 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Coordinated Actuated Traffic Signal Change Times using LSTM Neural Networks
Aug 10, 2020



Vehicle acceleration and deceleration maneuvers at traffic signals results in significant fuel and energy consumption levels. Green light optimal speed advisory systems require reliable estimates of signal switching times to improve vehicle fuel efficiency. Obtaining these estimates is difficult for actuated signals where the length of each green indication changes to accommodate varying traffic conditions. This study details a four-step Long Short-Term Memory deep learning-based methodology that can be used to provide reasonable switching time estimates from green to red and vice versa while being robust to missing data. The four steps are data gathering, data preparation, machine learning model tuning, and model testing and evaluation. The input to the models included controller logic, signal timing parameters, time of day, traffic state from detectors, vehicle actuation data, and pedestrian actuation data. The methodology is applied and evaluated on data from an intersection in Northern Virginia. A comparative analysis is conducted between different loss functions including the mean squared error, mean absolute error, and mean relative error used in LSTM and a new loss function is proposed. The results show that while the proposed loss function outperforms conventional loss functions in terms of overall absolute error values, the choice of the loss function is dependent on the prediction horizon. In particular, the proposed loss function is outperformed by the mean relative error for very short prediction horizons and mean squared error for very long prediction horizons.
Modeling bike counts in a bike-sharing system considering the effect of weather conditions
Jun 13, 2020



The paper develops a method that quantifies the effect of weather conditions on the prediction of bike station counts in the San Francisco Bay Area Bike Share System. The Random Forest technique was used to rank the predictors that were then used to develop a regression model using a guided forward step-wise regression approach. The Bayesian Information Criterion was used in the development and comparison of the various prediction models. We demonstrated that the proposed approach is promising to quantify the effect of various features on a large BSS and on each station in cases of large networks with big data. The results show that the time-of-the-day, temperature, and humidity level (which has not been studied before) are significant count predictors. It also shows that as weather variables are geographic location dependent and thus should be quantified before using them in modeling. Further, findings show that the number of available bikes at station i at time t-1 and time-of-the-day were the most significant variables in estimating the bike counts at station i.
* Published in Case Studies on Transport Policy (Volume 7, Issue 2, June 2019, Pages 261-268)
Smartphone Transportation Mode Recognition Using a Hierarchical Machine Learning Classifier and Pooled Features From Time and Frequency Domains
Jun 12, 2020



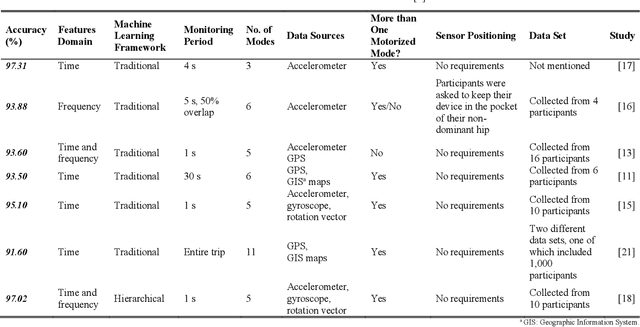
This paper develops a novel two-layer hierarchical classifier that increases the accuracy of traditional transportation mode classification algorithms. This paper also enhances classification accuracy by extracting new frequency domain features. Many researchers have obtained these features from global positioning system data; however, this data was excluded in this paper, as the system use might deplete the smartphone's battery and signals may be lost in some areas. Our proposed two-layer framework differs from previous classification attempts in three distinct ways: 1) the outputs of the two layers are combined using Bayes' rule to choose the transportation mode with the largest posterior probability; 2) the proposed framework combines the new extracted features with traditionally used time domain features to create a pool of features; and 3) a different subset of extracted features is used in each layer based on the classified modes. Several machine learning techniques were used, including k-nearest neighbor, classification and regression tree, support vector machine, random forest, and a heterogeneous framework of random forest and support vector machine. Results show that the classification accuracy of the proposed framework outperforms traditional approaches. Transforming the time domain features to the frequency domain also adds new features in a new space and provides more control on the loss of information. Consequently, combining the time domain and the frequency domain features in a large pool and then choosing the best subset results in higher accuracy than using either domain alone. The proposed two-layer classifier obtained a maximum classification accuracy of 97.02%.
Modeling bike availability in a bike-sharing system using machine learning
Jun 12, 2020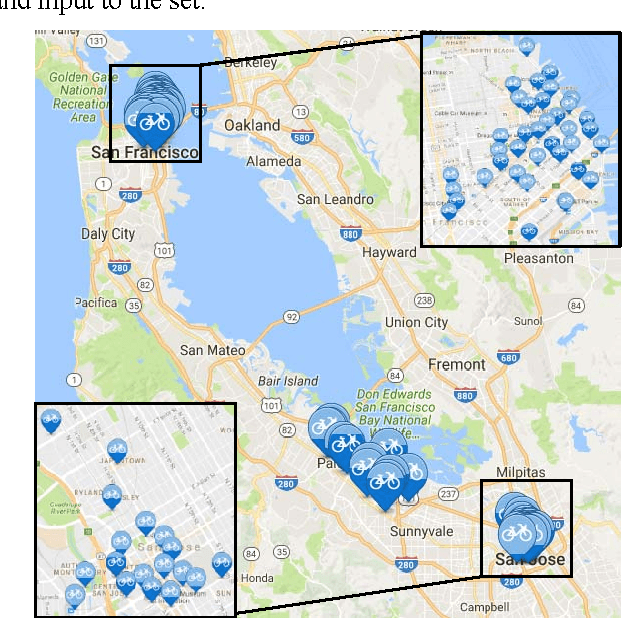

