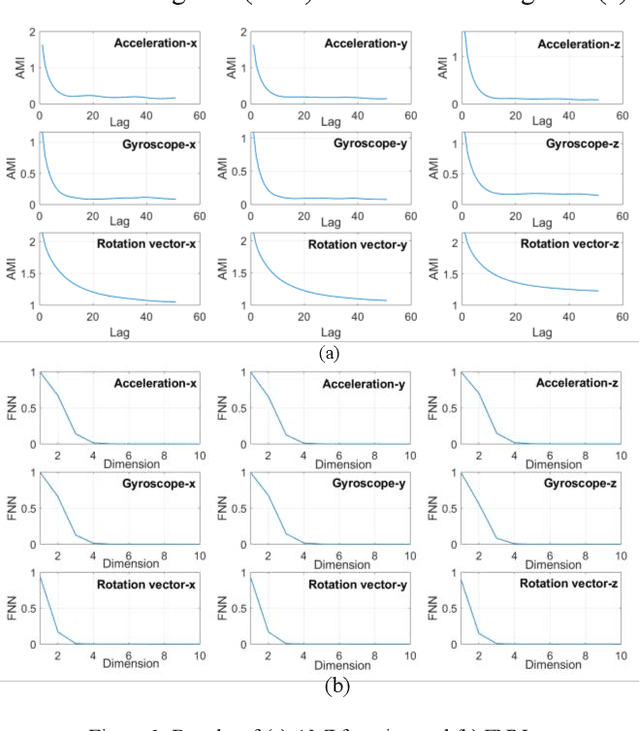
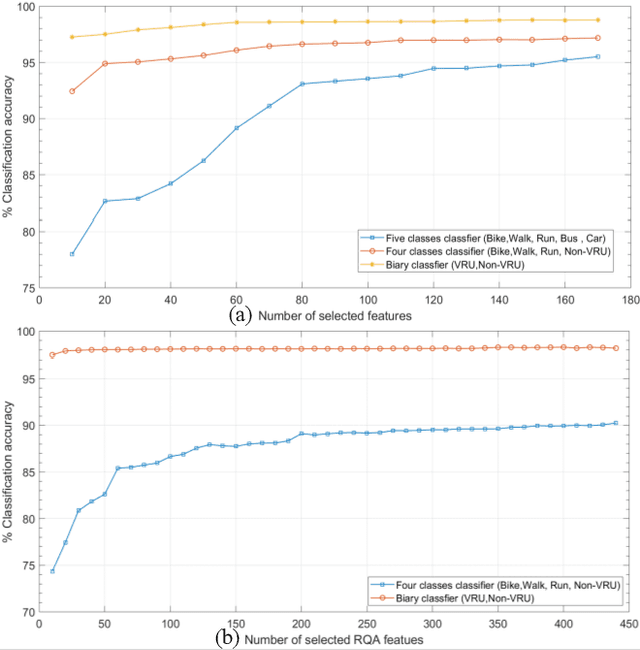

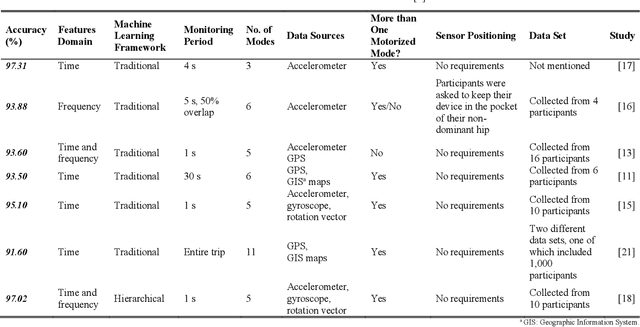
With the fast advancements of the Autonomous Vehicle (AV) industry, detection of Vulnerable Road Users (VRUs) using smartphones is critical for safety applications of Cooperative Intelligent Transportation Systems (C-ITSs). This study explores the use of low-power smartphone sensors and the Recurrence Quantification Analysis (RQA) features for this task. These features are computed over a thresholded similarity matrix extracted from nine channels: accelerometer, gyroscope, and rotation vector in each direction (x, y, and z). Given the high-power consumption of GPS, GPS data is excluded. RQA features are added to traditional time domain features to investigate the classification accuracy when using binary, four-class, and five-class Random Forest classifiers. Experimental results show a promising performance when only using RQA features with a resulted accuracy of 98. 34% and a 98. 79% by adding time domain features. Results outperform previous reported accuracy, demonstrating that RQA features have high classifying capability with respect to VRU detection.
