 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlleviating Community Fear in Disasters via Multi-Agent Actor-Critic Reinforcement Learning
Apr 09, 2026During disasters, cascading failures across power grids, communication networks, and social behavior amplify community fear and undermine cooperation. Existing cyber-physical-social (CPS) models simulate these coupled dynamics but lack mechanisms for active intervention. We extend the CPS resilience model of Valinejad and Mili (2023) with control channels for three agencies, communication, power, and emergency management, and formulate the resulting system as a three-player non-zero-sum differential game solved via online actor-critic reinforcement learning. Simulations based on Hurricane Harvey data show 70% mean fear reduction with improved infrastructure recovery; cross-validation in the case of Hurricane Irma (without refitting) achieves 50% fear reduction, confirming generalizability.
InfinityStory: Unlimited Video Generation with World Consistency and Character-Aware Shot Transitions
Mar 04, 2026Generating long-form storytelling videos with consistent visual narratives remains a significant challenge in video synthesis. We present a novel framework, dataset, and a model that address three critical limitations: background consistency across shots, seamless multi-subject shot-to-shot transitions, and scalability to hour-long narratives. Our approach introduces a background-consistent generation pipeline that maintains visual coherence across scenes while preserving character identity and spatial relationships. We further propose a transition-aware video synthesis module that generates smooth shot transitions for complex scenarios involving multiple subjects entering or exiting frames, going beyond the single-subject limitations of prior work. To support this, we contribute with a synthetic dataset of 10,000 multi-subject transition sequences covering underrepresented dynamic scene compositions. On VBench, InfinityStory achieves the highest Background Consistency (88.94), highest Subject Consistency (82.11), and the best overall average rank (2.80), showing improved stability, smoother transitions, and better temporal coherence.
A Survey on Long-Video Storytelling Generation: Architectures, Consistency, and Cinematic Quality
Jul 09, 2025

Despite the significant progress that has been made in video generative models, existing state-of-the-art methods can only produce videos lasting 5-16 seconds, often labeled "long-form videos". Furthermore, videos exceeding 16 seconds struggle to maintain consistent character appearances and scene layouts throughout the narrative. In particular, multi-subject long videos still fail to preserve character consistency and motion coherence. While some methods can generate videos up to 150 seconds long, they often suffer from frame redundancy and low temporal diversity. Recent work has attempted to produce long-form videos featuring multiple characters, narrative coherence, and high-fidelity detail. We comprehensively studied 32 papers on video generation to identify key architectural components and training strategies that consistently yield these qualities. We also construct a comprehensive novel taxonomy of existing methods and present comparative tables that categorize papers by their architectural designs and performance characteristics.
The AI Policy Module: Developing Computer Science Student Competency in AI Ethics and Policy
Jun 18, 2025As artificial intelligence (AI) further embeds itself into many settings across personal and professional contexts, increasing attention must be paid not only to AI ethics, but also to the governance and regulation of AI technologies through AI policy. However, the prevailing post-secondary computing curriculum is currently ill-equipped to prepare future AI practitioners to confront increasing demands to implement abstract ethical principles and normative policy preferences into the design and development of AI systems. We believe that familiarity with the 'AI policy landscape' and the ability to translate ethical principles to practices will in the future constitute an important responsibility for even the most technically-focused AI engineers. Toward preparing current computer science (CS) students for these new expectations, we developed an AI Policy Module to introduce discussions of AI policy into the CS curriculum. Building on a successful pilot in fall 2024, in this innovative practice full paper we present an updated and expanded version of the module, including a technical assignment on "AI regulation". We present the findings from our pilot of the AI Policy Module 2.0, evaluating student attitudes towards AI ethics and policy through pre- and post-module surveys. Following the module, students reported increased concern about the ethical impacts of AI technologies while also expressing greater confidence in their abilities to engage in discussions about AI regulation. Finally, we highlight the AI Regulation Assignment as an effective and engaging tool for exploring the limits of AI alignment and emphasizing the role of 'policy' in addressing ethical challenges.
Sci-LoRA: Mixture of Scientific LoRAs for Cross-Domain Lay Paraphrasing
May 24, 2025Lay paraphrasing aims to make scientific information accessible to audiences without technical backgrounds. However, most existing studies focus on a single domain, such as biomedicine. With the rise of interdisciplinary research, it is increasingly necessary to comprehend knowledge spanning multiple technical fields. To address this, we propose Sci-LoRA, a model that leverages a mixture of LoRAs fine-tuned on multiple scientific domains. In particular, Sci-LoRA dynamically generates and applies weights for each LoRA, enabling it to adjust the impact of different domains based on the input text, without requiring explicit domain labels. To balance domain-specific knowledge and generalization across various domains, Sci-LoRA integrates information at both the data and model levels. This dynamic fusion enhances the adaptability and performance across various domains. Experimental results across twelve domains on five public datasets show that Sci-LoRA significantly outperforms state-of-the-art large language models and demonstrates flexible generalization and adaptability in cross-domain lay paraphrasing.
