 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Large Language Models for Enhanced Traffic Safety: A Comprehensive Review and Future Trends
Apr 21, 2025Traffic safety remains a critical global challenge, with traditional Advanced Driver-Assistance Systems (ADAS) often struggling in dynamic real-world scenarios due to fragmented sensor processing and susceptibility to adversarial conditions. This paper reviews the transformative potential of Multimodal Large Language Models (MLLMs) in addressing these limitations by integrating cross-modal data such as visual, spatial, and environmental inputs to enable holistic scene understanding. Through a comprehensive analysis of MLLM-based approaches, we highlight their capabilities in enhancing perception, decision-making, and adversarial robustness, while also examining the role of key datasets (e.g., KITTI, DRAMA, ML4RoadSafety) in advancing research. Furthermore, we outline future directions, including real-time edge deployment, causality-driven reasoning, and human-AI collaboration. By positioning MLLMs as a cornerstone for next-generation traffic safety systems, this review underscores their potential to revolutionize the field, offering scalable, context-aware solutions that proactively mitigate risks and improve overall road safety.
Malware Classification from Memory Dumps Using Machine Learning, Transformers, and Large Language Models
Mar 04, 2025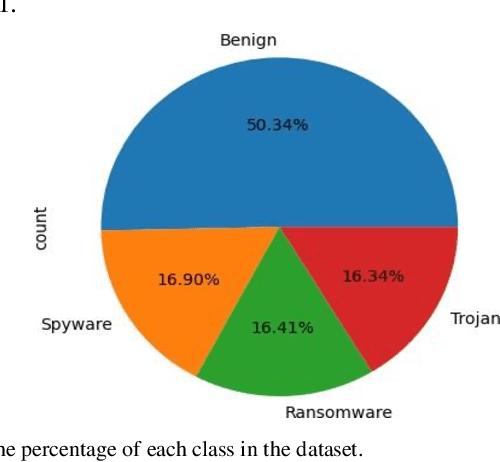
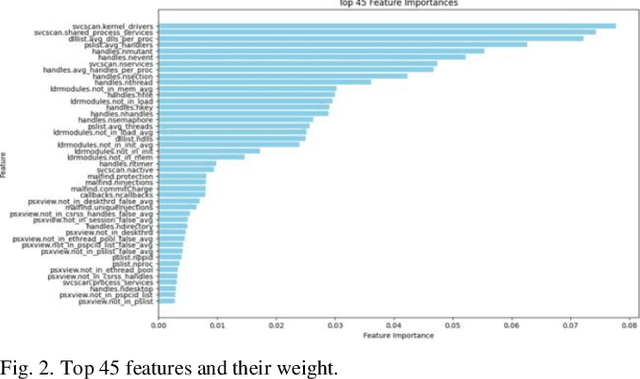
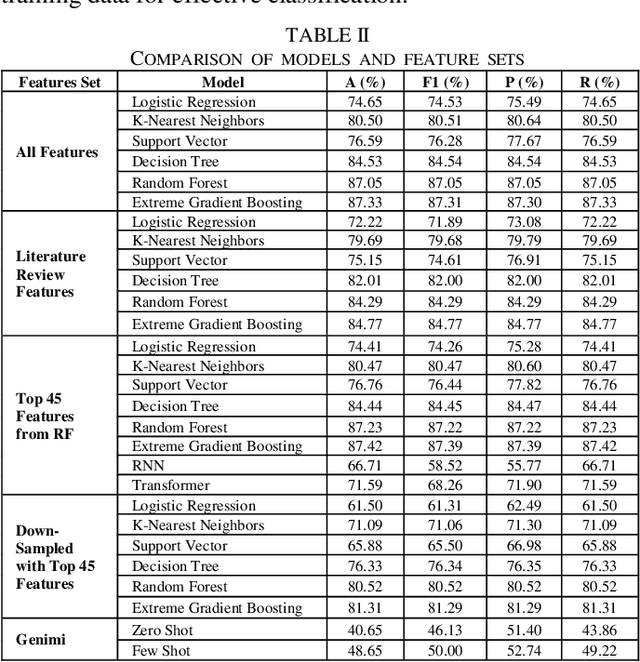
This study investigates the performance of various classification models for a malware classification task using different feature sets and data configurations. Six models-Logistic Regression, K-Nearest Neighbors (KNN), Support Vector Machines (SVM), Decision Trees, Random Forest (RF), and Extreme Gradient Boosting (XGB)-were evaluated alongside two deep learning models, Recurrent Neural Networks (RNN) and Transformers, as well as the Gemini zero-shot and few-shot learning methods. Four feature sets were tested including All Features, Literature Review Features, the Top 45 Features from RF, and Down-Sampled with Top 45 Features. XGB achieved the highest accuracy of 87.42% using the Top 45 Features, outperforming all other models. RF followed closely with 87.23% accuracy on the same feature set. In contrast, deep learning models underperformed, with RNN achieving 66.71% accuracy and Transformers reaching 71.59%. Down-sampling reduced performance across all models, with XGB dropping to 81.31%. Gemini zero-shot and few-shot learning approaches showed the lowest performance, with accuracies of 40.65% and 48.65%, respectively. The results highlight the importance of feature selection in improving model performance while reducing computational complexity. Traditional models like XGB and RF demonstrated superior performance, while deep learning and few-shot methods struggled to match their accuracy. This study underscores the effectiveness of traditional machine learning models for structured datasets and provides a foundation for future research into hybrid approaches and larger datasets.
