 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
VTechAGP: An Academic-to-General-Audience Text Paraphrase Dataset and Benchmark Models
Nov 07, 2024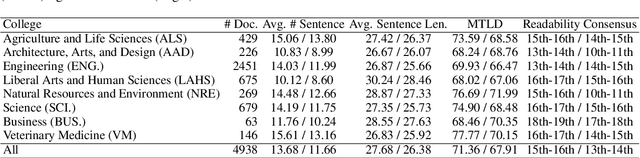
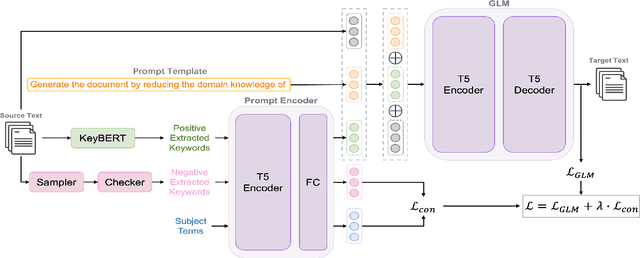
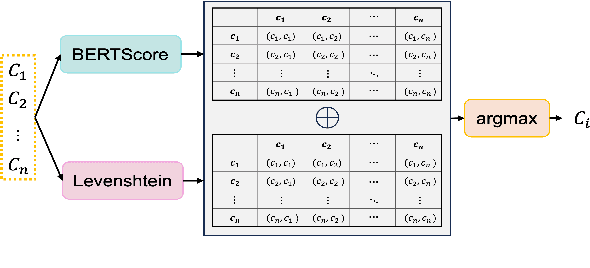
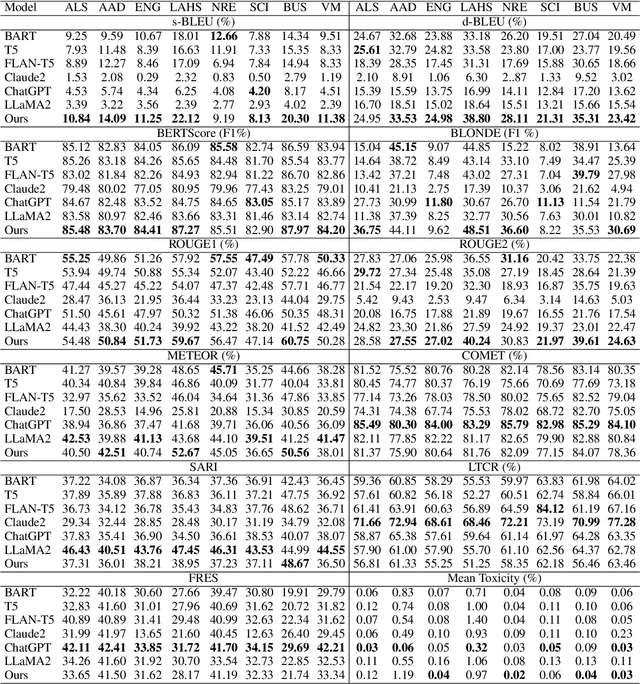
Existing text simplification or paraphrase datasets mainly focus on sentence-level text generation in a general domain. These datasets are typically developed without using domain knowledge. In this paper, we release a novel dataset, VTechAGP, which is the first academic-to-general-audience text paraphrase dataset consisting of 4,938 document-level these and dissertation academic and general-audience abstract pairs from 8 colleges authored over 25 years. We also propose a novel dynamic soft prompt generative language model, DSPT5. For training, we leverage a contrastive-generative loss function to learn the keyword vectors in the dynamic prompt. For inference, we adopt a crowd-sampling decoding strategy at both semantic and structural levels to further select the best output candidate. We evaluate DSPT5 and various state-of-the-art large language models (LLMs) from multiple perspectives. Results demonstrate that the SOTA LLMs does not provide satisfactory outcomes, while the lightweight DSPT5 can achieve competitive results. To the best of our knowledge, we are the first to build a benchmark dataset and solutions for academic-to-general-audience text paraphrase dataset.