Efficient Model Selection for Time Series Forecasting via LLMs
Apr 02, 2025


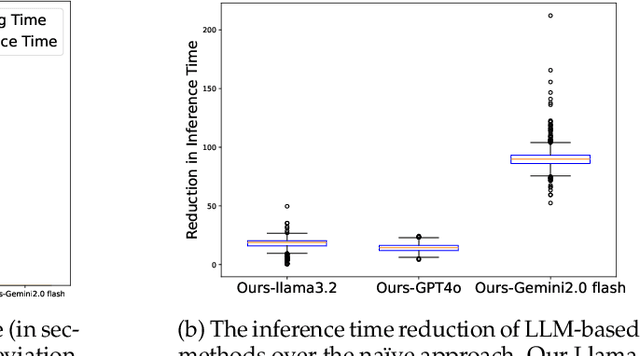
Model selection is a critical step in time series forecasting, traditionally requiring extensive performance evaluations across various datasets. Meta-learning approaches aim to automate this process, but they typically depend on pre-constructed performance matrices, which are costly to build. In this work, we propose to leverage Large Language Models (LLMs) as a lightweight alternative for model selection. Our method eliminates the need for explicit performance matrices by utilizing the inherent knowledge and reasoning capabilities of LLMs. Through extensive experiments with LLaMA, GPT and Gemini, we demonstrate that our approach outperforms traditional meta-learning techniques and heuristic baselines, while significantly reducing computational overhead. These findings underscore the potential of LLMs in efficient model selection for time series forecasting.
Visual Zero-Shot E-Commerce Product Attribute Value Extraction
Feb 21, 2025Existing zero-shot product attribute value (aspect) extraction approaches in e-Commerce industry rely on uni-modal or multi-modal models, where the sellers are asked to provide detailed textual inputs (product descriptions) for the products. However, manually providing (typing) the product descriptions is time-consuming and frustrating for the sellers. Thus, we propose a cross-modal zero-shot attribute value generation framework (ViOC-AG) based on CLIP, which only requires product images as the inputs. ViOC-AG follows a text-only training process, where a task-customized text decoder is trained with the frozen CLIP text encoder to alleviate the modality gap and task disconnection. During the zero-shot inference, product aspects are generated by the frozen CLIP image encoder connected with the trained task-customized text decoder. OCR tokens and outputs from a frozen prompt-based LLM correct the decoded outputs for out-of-domain attribute values. Experiments show that ViOC-AG significantly outperforms other fine-tuned vision-language models for zero-shot attribute value extraction.
Educating a Responsible AI Workforce: Piloting a Curricular Module on AI Policy in a Graduate Machine Learning Course
Feb 11, 2025As artificial intelligence (AI) technologies begin to permeate diverse fields-from healthcare to education-consumers, researchers and policymakers are increasingly raising concerns about whether and how AI is regulated. It is therefore reasonable to anticipate that alignment with principles of 'ethical' or 'responsible' AI, as well as compliance with law and policy, will form an increasingly important part of AI development. Yet, for the most part, the conventional computer science curriculum is ill-equipped to prepare students for these challenges. To this end, we seek to explore how new educational content related to AI ethics and AI policy can be integrated into both ethics- and technical-focused courses. This paper describes a two-lecture 'AI policy module' that was piloted in a graduate-level introductory machine learning course in 2024. The module, which includes an in-class active learning game, is evaluated using data from student surveys before and after the lectures, and pedagogical motivations and considerations are discussed. We find that the module is successful in engaging otherwise technically-oriented students on the topic of AI policy, increasing student awareness of the social impacts of a variety of AI technologies and developing student interest in the field of AI regulation.
