 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePD-MORL: Preference-Driven Multi-Objective Reinforcement Learning Algorithm
Paper and Code
Aug 16, 2022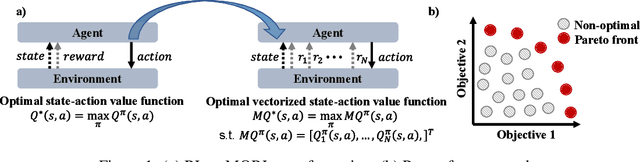

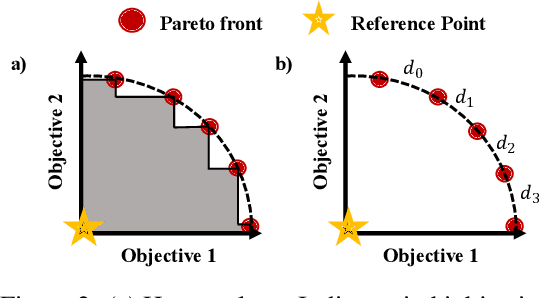
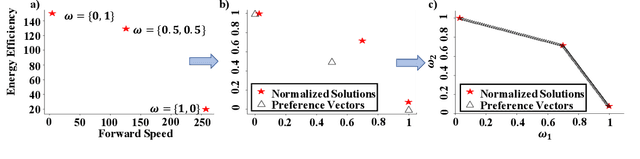
Many real-world problems involve multiple, possibly conflicting, objectives. Multi-objective reinforcement learning (MORL) approaches have emerged to tackle these problems by maximizing a joint objective function weighted by a preference vector. These approaches find fixed customized policies corresponding to preference vectors specified during training. However, the design constraints and objectives typically change dynamically in real-life scenarios. Furthermore, storing a policy for each potential preference is not scalable. Hence, obtaining a set of Pareto front solutions for the entire preference space in a given domain with a single training is critical. To this end, we propose a novel MORL algorithm that trains a single universal network to cover the entire preference space. The proposed approach, Preference-Driven MORL (PD-MORL), utilizes the preferences as guidance to update the network parameters. After demonstrating PD-MORL using classical Deep Sea Treasure and Fruit Tree Navigation benchmarks, we evaluate its performance on challenging multi-objective continuous control tasks.