CAST: Corpus-Aware Self-similarity Enhanced Topic modelling
Oct 19, 2024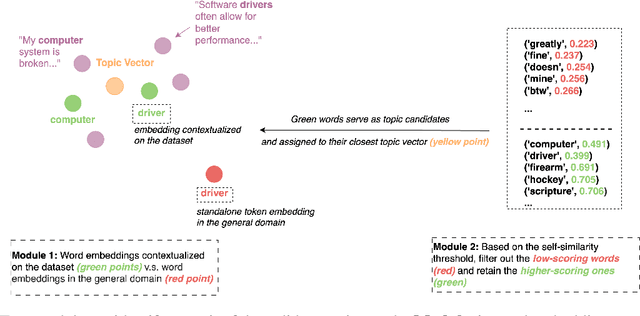
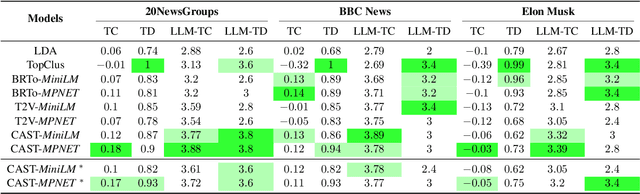
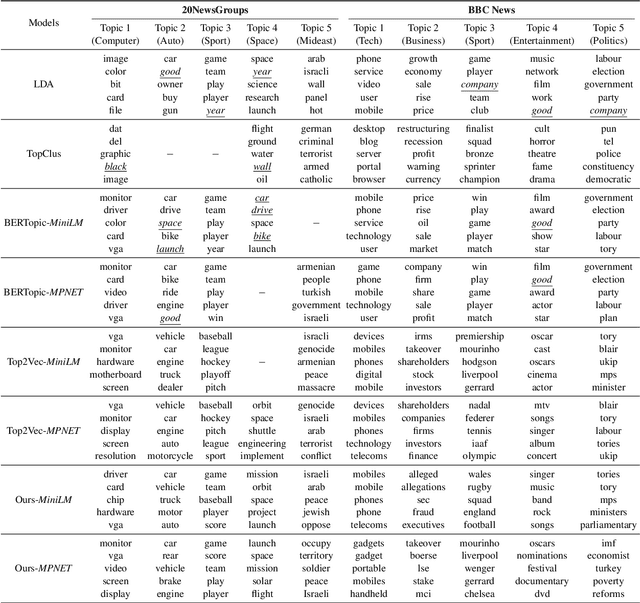
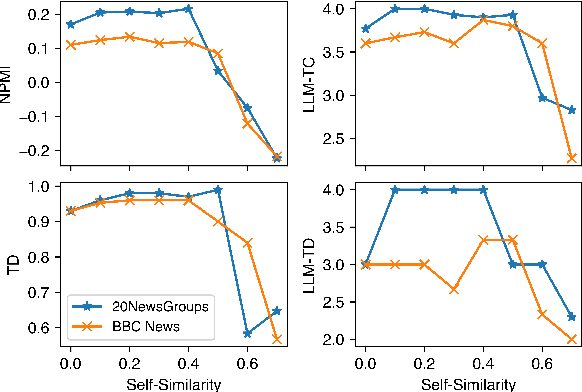
Topic modelling is a pivotal unsupervised machine learning technique for extracting valuable insights from large document collections. Existing neural topic modelling methods often encode contextual information of documents, while ignoring contextual details of candidate centroid words, leading to the inaccurate selection of topic words due to the contextualization gap. In parallel, it is found that functional words are frequently selected over topical words. To address these limitations, we introduce CAST: Corpus-Aware Self-similarity Enhanced Topic modelling, a novel topic modelling method that builds upon candidate centroid word embeddings contextualized on the dataset, and a novel self-similarity-based method to filter out less meaningful tokens. Inspired by findings in contrastive learning that self-similarities of functional token embeddings in different contexts are much lower than topical tokens, we find self-similarity to be an effective metric to prevent functional words from acting as candidate topic words. Our approach significantly enhances the coherence and diversity of generated topics, as well as the topic model's ability to handle noisy data. Experiments on news benchmark datasets and one Twitter dataset demonstrate the method's superiority in generating coherent, diverse topics, and handling noisy data, outperforming strong baselines.