In Search of a Lost Metric: Human Empowerment as a Pillar of Socially Conscious Navigation
Jan 02, 2025



In social robot navigation, traditional metrics like proxemics and behavior naturalness emphasize human comfort and adherence to social norms but often fail to capture an agent's autonomy and adaptability in dynamic environments. This paper introduces human empowerment, an information-theoretic concept that measures a human's ability to influence their future states and observe those changes, as a complementary metric for evaluating social compliance. This metric reveals how robot navigation policies can indirectly impact human empowerment. We present a framework that integrates human empowerment into the evaluation of social performance in navigation tasks. Through numerical simulations, we demonstrate that human empowerment as a metric not only aligns with intuitive social behavior, but also shows statistically significant differences across various robot navigation policies. These results provide a deeper understanding of how different policies affect social compliance, highlighting the potential of human empowerment as a complementary metric for future research in social navigation.
VTechAGP: An Academic-to-General-Audience Text Paraphrase Dataset and Benchmark Models
Nov 07, 2024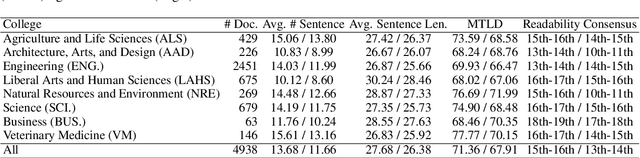
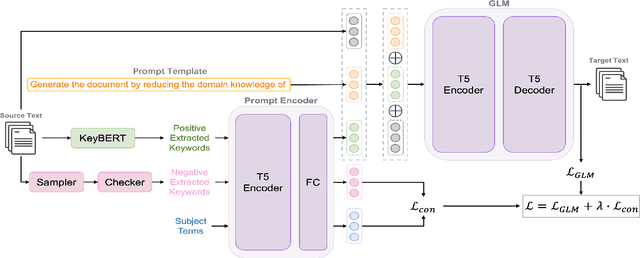
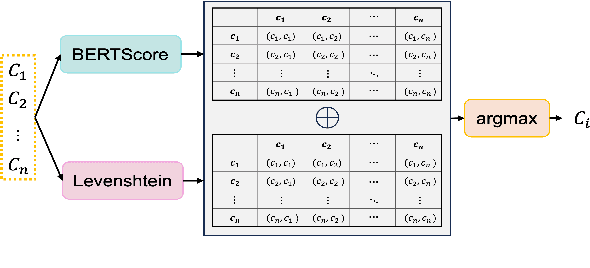
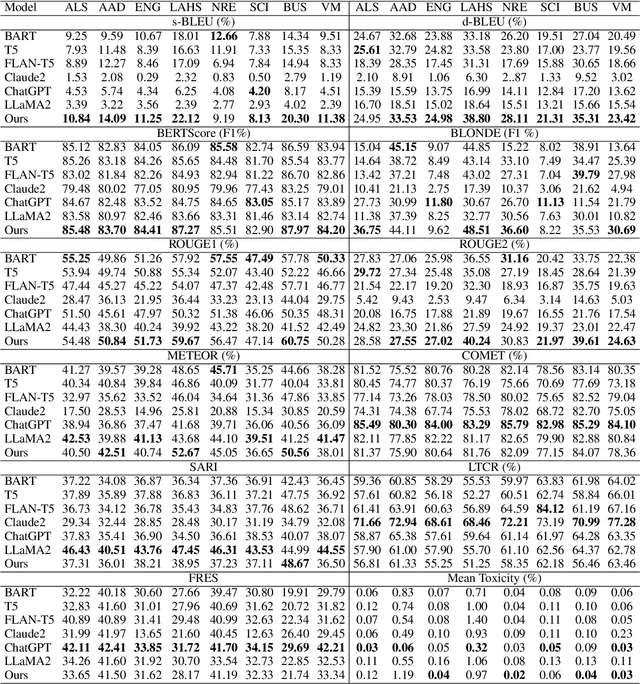
Existing text simplification or paraphrase datasets mainly focus on sentence-level text generation in a general domain. These datasets are typically developed without using domain knowledge. In this paper, we release a novel dataset, VTechAGP, which is the first academic-to-general-audience text paraphrase dataset consisting of 4,938 document-level these and dissertation academic and general-audience abstract pairs from 8 colleges authored over 25 years. We also propose a novel dynamic soft prompt generative language model, DSPT5. For training, we leverage a contrastive-generative loss function to learn the keyword vectors in the dynamic prompt. For inference, we adopt a crowd-sampling decoding strategy at both semantic and structural levels to further select the best output candidate. We evaluate DSPT5 and various state-of-the-art large language models (LLMs) from multiple perspectives. Results demonstrate that the SOTA LLMs does not provide satisfactory outcomes, while the lightweight DSPT5 can achieve competitive results. To the best of our knowledge, we are the first to build a benchmark dataset and solutions for academic-to-general-audience text paraphrase dataset.