 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess-based Self-Rewarding Language Models
Mar 05, 2025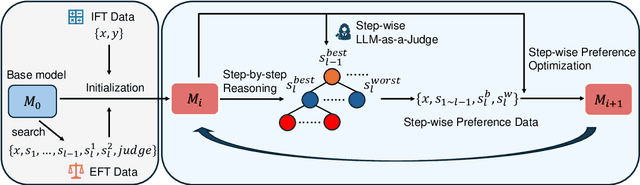
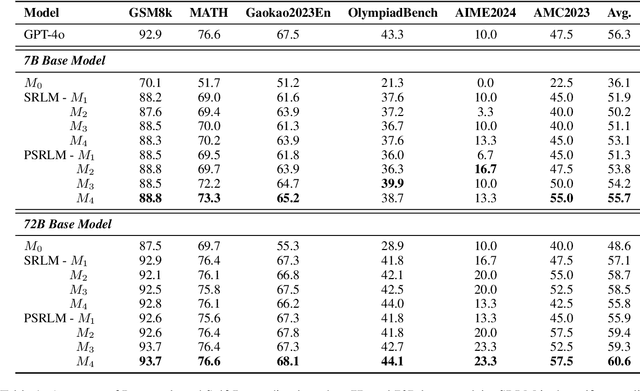

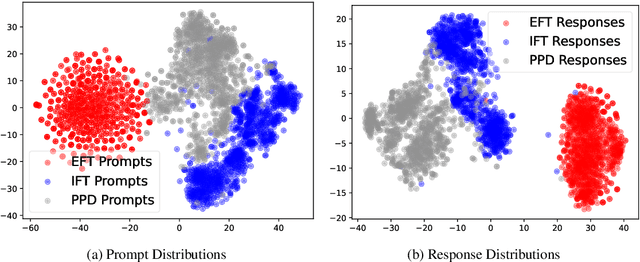
Large Language Models have demonstrated outstanding performance across various downstream tasks and have been widely applied in multiple scenarios. Human-annotated preference data is used for training to further improve LLMs' performance, which is constrained by the upper limit of human performance. Therefore, Self-Rewarding method has been proposed, where LLMs generate training data by rewarding their own outputs. However, the existing self-rewarding paradigm is not effective in mathematical reasoning scenarios and may even lead to a decline in performance. In this work, we propose the Process-based Self-Rewarding pipeline for language models, which introduces long-thought reasoning, step-wise LLM-as-a-Judge, and step-wise preference optimization within the self-rewarding paradigm. Our new paradigm successfully enhances the performance of LLMs on multiple mathematical reasoning benchmarks through iterative Process-based Self-Rewarding, demonstrating the immense potential of self-rewarding to achieve LLM reasoning that may surpass human capabilities.
Sigma: Differential Rescaling of Query, Key and Value for Efficient Language Models
Jan 23, 2025