Predicting Rewards Alongside Tokens: Non-disruptive Parameter Insertion for Efficient Inference Intervention in Large Language Model
Aug 20, 2024



Transformer-based large language models (LLMs) exhibit limitations such as generating unsafe responses, unreliable reasoning, etc. Existing inference intervention approaches attempt to mitigate these issues by finetuning additional models to produce calibration signals (such as rewards) that guide the LLM's decoding process. However, this solution introduces substantial time and space overhead due to the separate models required. This work proposes Non-disruptive parameters insertion (Otter), inserting extra parameters into the transformer architecture to predict calibration signals along with the original LLM output. Otter offers state-of-the-art performance on multiple demanding tasks while saving up to 86.5\% extra space and 98.5\% extra time. Furthermore, Otter seamlessly integrates with existing inference engines, requiring only a one-line code change, and the original model response remains accessible after the parameter insertion. Our code is publicly available at \url{https://github.com/chenhan97/Otter}
Are Large Language Models True Healthcare Jacks-of-All-Trades? Benchmarking Across Health Professions Beyond Physician Exams
Jun 17, 2024

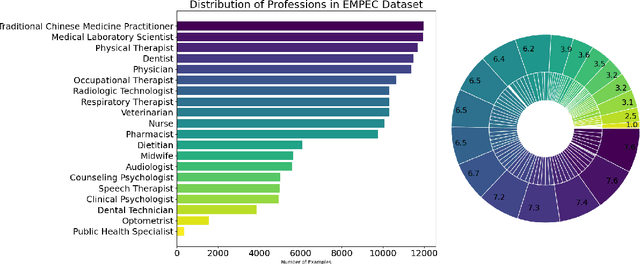

Recent advancements in Large Language Models (LLMs) have demonstrated their potential in delivering accurate answers to questions about world knowledge. Despite this, existing benchmarks for evaluating LLMs in healthcare predominantly focus on medical doctors, leaving other critical healthcare professions underrepresented. To fill this research gap, we introduce the Examinations for Medical Personnel in Chinese (EMPEC), a pioneering large-scale healthcare knowledge benchmark in traditional Chinese. EMPEC consists of 157,803 exam questions across 124 subjects and 20 healthcare professions, including underrepresented occupations like Optometrists and Audiologists. Each question is tagged with its release time and source, ensuring relevance and authenticity. We conducted extensive experiments on 17 LLMs, including proprietary, open-source models, general domain models and medical specific models, evaluating their performance under various settings. Our findings reveal that while leading models like GPT-4 achieve over 75\% accuracy, they still struggle with specialized fields and alternative medicine. Surprisingly, general-purpose LLMs outperformed medical-specific models, and incorporating EMPEC's training data significantly enhanced performance. Additionally, the results on questions released after the models' training cutoff date were consistent with overall performance trends, suggesting that the models' performance on the test set can predict their effectiveness in addressing unseen healthcare-related queries. The transition from traditional to simplified Chinese characters had a negligible impact on model performance, indicating robust linguistic versatility. Our study underscores the importance of expanding benchmarks to cover a broader range of healthcare professions to better assess the applicability of LLMs in real-world healthcare scenarios.
No Language is an Island: Unifying Chinese and English in Financial Large Language Models, Instruction Data, and Benchmarks
Mar 10, 2024



While the progression of Large Language Models (LLMs) has notably propelled financial analysis, their application has largely been confined to singular language realms, leaving untapped the potential of bilingual Chinese-English capacity. To bridge this chasm, we introduce ICE-PIXIU, seamlessly amalgamating the ICE-INTENT model and ICE-FLARE benchmark for bilingual financial analysis. ICE-PIXIU uniquely integrates a spectrum of Chinese tasks, alongside translated and original English datasets, enriching the breadth and depth of bilingual financial modeling. It provides unrestricted access to diverse model variants, a substantial compilation of diverse cross-lingual and multi-modal instruction data, and an evaluation benchmark with expert annotations, comprising 10 NLP tasks, 20 bilingual specific tasks, totaling 1,185k datasets. Our thorough evaluation emphasizes the advantages of incorporating these bilingual datasets, especially in translation tasks and utilizing original English data, enhancing both linguistic flexibility and analytical acuity in financial contexts. Notably, ICE-INTENT distinguishes itself by showcasing significant enhancements over conventional LLMs and existing financial LLMs in bilingual milieus, underscoring the profound impact of robust bilingual data on the accuracy and efficacy of financial NLP.
The FinBen: An Holistic Financial Benchmark for Large Language Models
Feb 20, 2024



LLMs have transformed NLP and shown promise in various fields, yet their potential in finance is underexplored due to a lack of thorough evaluations and the complexity of financial tasks. This along with the rapid development of LLMs, highlights the urgent need for a systematic financial evaluation benchmark for LLMs. In this paper, we introduce FinBen, the first comprehensive open-sourced evaluation benchmark, specifically designed to thoroughly assess the capabilities of LLMs in the financial domain. FinBen encompasses 35 datasets across 23 financial tasks, organized into three spectrums of difficulty inspired by the Cattell-Horn-Carroll theory, to evaluate LLMs' cognitive abilities in inductive reasoning, associative memory, quantitative reasoning, crystallized intelligence, and more. Our evaluation of 15 representative LLMs, including GPT-4, ChatGPT, and the latest Gemini, reveals insights into their strengths and limitations within the financial domain. The findings indicate that GPT-4 leads in quantification, extraction, numerical reasoning, and stock trading, while Gemini shines in generation and forecasting; however, both struggle with complex extraction and forecasting, showing a clear need for targeted enhancements. Instruction tuning boosts simple task performance but falls short in improving complex reasoning and forecasting abilities. FinBen seeks to continuously evaluate LLMs in finance, fostering AI development with regular updates of tasks and models.