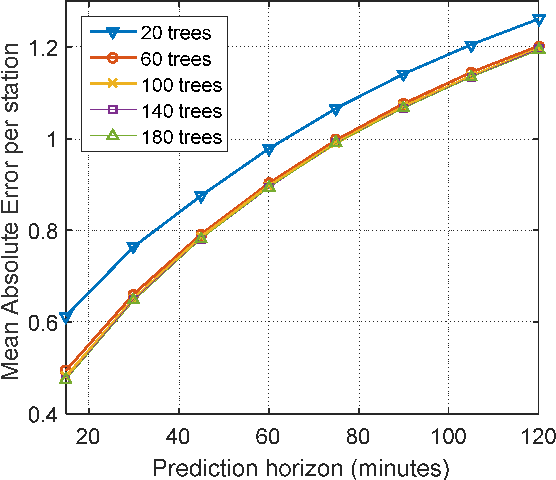
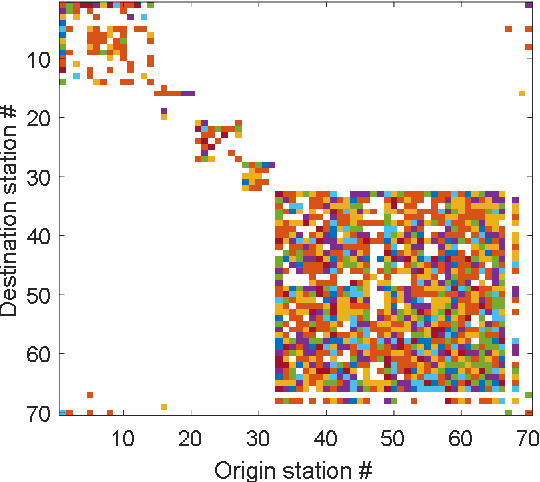
This paper models the availability of bikes at San Francisco Bay Area Bike Share stations using machine learning algorithms. Random Forest (RF) and Least-Squares Boosting (LSBoost) were used as univariate regression algorithms, and Partial Least-Squares Regression (PLSR) was applied as a multivariate regression algorithm. The univariate models were used to model the number of available bikes at each station. PLSR was applied to reduce the number of required prediction models and reflect the spatial correlation between stations in the network. Results clearly show that univariate models have lower error predictions than the multivariate model. However, the multivariate model results are reasonable for networks with a relatively large number of spatially correlated stations. Results also show that station neighbors and the prediction horizon time are significant predictors. The most effective prediction horizon time that produced the least prediction error was 15 minutes.
* Published in: 2017 5th IEEE International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS)
Vulnerable Road User Detection Using Smartphone Sensors and Recurrence Quantification Analysis
