 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning Adversaries into Allies: Reversing Typographic Attacks for Multimodal E-Commerce Product Retrieval
Nov 07, 2025Multimodal product retrieval systems in e-commerce platforms rely on effectively combining visual and textual signals to improve search relevance and user experience. However, vision-language models such as CLIP are vulnerable to typographic attacks, where misleading or irrelevant text embedded in images skews model predictions. In this work, we propose a novel method that reverses the logic of typographic attacks by rendering relevant textual content (e.g., titles, descriptions) directly onto product images to perform vision-text compression, thereby strengthening image-text alignment and boosting multimodal product retrieval performance. We evaluate our method on three vertical-specific e-commerce datasets (sneakers, handbags, and trading cards) using six state-of-the-art vision foundation models. Our experiments demonstrate consistent improvements in unimodal and multimodal retrieval accuracy across categories and model families. Our findings suggest that visually rendering product metadata is a simple yet effective enhancement for zero-shot multimodal retrieval in e-commerce applications.
Visual Zero-Shot E-Commerce Product Attribute Value Extraction
Feb 21, 2025Existing zero-shot product attribute value (aspect) extraction approaches in e-Commerce industry rely on uni-modal or multi-modal models, where the sellers are asked to provide detailed textual inputs (product descriptions) for the products. However, manually providing (typing) the product descriptions is time-consuming and frustrating for the sellers. Thus, we propose a cross-modal zero-shot attribute value generation framework (ViOC-AG) based on CLIP, which only requires product images as the inputs. ViOC-AG follows a text-only training process, where a task-customized text decoder is trained with the frozen CLIP text encoder to alleviate the modality gap and task disconnection. During the zero-shot inference, product aspects are generated by the frozen CLIP image encoder connected with the trained task-customized text decoder. OCR tokens and outputs from a frozen prompt-based LLM correct the decoded outputs for out-of-domain attribute values. Experiments show that ViOC-AG significantly outperforms other fine-tuned vision-language models for zero-shot attribute value extraction.
Temporal Knowledge Distillation for Time-Sensitive Financial Services Applications
Dec 28, 2023Detecting anomalies has become an increasingly critical function in the financial service industry. Anomaly detection is frequently used in key compliance and risk functions such as financial crime detection fraud and cybersecurity. The dynamic nature of the underlying data patterns especially in adversarial environments like fraud detection poses serious challenges to the machine learning models. Keeping up with the rapid changes by retraining the models with the latest data patterns introduces pressures in balancing the historical and current patterns while managing the training data size. Furthermore the model retraining times raise problems in time-sensitive and high-volume deployment systems where the retraining period directly impacts the models ability to respond to ongoing attacks in a timely manner. In this study we propose a temporal knowledge distillation-based label augmentation approach (TKD) which utilizes the learning from older models to rapidly boost the latest model and effectively reduces the model retraining times to achieve improved agility. Experimental results show that the proposed approach provides advantages in retraining times while improving the model performance.
On the Current and Emerging Challenges of Developing Fair and Ethical AI Solutions in Financial Services
Nov 02, 2021Artificial intelligence (AI) continues to find more numerous and more critical applications in the financial services industry, giving rise to fair and ethical AI as an industry-wide objective. While many ethical principles and guidelines have been published in recent years, they fall short of addressing the serious challenges that model developers face when building ethical AI solutions. We survey the practical and overarching issues surrounding model development, from design and implementation complexities, to the shortage of tools, and the lack of organizational constructs. We show how practical considerations reveal the gaps between high-level principles and concrete, deployed AI applications, with the aim of starting industry-wide conversations toward solution approaches.
* 10 pages; expanded from conference version
Label Augmentation via Time-based Knowledge Distillation for Financial Anomaly Detection
Jan 05, 2021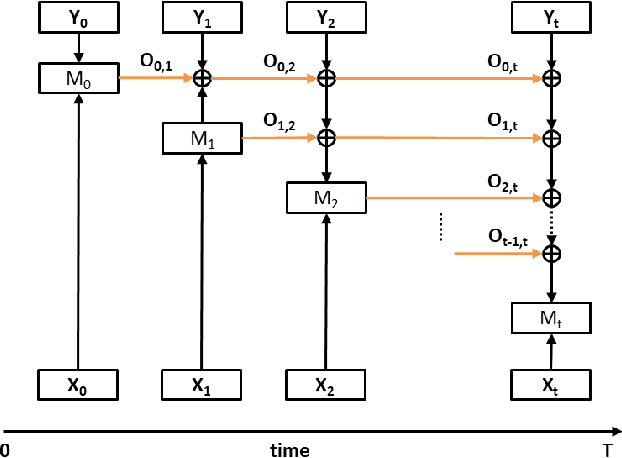



Detecting anomalies has become increasingly critical to the financial service industry. Anomalous events are often indicative of illegal activities such as fraud, identity theft, network intrusion, account takeover, and money laundering. Financial anomaly detection use cases face serious challenges due to the dynamic nature of the underlying patterns especially in adversarial environments such as constantly changing fraud tactics. While retraining the models with the new patterns is absolutely essential; keeping up with the rapid changes introduces other challenges as it moves the model away from older patterns or continuously grows the size of the training data. The resulting data growth is hard to manage and it reduces the agility of the models' response to the latest attacks. Due to the data size limitations and the need to track the latest patterns, older time periods are often dropped in practice, which in turn, causes vulnerabilities. In this study, we propose a label augmentation approach to utilize the learning from older models to boost the latest. Experimental results show that the proposed approach provides a significant reduction in training time, while providing potential performance improvement.