Network Traffic Classification Using Machine Learning, Transformer, and Large Language Models
Mar 04, 2025
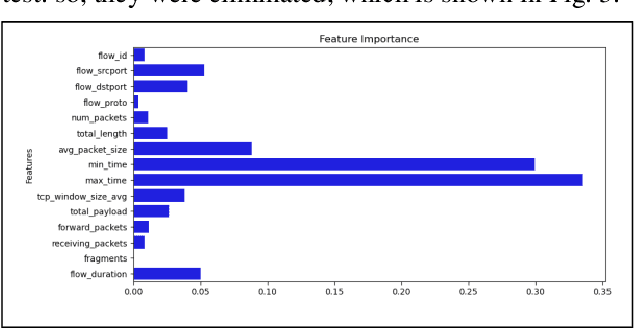
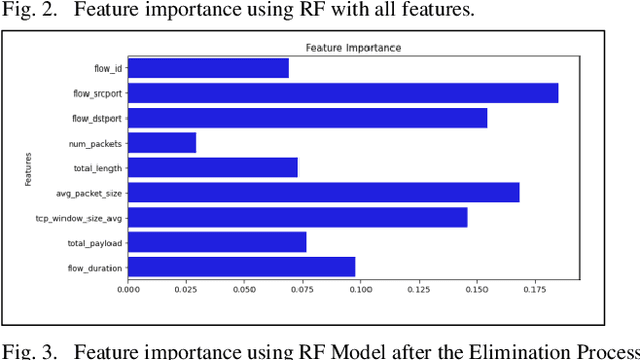
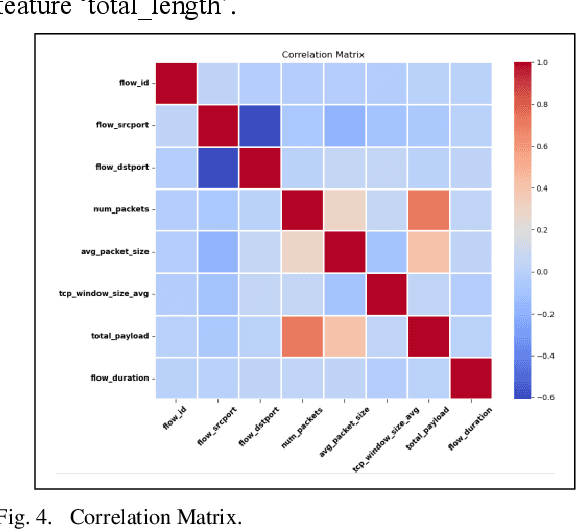
This study uses various models to address network traffic classification, categorizing traffic into web, browsing, IPSec, backup, and email. We collected a comprehensive dataset from Arbor Edge Defender (AED) devices, comprising of 30,959 observations and 19 features. Multiple models were evaluated, including Naive Bayes, Decision Tree, Random Forest, Gradient Boosting, XGBoost, Deep Neural Networks (DNN), Transformer, and two Large Language Models (LLMs) including GPT-4o and Gemini with zero- and few-shot learning. Transformer and XGBoost showed the best performance, achieving the highest accuracy of 98.95 and 97.56%, respectively. GPT-4o and Gemini showed promising results with few-shot learning, improving accuracy significantly from initial zero-shot performance. While Gemini Few-Shot and GPT-4o Few-Shot performed well in categories like Web and Email, misclassifications occurred in more complex categories like IPSec and Backup. The study highlights the importance of model selection, fine-tuning, and the balance between training data size and model complexity for achieving reliable classification results.