Jun 12, 2020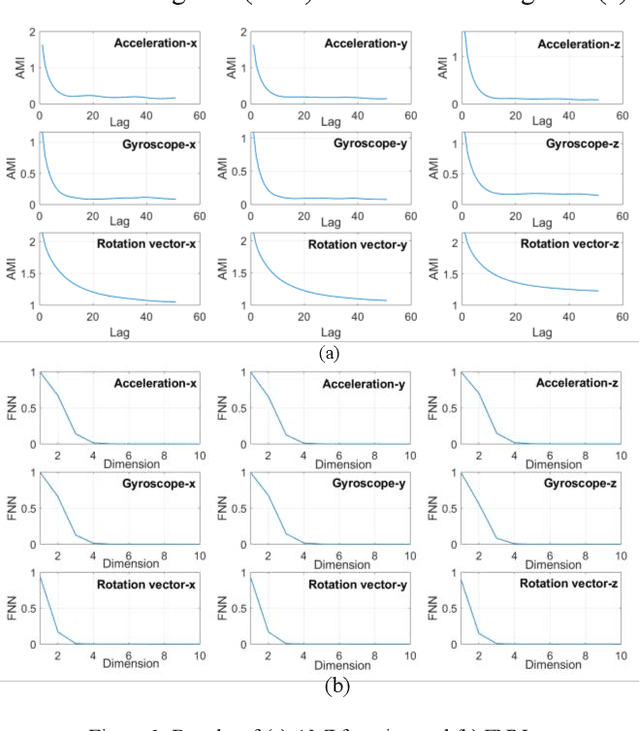
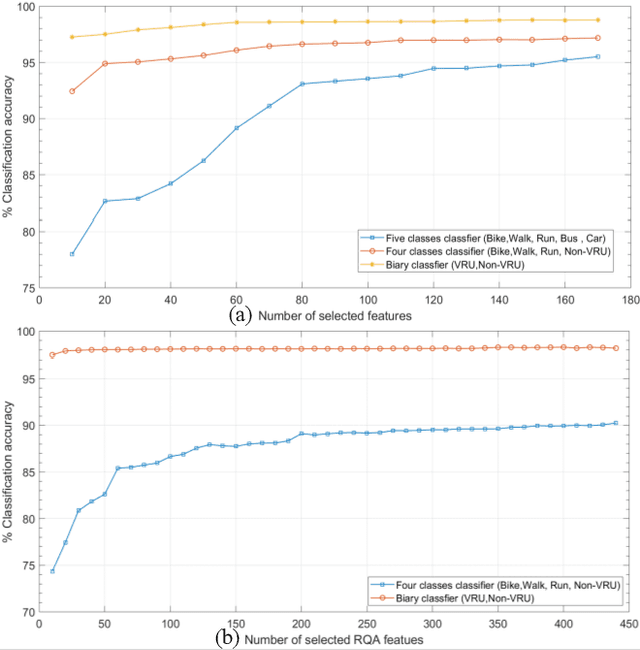

With the fast advancements of the Autonomous Vehicle (AV) industry, detection of Vulnerable Road Users (VRUs) using smartphones is critical for safety applications of Cooperative Intelligent Transportation Systems (C-ITSs). This study explores the use of low-power smartphone sensors and the Recurrence Quantification Analysis (RQA) features for this task. These features are computed over a thresholded similarity matrix extracted from nine channels: accelerometer, gyroscope, and rotation vector in each direction (x, y, and z). Given the high-power consumption of GPS, GPS data is excluded. RQA features are added to traditional time domain features to investigate the classification accuracy when using binary, four-class, and five-class Random Forest classifiers. Experimental results show a promising performance when only using RQA features with a resulted accuracy of 98. 34% and a 98. 79% by adding time domain features. Results outperform previous reported accuracy, demonstrating that RQA features have high classifying capability with respect to VRU detection.
* Published in: 2019 IEEE Intelligent Transportation Systems Conference (ITSC)