Deep Q-Network-based Adaptive Alert Threshold Selection Policy for Payment Fraud Systems in Retail Banking
Oct 21, 2020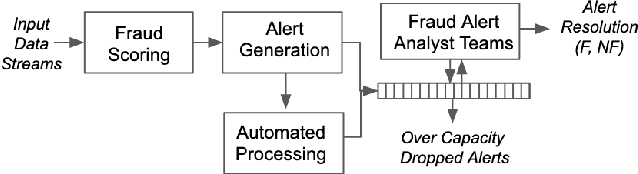
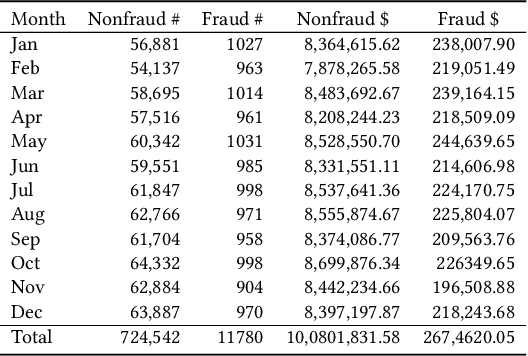
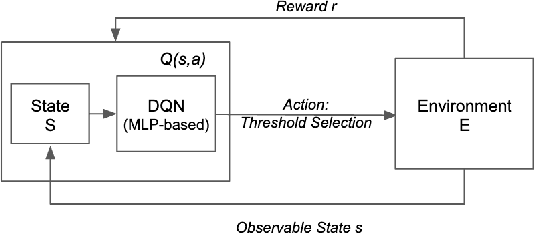

Machine learning models have widely been used in fraud detection systems. Most of the research and development efforts have been concentrated on improving the performance of the fraud scoring models. Yet, the downstream fraud alert systems still have limited to no model adoption and rely on manual steps. Alert systems are pervasively used across all payment channels in retail banking and play an important role in the overall fraud detection process. Current fraud detection systems end up with large numbers of dropped alerts due to their inability to account for the alert processing capacity. Ideally, alert threshold selection enables the system to maximize the fraud detection while balancing the upstream fraud scores and the available bandwidth of the alert processing teams. However, in practice, fixed thresholds that are used for their simplicity do not have this ability. In this paper, we propose an enhanced threshold selection policy for fraud alert systems. The proposed approach formulates the threshold selection as a sequential decision making problem and uses Deep Q-Network based reinforcement learning. Experimental results show that this adaptive approach outperforms the current static solutions by reducing the fraud losses as well as improving the operational efficiency of the alert system.
Towards Self-Regulating AI: Challenges and Opportunities of AI Model Governance in Financial Services
Oct 09, 2020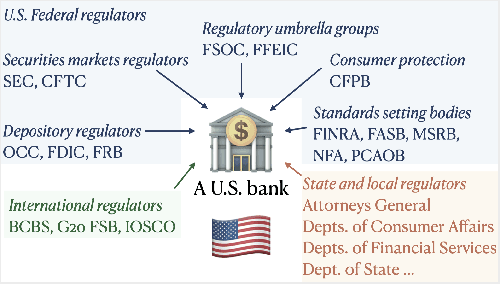
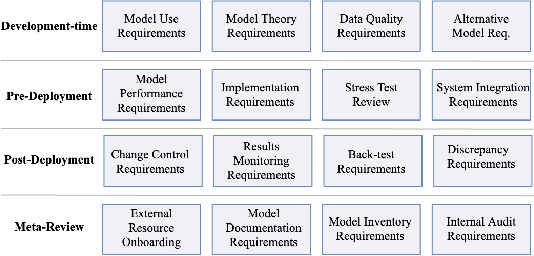
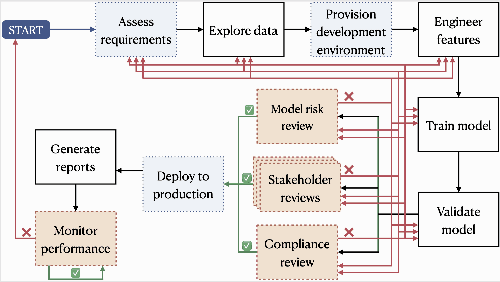
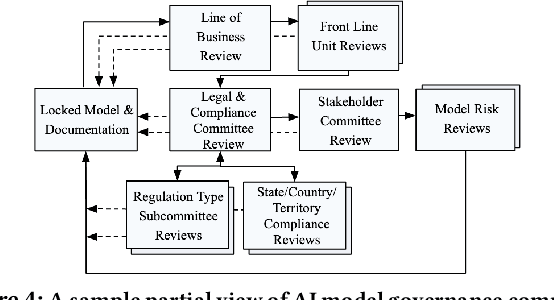
AI systems have found a wide range of application areas in financial services. Their involvement in broader and increasingly critical decisions has escalated the need for compliance and effective model governance. Current governance practices have evolved from more traditional financial applications and modeling frameworks. They often struggle with the fundamental differences in AI characteristics such as uncertainty in the assumptions, and the lack of explicit programming. AI model governance frequently involves complex review flows and relies heavily on manual steps. As a result, it faces serious challenges in effectiveness, cost, complexity, and speed. Furthermore, the unprecedented rate of growth in the AI model complexity raises questions on the sustainability of the current practices. This paper focuses on the challenges of AI model governance in the financial services industry. As a part of the outlook, we present a system-level framework towards increased self-regulation for robustness and compliance. This approach aims to enable potential solution opportunities through increased automation and the integration of monitoring, management, and mitigation capabilities. The proposed framework also provides model governance and risk management improved capabilities to manage model risk during deployment.
* 8 pages, 7 figures