Visual Reasoning at Urban Intersections: FineTuning GPT-4o for Traffic Conflict Detection
Feb 27, 2025Traffic control in unsignalized urban intersections presents significant challenges due to the complexity, frequent conflicts, and blind spots. This study explores the capability of leveraging Multimodal Large Language Models (MLLMs), such as GPT-4o, to provide logical and visual reasoning by directly using birds-eye-view videos of four-legged intersections. In this proposed method, GPT-4o acts as intelligent system to detect conflicts and provide explanations and recommendations for the drivers. The fine-tuned model achieved an accuracy of 77.14%, while the manual evaluation of the true predicted values of the fine-tuned GPT-4o showed significant achievements of 89.9% accuracy for model-generated explanations and 92.3% for the recommended next actions. These results highlight the feasibility of using MLLMs for real-time traffic management using videos as inputs, offering scalable and actionable insights into intersections traffic management and operation. Code used in this study is available at https://github.com/sarimasri3/Traffic-Intersection-Conflict-Detection-using-images.git.
HazardNet: A Small-Scale Vision Language Model for Real-Time Traffic Safety Detection at Edge Devices
Feb 27, 2025



Traffic safety remains a vital concern in contemporary urban settings, intensified by the increase of vehicles and the complicated nature of road networks. Traditional safety-critical event detection systems predominantly rely on sensor-based approaches and conventional machine learning algorithms, necessitating extensive data collection and complex training processes to adhere to traffic safety regulations. This paper introduces HazardNet, a small-scale Vision Language Model designed to enhance traffic safety by leveraging the reasoning capabilities of advanced language and vision models. We built HazardNet by fine-tuning the pre-trained Qwen2-VL-2B model, chosen for its superior performance among open-source alternatives and its compact size of two billion parameters. This helps to facilitate deployment on edge devices with efficient inference throughput. In addition, we present HazardQA, a novel Vision Question Answering (VQA) dataset constructed specifically for training HazardNet on real-world scenarios involving safety-critical events. Our experimental results show that the fine-tuned HazardNet outperformed the base model up to an 89% improvement in F1-Score and