 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Emergence of Interaction Patterns across Independent RL Agents in Multi-Agent Environments
Oct 03, 2024Many real-world problems, such as controlling swarms of drones and urban traffic, naturally lend themselves to modeling as multi-agent reinforcement learning (RL) problems. However, existing multi-agent RL methods often suffer from scalability challenges, primarily due to the introduction of communication among agents. Consequently, a key challenge lies in adapting the success of deep learning in single-agent RL to the multi-agent setting. In response to this challenge, we propose an approach that fundamentally reimagines multi-agent environments. Unlike conventional methods that model each agent individually with separate networks, our approach, the Bottom Up Network (BUN), adopts a unique perspective. BUN treats the collective of multi-agents as a unified entity while employing a specialized weight initialization strategy that promotes independent learning. Furthermore, we dynamically establish connections among agents using gradient information, enabling coordination when necessary while maintaining these connections as limited and sparse to effectively manage the computational budget. Our extensive empirical evaluations across a variety of cooperative multi-agent scenarios, including tasks such as cooperative navigation and traffic control, consistently demonstrate BUN's superiority over baseline methods with substantially reduced computational costs.
PD-MORL: Preference-Driven Multi-Objective Reinforcement Learning Algorithm
Aug 16, 2022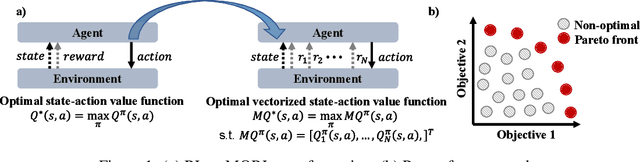

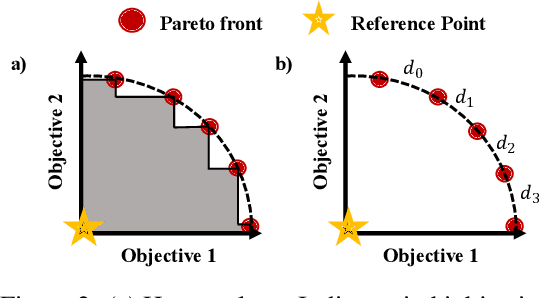
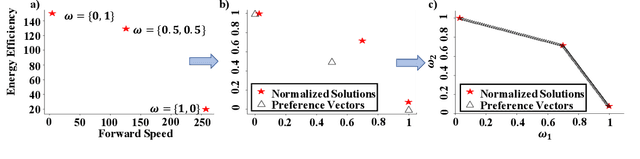
Many real-world problems involve multiple, possibly conflicting, objectives. Multi-objective reinforcement learning (MORL) approaches have emerged to tackle these problems by maximizing a joint objective function weighted by a preference vector. These approaches find fixed customized policies corresponding to preference vectors specified during training. However, the design constraints and objectives typically change dynamically in real-life scenarios. Furthermore, storing a policy for each potential preference is not scalable. Hence, obtaining a set of Pareto front solutions for the entire preference space in a given domain with a single training is critical. To this end, we propose a novel MORL algorithm that trains a single universal network to cover the entire preference space. The proposed approach, Preference-Driven MORL (PD-MORL), utilizes the preferences as guidance to update the network parameters. After demonstrating PD-MORL using classical Deep Sea Treasure and Fruit Tree Navigation benchmarks, we evaluate its performance on challenging multi-objective continuous control tasks.
Hypervector Design for Efficient Hyperdimensional Computing on Edge Devices
Mar 08, 2021
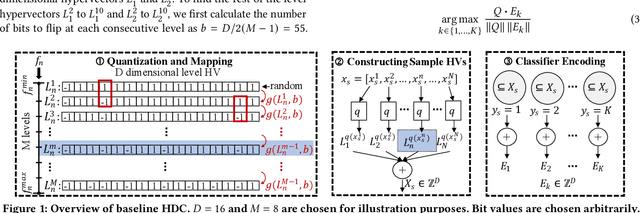

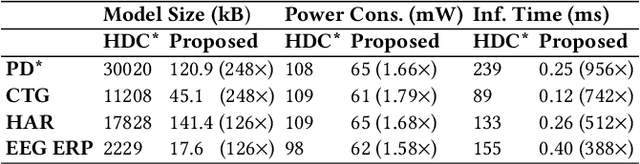
Hyperdimensional computing (HDC) has emerged as a new light-weight learning algorithm with smaller computation and energy requirements compared to conventional techniques. In HDC, data points are represented by high-dimensional vectors (hypervectors), which are mapped to high-dimensional space (hyperspace). Typically, a large hypervector dimension ($\geq1000$) is required to achieve accuracies comparable to conventional alternatives. However, unnecessarily large hypervectors increase hardware and energy costs, which can undermine their benefits. This paper presents a technique to minimize the hypervector dimension while maintaining the accuracy and improving the robustness of the classifier. To this end, we formulate the hypervector design as a multi-objective optimization problem for the first time in the literature. The proposed approach decreases the hypervector dimension by more than $32\times$ while maintaining or increasing the accuracy achieved by conventional HDC. Experiments on a commercial hardware platform show that the proposed approach achieves more than one order of magnitude reduction in model size, inference time, and energy consumption. We also demonstrate the trade-off between accuracy and robustness to noise and provide Pareto front solutions as a design parameter in our hypervector design.
Transfer Learning for Human Activity Recognition using Representational Analysis of Neural Networks
Dec 05, 2020
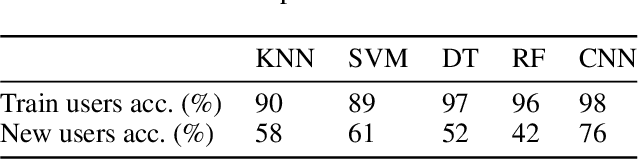

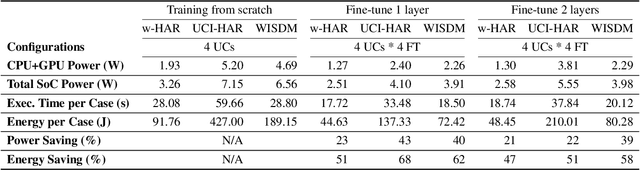
Human activity recognition (HAR) research has increased in recent years due to its applications in mobile health monitoring, activity recognition, and patient rehabilitation. The typical approach is training a HAR classifier offline with known users and then using the same classifier for new users. However, the accuracy for new users can be low with this approach if their activity patterns are different than those in the training data. At the same time, training from scratch for new users is not feasible for mobile applications due to the high computational cost and training time. To address this issue, we propose a HAR transfer learning framework with two components. First, a representational analysis reveals common features that can transfer across users and user-specific features that need to be customized. Using this insight, we transfer the reusable portion of the offline classifier to new users and fine-tune only the rest. Our experiments with five datasets show up to 43% accuracy improvement and 66% training time reduction when compared to the baseline without using transfer learning. Furthermore, measurements on the Nvidia Jetson Xavier-NX hardware platform reveal that the power and energy consumption decrease by 43% and 68%, respectively, while achieving the same or higher accuracy as training from scratch.