Dólares or Dollars? Unraveling the Bilingual Prowess of Financial LLMs Between Spanish and English
Feb 12, 2024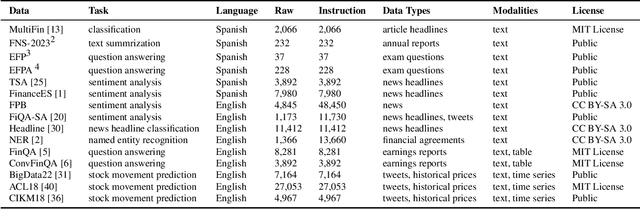
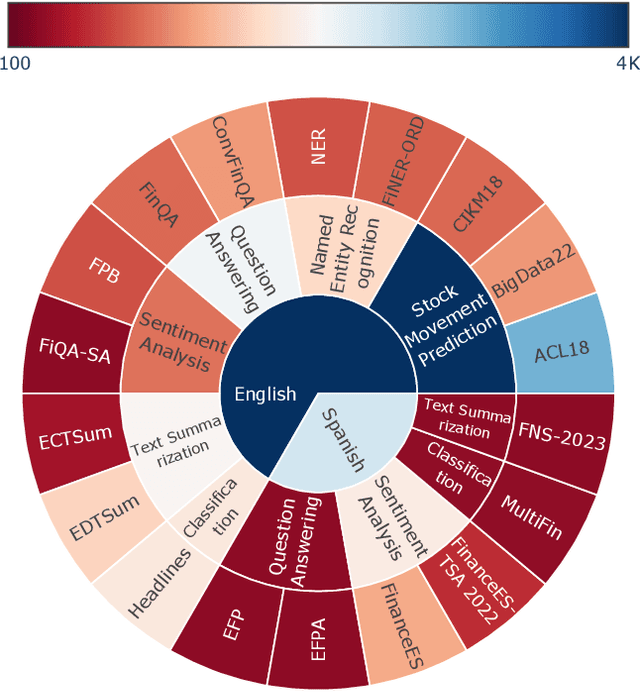
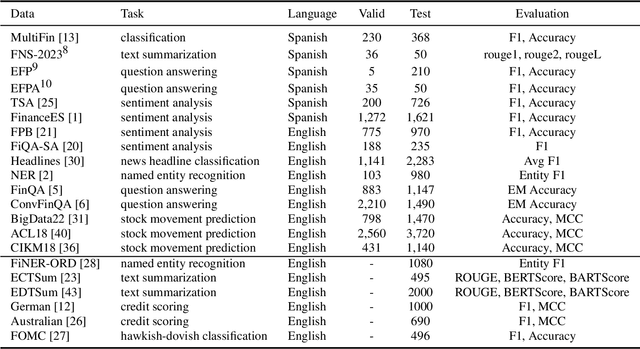
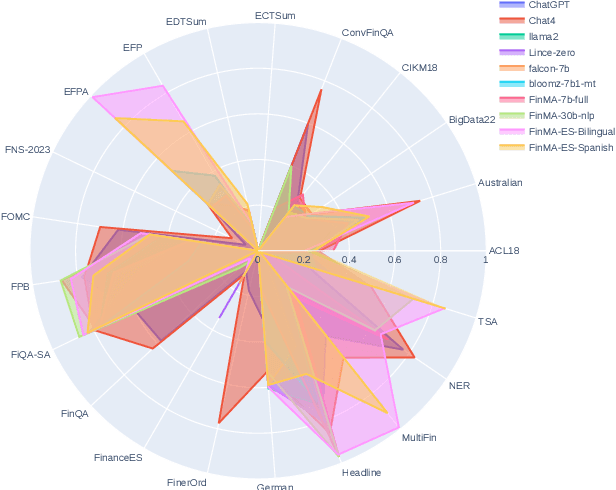
Despite Spanish's pivotal role in the global finance industry, a pronounced gap exists in Spanish financial natural language processing (NLP) and application studies compared to English, especially in the era of large language models (LLMs). To bridge this gap, we unveil Tois\'on de Oro, the first bilingual framework that establishes instruction datasets, finetuned LLMs, and evaluation benchmark for financial LLMs in Spanish joint with English. We construct a rigorously curated bilingual instruction dataset including over 144K Spanish and English samples from 15 datasets covering 7 tasks. Harnessing this, we introduce FinMA-ES, an LLM designed for bilingual financial applications. We evaluate our model and existing LLMs using FLARE-ES, the first comprehensive bilingual evaluation benchmark with 21 datasets covering 9 tasks. The FLARE-ES benchmark results reveal a significant multilingual performance gap and bias in existing LLMs. FinMA-ES models surpass SOTA LLMs such as GPT-4 in Spanish financial tasks, due to strategic instruction tuning and leveraging data from diverse linguistic resources, highlighting the positive impact of cross-linguistic transfer. All our datasets, models, and benchmarks have been released.
