 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Explainable AI for LLM Text Attribution: Differentiating Human-Written and Multiple LLMs-Generated Text
Jan 06, 2025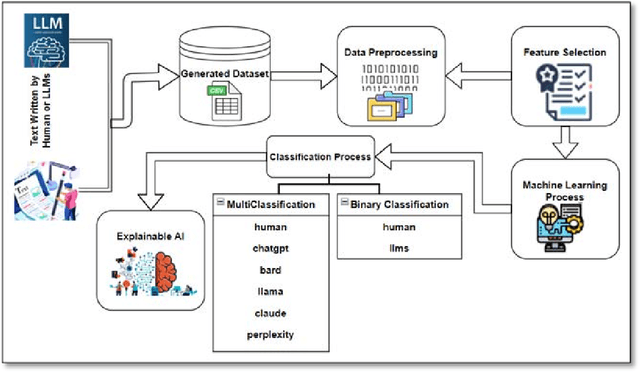
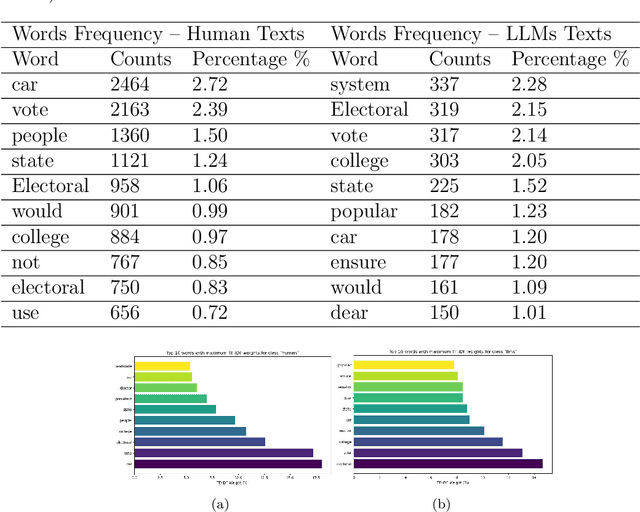
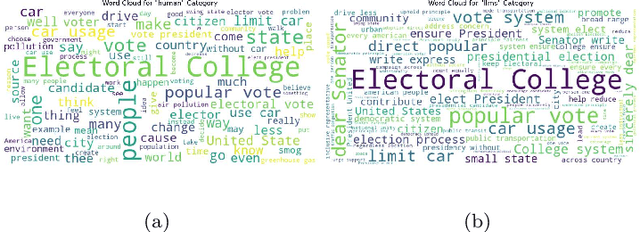

The development of Generative AI Large Language Models (LLMs) raised the alarm regarding identifying content produced through generative AI or humans. In one case, issues arise when students heavily rely on such tools in a manner that can affect the development of their writing or coding skills. Other issues of plagiarism also apply. This study aims to support efforts to detect and identify textual content generated using LLM tools. We hypothesize that LLMs-generated text is detectable by machine learning (ML), and investigate ML models that can recognize and differentiate texts generated by multiple LLMs tools. We leverage several ML and Deep Learning (DL) algorithms such as Random Forest (RF), and Recurrent Neural Networks (RNN), and utilized Explainable Artificial Intelligence (XAI) to understand the important features in attribution. Our method is divided into 1) binary classification to differentiate between human-written and AI-text, and 2) multi classification, to differentiate between human-written text and the text generated by the five different LLM tools (ChatGPT, LLaMA, Google Bard, Claude, and Perplexity). Results show high accuracy in the multi and binary classification. Our model outperformed GPTZero with 98.5\% accuracy to 78.3\%. Notably, GPTZero was unable to recognize about 4.2\% of the observations, but our model was able to recognize the complete test dataset. XAI results showed that understanding feature importance across different classes enables detailed author/source profiles. Further, aiding in attribution and supporting plagiarism detection by highlighting unique stylistic and structural elements ensuring robust content originality verification.
Detecting AI-Generated Text in Educational Content: Leveraging Machine Learning and Explainable AI for Academic Integrity
Jan 06, 2025This study seeks to enhance academic integrity by providing tools to detect AI-generated content in student work using advanced technologies. The findings promote transparency and accountability, helping educators maintain ethical standards and supporting the responsible integration of AI in education. A key contribution of this work is the generation of the CyberHumanAI dataset, which has 1000 observations, 500 of which are written by humans and the other 500 produced by ChatGPT. We evaluate various machine learning (ML) and deep learning (DL) algorithms on the CyberHumanAI dataset comparing human-written and AI-generated content from Large Language Models (LLMs) (i.e., ChatGPT). Results demonstrate that traditional ML algorithms, specifically XGBoost and Random Forest, achieve high performance (83% and 81% accuracies respectively). Results also show that classifying shorter content seems to be more challenging than classifying longer content. Further, using Explainable Artificial Intelligence (XAI) we identify discriminative features influencing the ML model's predictions, where human-written content tends to use a practical language (e.g., use and allow). Meanwhile AI-generated text is characterized by more abstract and formal terms (e.g., realm and employ). Finally, a comparative analysis with GPTZero show that our narrowly focused, simple, and fine-tuned model can outperform generalized systems like GPTZero. The proposed model achieved approximately 77.5% accuracy compared to GPTZero's 48.5% accuracy when tasked to classify Pure AI, Pure Human, and mixed class. GPTZero showed a tendency to classify challenging and small-content cases as either mixed or unrecognized while our proposed model showed a more balanced performance across the three classes.