 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAST: Corpus-Aware Self-similarity Enhanced Topic modelling
Oct 19, 2024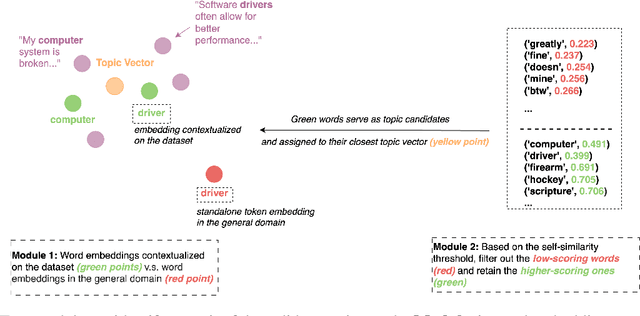
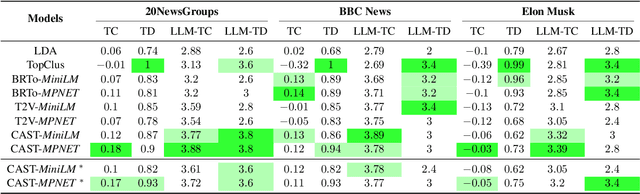
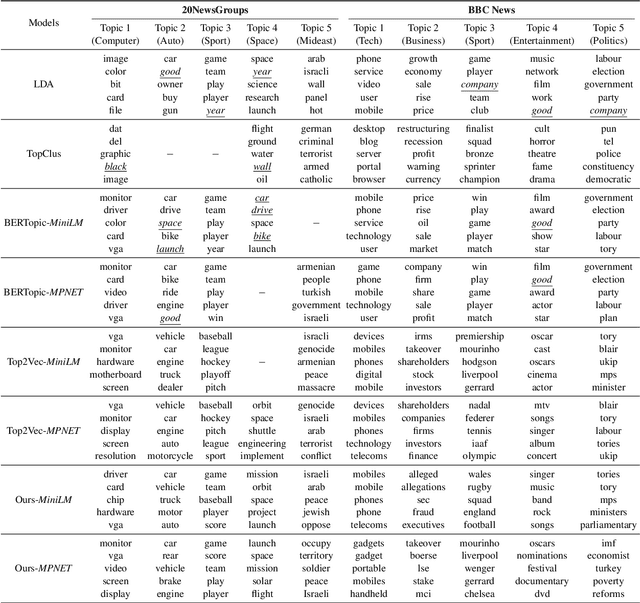
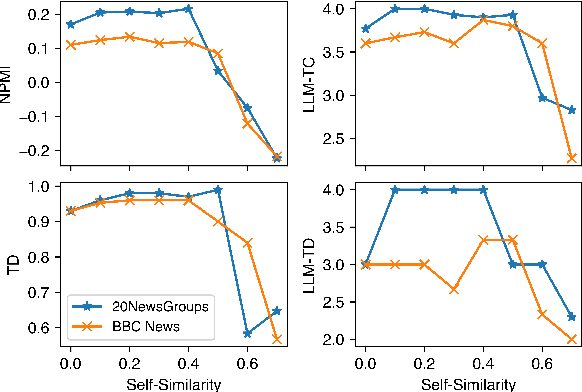
Topic modelling is a pivotal unsupervised machine learning technique for extracting valuable insights from large document collections. Existing neural topic modelling methods often encode contextual information of documents, while ignoring contextual details of candidate centroid words, leading to the inaccurate selection of topic words due to the contextualization gap. In parallel, it is found that functional words are frequently selected over topical words. To address these limitations, we introduce CAST: Corpus-Aware Self-similarity Enhanced Topic modelling, a novel topic modelling method that builds upon candidate centroid word embeddings contextualized on the dataset, and a novel self-similarity-based method to filter out less meaningful tokens. Inspired by findings in contrastive learning that self-similarities of functional token embeddings in different contexts are much lower than topical tokens, we find self-similarity to be an effective metric to prevent functional words from acting as candidate topic words. Our approach significantly enhances the coherence and diversity of generated topics, as well as the topic model's ability to handle noisy data. Experiments on news benchmark datasets and one Twitter dataset demonstrate the method's superiority in generating coherent, diverse topics, and handling noisy data, outperforming strong baselines.