Back to the Future: Towards Explainable Temporal Reasoning with Large Language Models
Oct 08, 2023Temporal reasoning is a crucial NLP task, providing a nuanced understanding of time-sensitive contexts within textual data. Although recent advancements in LLMs have demonstrated their potential in temporal reasoning, the predominant focus has been on tasks such as temporal expression and temporal relation extraction. These tasks are primarily designed for the extraction of direct and past temporal cues and to engage in simple reasoning processes. A significant gap remains when considering complex reasoning tasks such as event forecasting, which requires multi-step temporal reasoning on events and prediction on the future timestamp. Another notable limitation of existing methods is their incapability to provide an illustration of their reasoning process, hindering explainability. In this paper, we introduce the first task of explainable temporal reasoning, to predict an event's occurrence at a future timestamp based on context which requires multiple reasoning over multiple events, and subsequently provide a clear explanation for their prediction. Our task offers a comprehensive evaluation of both the LLMs' complex temporal reasoning ability, the future event prediction ability, and explainability-a critical attribute for AI applications. To support this task, we present the first multi-source instruction-tuning dataset of explainable temporal reasoning (ExpTime) with 26k derived from the temporal knowledge graph datasets and their temporal reasoning paths, using a novel knowledge-graph-instructed-generation strategy. Based on the dataset, we propose the first open-source LLM series TimeLlaMA based on the foundation LlaMA2, with the ability of instruction following for explainable temporal reasoning. We compare the performance of our method and a variety of LLMs, where our method achieves the state-of-the-art performance of temporal prediction and explanation.
GradXKG: A Universal Explain-per-use Temporal Knowledge Graph Explainer
Oct 07, 2023
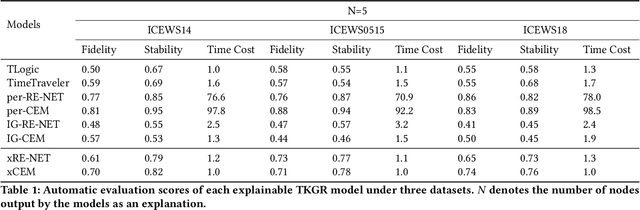

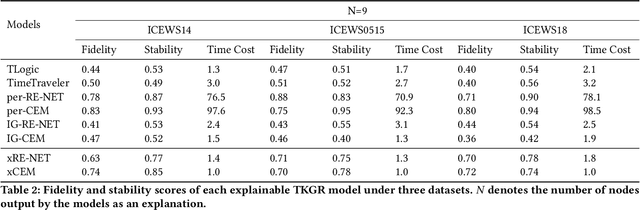
Temporal knowledge graphs (TKGs) have shown promise for reasoning tasks by incorporating a temporal dimension to represent how facts evolve over time. However, existing TKG reasoning (TKGR) models lack explainability due to their black-box nature. Recent work has attempted to address this through customized model architectures that generate reasoning paths, but these recent approaches have limited generalizability and provide sparse explanatory output. To enable interpretability for most TKGR models, we propose GradXKG, a novel two-stage gradient-based approach for explaining Relational Graph Convolution Network (RGCN)-based TKGR models. First, a Grad-CAM-inspired RGCN explainer tracks gradients to quantify each node's contribution across timesteps in an efficient "explain-per-use" fashion. Second, an integrated gradients explainer consolidates importance scores for RGCN outputs, extending compatibility across diverse TKGR architectures based on RGCN. Together, the two explainers highlight the most critical nodes at each timestep for a given prediction. Our extensive experiments demonstrated that, by leveraging gradient information, GradXKG provides insightful explanations grounded in the model's logic in a timely manner for most RGCN-based TKGR models. This helps address the lack of interpretability in existing TKGR models and provides a universal explanation approach applicable across various models.