has comparable results with improvement in some cases reach up to 6% when compared to larger models, such as GPT-4o. These advancements underscore the potential of HazardNet in providing real-time, reliable traffic safety event detection, thereby contributing to reduced accidents and improved traffic management in urban environments. Both HazardNet model and the HazardQA dataset are available at https://huggingface.co/Tami3/HazardNet and https://huggingface.co/datasets/Tami3/HazardQA, respectively.
Towards Equitable AI: Detecting Bias in Using Large Language Models for Marketing
Feb 18, 2025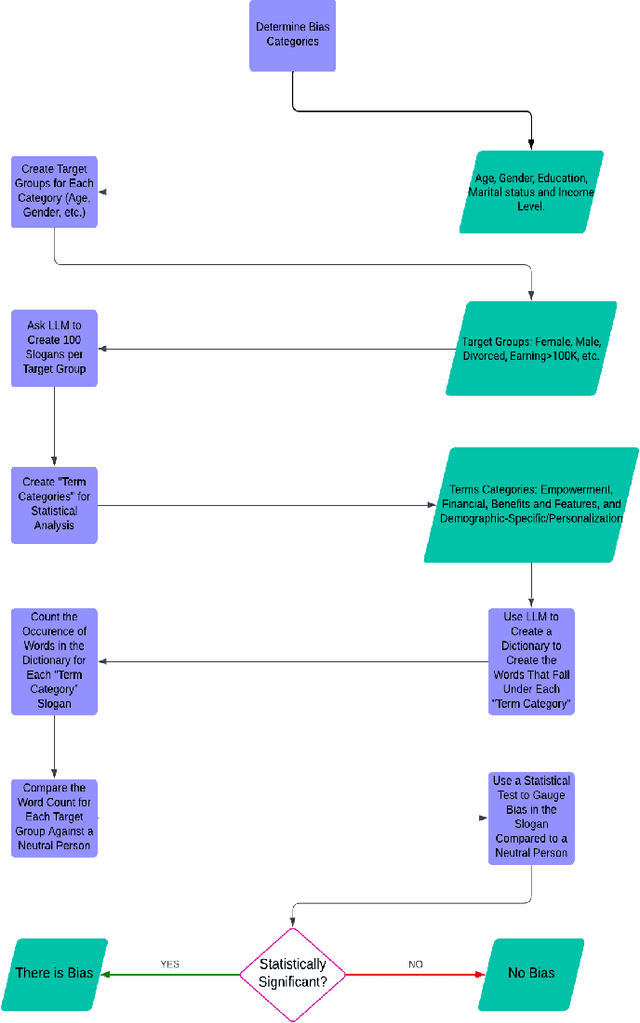
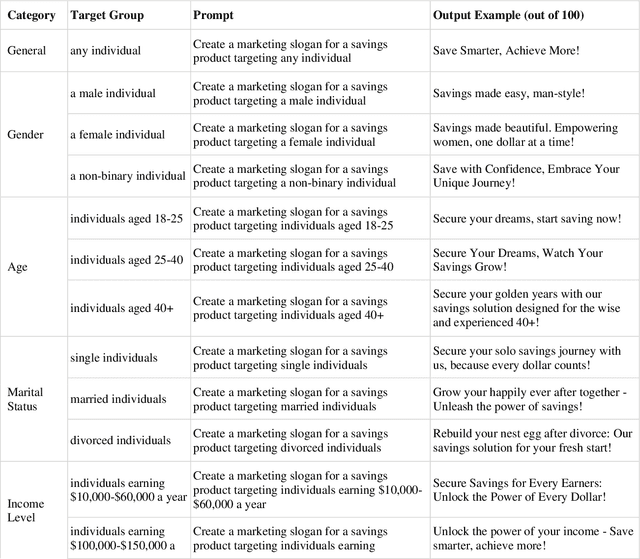
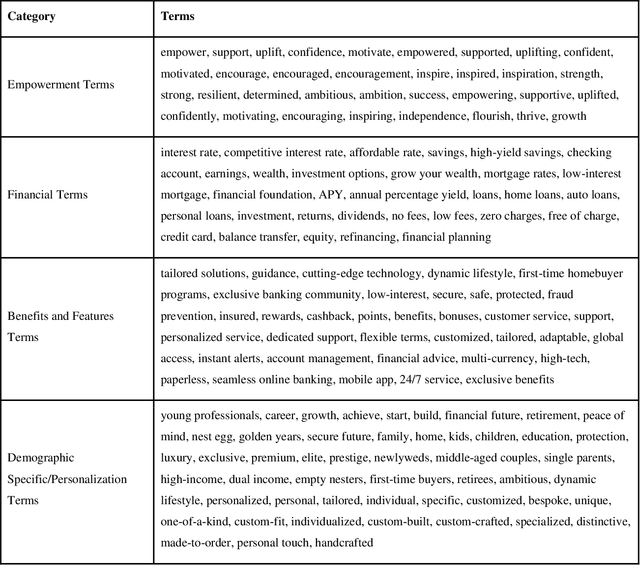
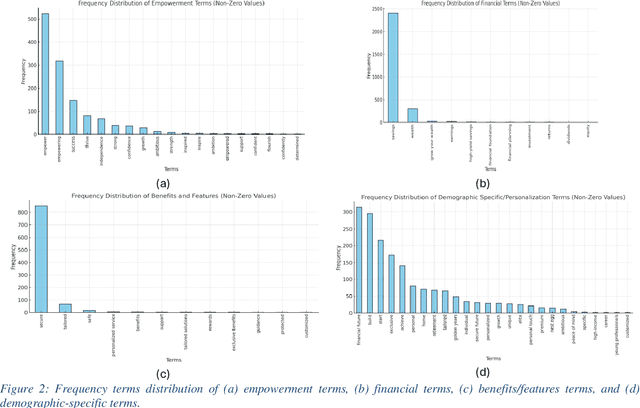
The recent advances in large language models (LLMs) have revolutionized industries such as finance, marketing, and customer service by enabling sophisticated natural language processing tasks. However, the broad adoption of LLMs brings significant challenges, particularly in the form of social biases that can be embedded within their outputs. Biases related to gender, age, and other sensitive attributes can lead to unfair treatment, raising ethical concerns and risking both company reputation and customer trust. This study examined bias in finance-related marketing slogans generated by LLMs (i.e., ChatGPT) by prompting tailored ads targeting five demographic categories: gender, marital status, age, income level, and education level. A total of 1,700 slogans were generated for 17 unique demographic groups, and key terms were categorized into four thematic groups: empowerment, financial, benefits and features, and personalization. Bias was systematically assessed using relative bias calculations and statistically tested with the Kolmogorov-Smirnov (KS) test against general slogans generated for any individual. Results revealed that marketing slogans are not neutral; rather, they emphasize different themes based on demographic factors. Women, younger individuals, low-income earners, and those with lower education levels receive more distinct messaging compared to older, higher-income, and highly educated individuals. This underscores the need to consider demographic-based biases in AI-generated marketing strategies and their broader societal implications. The findings of this study provide a roadmap for developing more equitable AI systems, highlighting the need for ongoing bias detection and mitigation efforts in LLMs.
