 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTechAGP: An Academic-to-General-Audience Text Paraphrase Dataset and Benchmark Models
Paper and Code
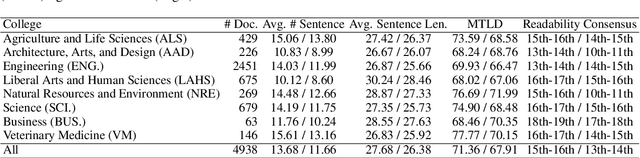
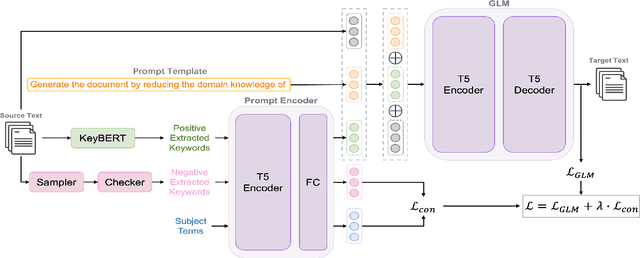
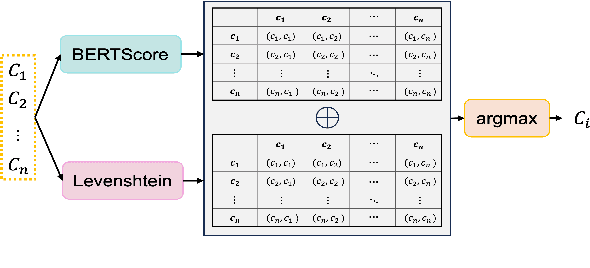
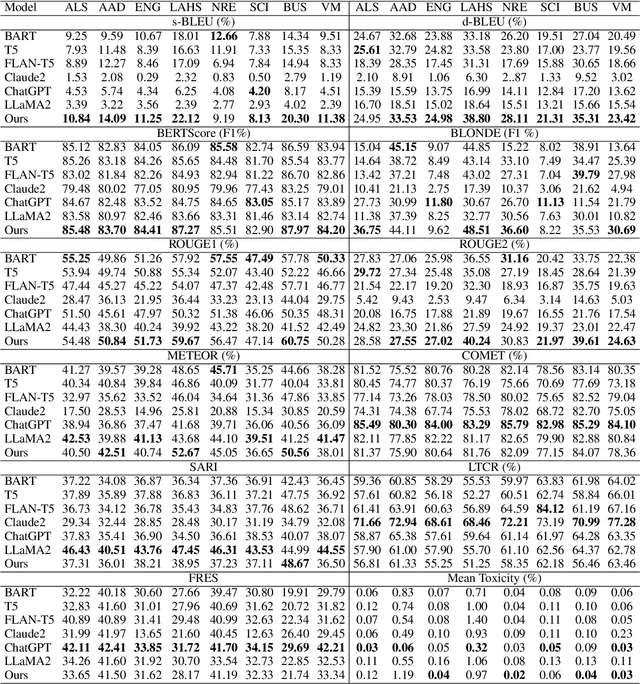
Existing text simplification or paraphrase datasets mainly focus on sentence-level text generation in a general domain. These datasets are typically developed without using domain knowledge. In this paper, we release a novel dataset, VTechAGP, which is the first academic-to-general-audience text paraphrase dataset consisting of 4,938 document-level these and dissertation academic and general-audience abstract pairs from 8 colleges authored over 25 years. We also propose a novel dynamic soft prompt generative language model, DSPT5. For training, we leverage a contrastive-generative loss function to learn the keyword vectors in the dynamic prompt. For inference, we adopt a crowd-sampling decoding strategy at both semantic and structural levels to further select the best output candidate. We evaluate DSPT5 and various state-of-the-art large language models (LLMs) from multiple perspectives. Results demonstrate that the SOTA LLMs does not provide satisfactory outcomes, while the lightweight DSPT5 can achieve competitive results. To the best of our knowledge, we are the first to build a benchmark dataset and solutions for academic-to-general-audience text paraphrase dataset.