We introduce Sigma, an efficient large language model specialized for the system domain, empowered by a novel architecture including DiffQKV attention, and pre-trained on our meticulously collected system domain data. DiffQKV attention significantly enhances the inference efficiency of Sigma by optimizing the Query (Q), Key (K), and Value (V) components in the attention mechanism differentially, based on their varying impacts on the model performance and efficiency indicators. Specifically, we (1) conduct extensive experiments that demonstrate the model's varying sensitivity to the compression of K and V components, leading to the development of differentially compressed KV, and (2) propose augmented Q to expand the Q head dimension, which enhances the model's representation capacity with minimal impacts on the inference speed. Rigorous theoretical and empirical analyses reveal that DiffQKV attention significantly enhances efficiency, achieving up to a 33.36% improvement in inference speed over the conventional grouped-query attention (GQA) in long-context scenarios. We pre-train Sigma on 6T tokens from various sources, including 19.5B system domain data that we carefully collect and 1T tokens of synthesized and rewritten data. In general domains, Sigma achieves comparable performance to other state-of-arts models. In the system domain, we introduce the first comprehensive benchmark AIMicius, where Sigma demonstrates remarkable performance across all tasks, significantly outperforming GPT-4 with an absolute improvement up to 52.5%.
Velocitune: A Velocity-based Dynamic Domain Reweighting Method for Continual Pre-training
Nov 21, 2024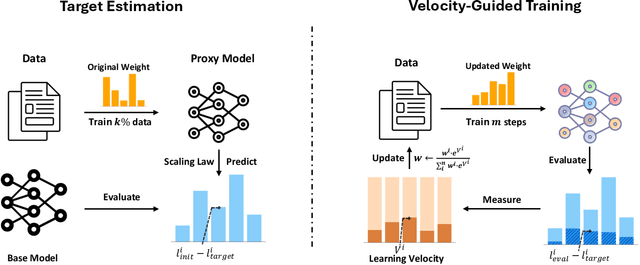
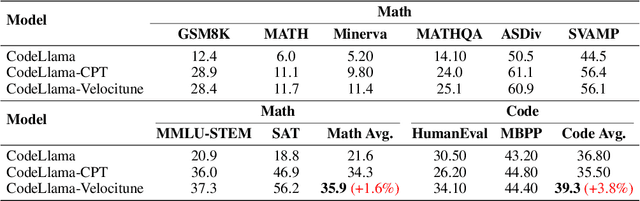
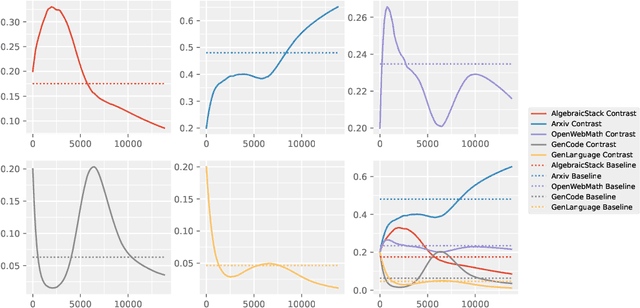
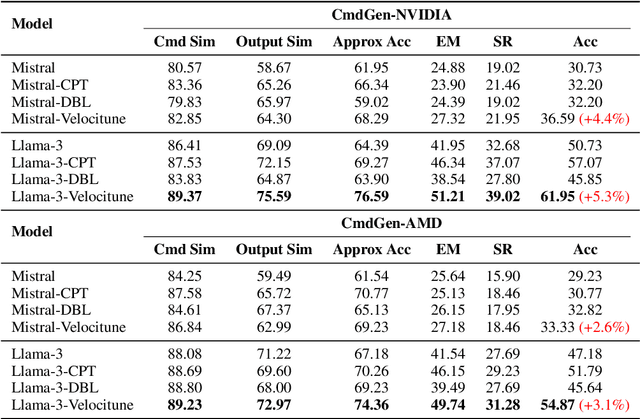
It is well-known that a diverse corpus is critical for training large language models, which are typically constructed from a mixture of various domains. In general, previous efforts resort to sampling training data from different domains with static proportions, as well as adjusting data proportions during training. However, few methods have addressed the complexities of domain-adaptive continual pre-training. To fill this gap, we propose Velocitune, a novel framework dynamically assesses learning velocity and adjusts data proportions accordingly, favoring slower-learning domains while shunning faster-learning ones, which is guided by a scaling law to indicate the desired learning goal for each domain with less associated cost. To evaluate the effectiveness of Velocitune, we conduct experiments in a reasoning-focused dataset with CodeLlama, as well as in a corpus specialised for system command generation with Llama3 and Mistral. Velocitune achieves performance gains in both math and code reasoning tasks and command-line generation benchmarks. Further analysis reveals that key factors driving Velocitune's effectiveness include target loss prediction and data ordering.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024
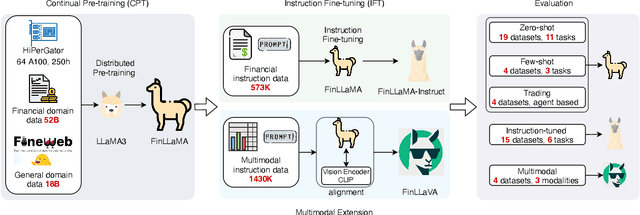
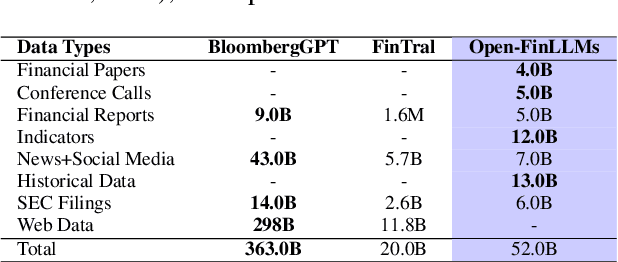
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
Are Large Language Models True Healthcare Jacks-of-All-Trades? Benchmarking Across Health Professions Beyond Physician Exams
Jun 17, 2024