Vision-Language Models for Autonomous Driving: CLIP-Based Dynamic Scene Understanding
Jan 09, 2025



Scene understanding is essential for enhancing driver safety, generating human-centric explanations for Automated Vehicle (AV) decisions, and leveraging Artificial Intelligence (AI) for retrospective driving video analysis. This study developed a dynamic scene retrieval system using Contrastive Language-Image Pretraining (CLIP) models, which can be optimized for real-time deployment on edge devices. The proposed system outperforms state-of-the-art in-context learning methods, including the zero-shot capabilities of GPT-4o, particularly in complex scenarios. By conducting frame-level analysis on the Honda Scenes Dataset, which contains a collection of about 80 hours of annotated driving videos capturing diverse real-world road and weather conditions, our study highlights the robustness of CLIP models in learning visual concepts from natural language supervision. Results also showed that fine-tuning the CLIP models, such as ViT-L/14 and ViT-B/32, significantly improved scene classification, achieving a top F1 score of 91.1%. These results demonstrate the ability of the system to deliver rapid and precise scene recognition, which can be used to meet the critical requirements of Advanced Driver Assistance Systems (ADAS). This study shows the potential of CLIP models to provide scalable and efficient frameworks for dynamic scene understanding and classification. Furthermore, this work lays the groundwork for advanced autonomous vehicle technologies by fostering a deeper understanding of driver behavior, road conditions, and safety-critical scenarios, marking a significant step toward smarter, safer, and more context-aware autonomous driving systems.
Leveraging Explainable AI for LLM Text Attribution: Differentiating Human-Written and Multiple LLMs-Generated Text
Jan 06, 2025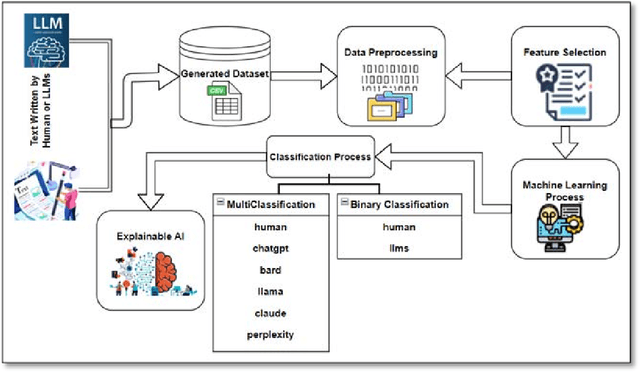
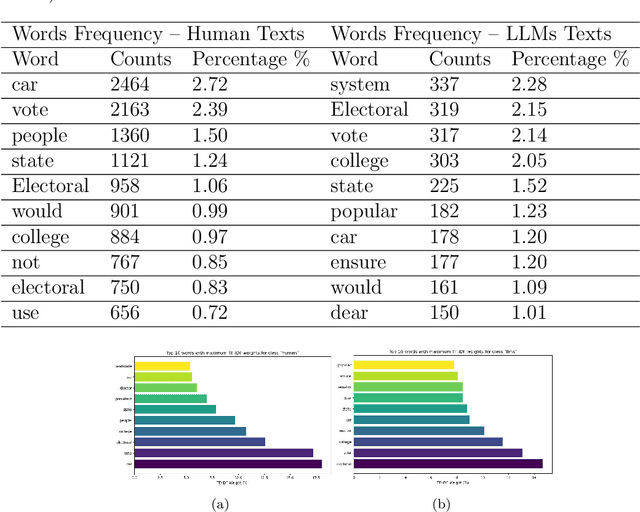
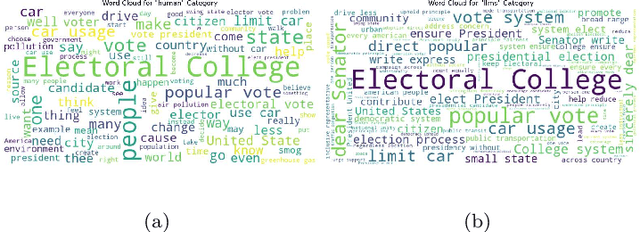

The development of Generative AI Large Language Models (LLMs) raised the alarm regarding identifying content produced through generative AI or humans. In one case, issues arise when students heavily rely on such tools in a manner that can affect the development of their writing or coding skills. Other issues of plagiarism also apply. This study aims to support efforts to detect and identify textual content generated using LLM tools. We hypothesize that LLMs-generated text is detectable by machine learning (ML), and investigate ML models that can recognize and differentiate texts generated by multiple LLMs tools. We leverage several ML and Deep Learning (DL) algorithms such as Random Forest (RF), and Recurrent Neural Networks (RNN), and utilized Explainable Artificial Intelligence (XAI) to understand the important features in attribution. Our method is divided into 1) binary classification to differentiate between human-written and AI-text, and 2) multi classification, to differentiate between human-written text and the text generated by the five different LLM tools (ChatGPT, LLaMA, Google Bard, Claude, and Perplexity). Results show high accuracy in the multi and binary classification. Our model outperformed GPTZero with 98.5\% accuracy to 78.3\%. Notably, GPTZero was unable to recognize about 4.2\% of the observations, but our model was able to recognize the complete test dataset. XAI results showed that understanding feature importance across different classes enables detailed author/source profiles. Further, aiding in attribution and supporting plagiarism detection by highlighting unique stylistic and structural elements ensuring robust content originality verification.