* Published in: 2019 IEEE Intelligent Transportation Systems Conference (ITSC)
A Comparative Analysis of E-Scooter and E-Bike Usage Patterns: Findings from the City of Austin, TX
Jun 07, 2020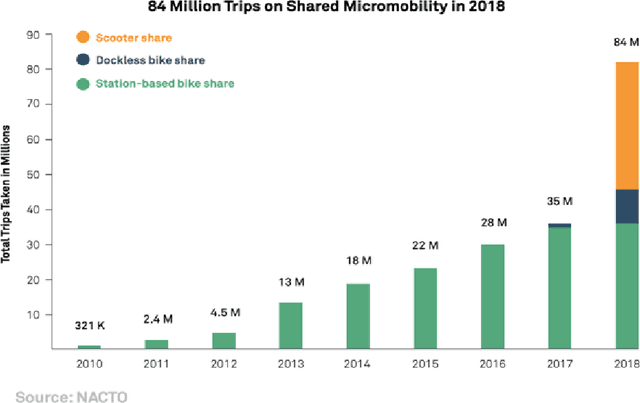
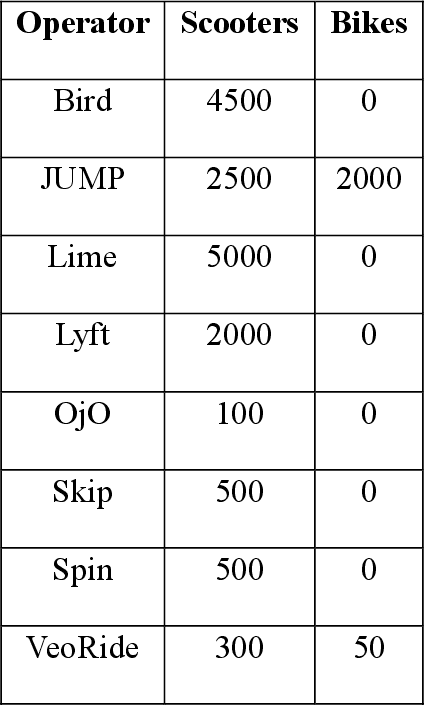
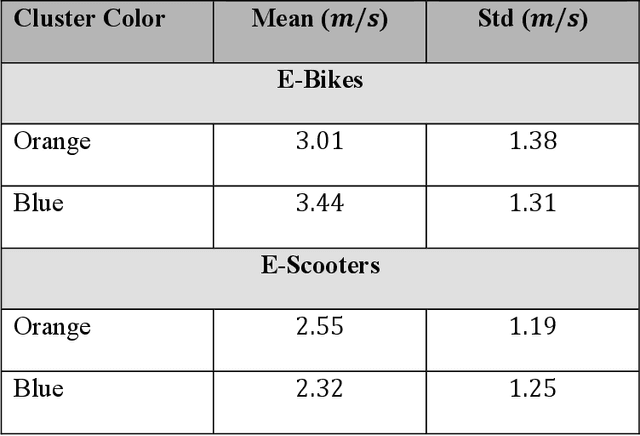
E-scooter-sharing and e-bike-sharing systems are accommodating and easing the increased traffic in dense cities and are expanding considerably. However, these new micro-mobility transportation modes raise numerous operational and safety concerns. This study analyzes e-scooter and dockless e-bike sharing system user behavior. We investigate how average trip speed change depending on the day of the week and the time of the day. We used a dataset from the city of Austin, TX from December 2018 to May 2019. Our results generally show that the trip average speed for e-bikes ranges between 3.01 and 3.44 m/s, which is higher than that for e-scooters (2.19 to 2.78 m/s). Results also show a similar usage pattern for the average speed of e-bikes and e-scooters throughout the days of the week and a different usage pattern for the average speed of e-bikes and e-scooters over the hours of the day. We found that users tend to ride e-bikes and e-scooters with a slower average speed for recreational purposes compared to when they are ridden for commuting purposes. This study is a building block in this field, which serves as a first of its kind, and sheds the light of significant new understanding of this emerging class of shared-road users.
Topological Stability: a New Algorithm for Selecting The Nearest Neighbors in Non-Linear Dimensionality Reduction Techniques
Nov 17, 2019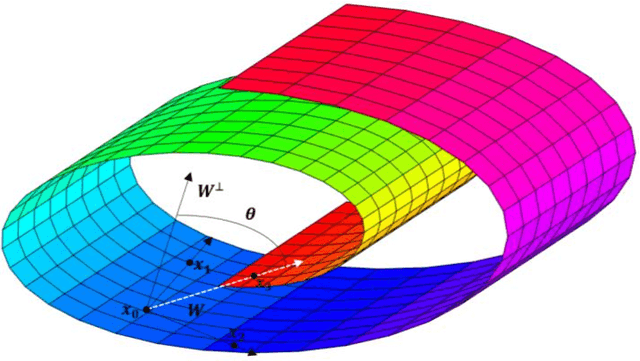
In the machine learning field, dimensionality reduction is an important task. It mitigates the undesired properties of high-dimensional spaces to facilitate classification, compression, and visualization of high-dimensional data. During the last decade, researchers proposed many new (non-linear) techniques for dimensionality reduction. Most of these techniques are based on the intuition that data lies on or near a complex low-dimensional manifold that is embedded in the high-dimensional space. New techniques for dimensionality reduction aim at identifying and extracting the manifold from the high-dimensional space. Isomap is one of widely-used low-dimensional embedding methods, where geodesic distances on a weighted graph are incorporated with the classical scaling (metric multidimensional scaling). The Isomap chooses the nearest neighbours based on the distance only which causes bridges and topological instability. In this paper, we propose a new algorithm to choose the nearest neighbours to reduce the number of short-circuit errors and hence improves the topological stability. Because at any point on the manifold, that point and its nearest neighbours form a vector subspace and the orthogonal to that subspace is orthogonal to all vectors spans the vector subspace. The prposed algorithmuses the point itself and its two nearest neighbours to find the bases of the subspace and the orthogonal to that subspace which belongs to the orthogonal complementary subspace. The proposed algorithm then adds new points to the two nearest neighbours based on the distance and the angle between each new point and the orthogonal to the subspace. The superior performance of the new algorithm in choosing the nearest neighbours is confirmed through experimental work with several datasets.