Detecting AI-Generated Text in Educational Content: Leveraging Machine Learning and Explainable AI for Academic Integrity
Jan 06, 2025This study seeks to enhance academic integrity by providing tools to detect AI-generated content in student work using advanced technologies. The findings promote transparency and accountability, helping educators maintain ethical standards and supporting the responsible integration of AI in education. A key contribution of this work is the generation of the CyberHumanAI dataset, which has 1000 observations, 500 of which are written by humans and the other 500 produced by ChatGPT. We evaluate various machine learning (ML) and deep learning (DL) algorithms on the CyberHumanAI dataset comparing human-written and AI-generated content from Large Language Models (LLMs) (i.e., ChatGPT). Results demonstrate that traditional ML algorithms, specifically XGBoost and Random Forest, achieve high performance (83% and 81% accuracies respectively). Results also show that classifying shorter content seems to be more challenging than classifying longer content. Further, using Explainable Artificial Intelligence (XAI) we identify discriminative features influencing the ML model's predictions, where human-written content tends to use a practical language (e.g., use and allow). Meanwhile AI-generated text is characterized by more abstract and formal terms (e.g., realm and employ). Finally, a comparative analysis with GPTZero show that our narrowly focused, simple, and fine-tuned model can outperform generalized systems like GPTZero. The proposed model achieved approximately 77.5% accuracy compared to GPTZero's 48.5% accuracy when tasked to classify Pure AI, Pure Human, and mixed class. GPTZero showed a tendency to classify challenging and small-content cases as either mixed or unrecognized while our proposed model showed a more balanced performance across the three classes.
Large Language Models (LLMs) as Traffic Control Systems at Urban Intersections: A New Paradigm
Nov 16, 2024



This study introduces a novel approach for traffic control systems by using Large Language Models (LLMs) as traffic controllers. The study utilizes their logical reasoning, scene understanding, and decision-making capabilities to optimize throughput and provide feedback based on traffic conditions in real-time. LLMs centralize traditionally disconnected traffic control processes and can integrate traffic data from diverse sources to provide context-aware decisions. LLMs can also deliver tailored outputs using various means such as wireless signals and visuals to drivers, infrastructures, and autonomous vehicles. To evaluate LLMs ability as traffic controllers, this study proposed a four-stage methodology. The methodology includes data creation and environment initialization, prompt engineering, conflict identification, and fine-tuning. We simulated multi-lane four-leg intersection scenarios and generates detailed datasets to enable conflict detection using LLMs and Python simulation as a ground truth. We used chain-of-thought prompts to lead LLMs in understanding the context, detecting conflicts, resolving them using traffic rules, and delivering context-sensitive traffic management solutions. We evaluated the prformance GPT-mini, Gemini, and Llama as traffic controllers. Results showed that the fine-tuned GPT-mini achieved 83% accuracy and an F1-score of 0.84. GPT-mini model exhibited a promising performance in generating actionable traffic management insights, with high ROUGE-L scores across conflict identification of 0.95, decision-making of 0.91, priority assignment of 0.94, and waiting time optimization of 0.92. We demonstrated that LLMs can offer precise recommendations to drivers in real-time including yielding, slowing, or stopping based on vehicle dynamics.