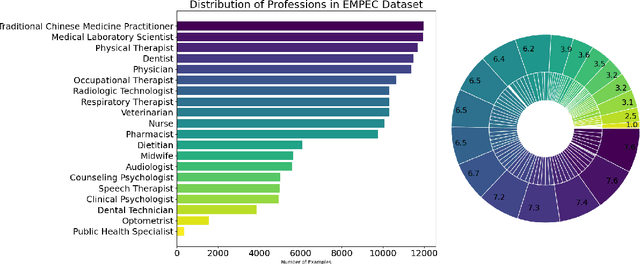

Recent advancements in Large Language Models (LLMs) have demonstrated their potential in delivering accurate answers to questions about world knowledge. Despite this, existing benchmarks for evaluating LLMs in healthcare predominantly focus on medical doctors, leaving other critical healthcare professions underrepresented. To fill this research gap, we introduce the Examinations for Medical Personnel in Chinese (EMPEC), a pioneering large-scale healthcare knowledge benchmark in traditional Chinese. EMPEC consists of 157,803 exam questions across 124 subjects and 20 healthcare professions, including underrepresented occupations like Optometrists and Audiologists. Each question is tagged with its release time and source, ensuring relevance and authenticity. We conducted extensive experiments on 17 LLMs, including proprietary, open-source models, general domain models and medical specific models, evaluating their performance under various settings. Our findings reveal that while leading models like GPT-4 achieve over 75\% accuracy, they still struggle with specialized fields and alternative medicine. Surprisingly, general-purpose LLMs outperformed medical-specific models, and incorporating EMPEC's training data significantly enhanced performance. Additionally, the results on questions released after the models' training cutoff date were consistent with overall performance trends, suggesting that the models' performance on the test set can predict their effectiveness in addressing unseen healthcare-related queries. The transition from traditional to simplified Chinese characters had a negligible impact on model performance, indicating robust linguistic versatility. Our study underscores the importance of expanding benchmarks to cover a broader range of healthcare professions to better assess the applicability of LLMs in real-world healthcare scenarios.
Factual Consistency Evaluation of Summarisation in the Era of Large Language Models
Feb 21, 2024



Factual inconsistency with source documents in automatically generated summaries can lead to misinformation or pose risks. Existing factual consistency(FC) metrics are constrained by their performance, efficiency, and explainability. Recent advances in Large language models (LLMs) have demonstrated remarkable potential in text evaluation but their effectiveness in assessing FC in summarisation remains underexplored. Prior research has mostly focused on proprietary LLMs, leaving essential factors that affect their assessment capabilities unexplored. Additionally, current FC evaluation benchmarks are restricted to news articles, casting doubt on the generality of the FC methods tested on them. In this paper, we first address the gap by introducing TreatFact a dataset of LLM-generated summaries of clinical texts, annotated for FC by domain experts. Moreover, we benchmark 11 LLMs for FC evaluation across news and clinical domains and analyse the impact of model size, prompts, pre-training and fine-tuning data. Our findings reveal that despite proprietary models prevailing on the task, open-source LLMs lag behind. Nevertheless, there is potential for enhancing the performance of open-source LLMs through increasing model size, expanding pre-training data, and developing well-curated fine-tuning data. Experiments on TreatFact suggest that both previous methods and LLM-based evaluators are unable to capture factual inconsistencies in clinical summaries, posing a new challenge for FC evaluation.
The Lay Person's Guide to Biomedicine: Orchestrating Large Language Models
Feb 21, 2024Automated lay summarisation (LS) aims to simplify complex technical documents into a more accessible format to non-experts. Existing approaches using pre-trained language models, possibly augmented with external background knowledge, tend to struggle with effective simplification and explanation. Moreover, automated methods that can effectively assess the `layness' of generated summaries are lacking. Recently, large language models (LLMs) have demonstrated a remarkable capacity for text simplification, background information generation, and text evaluation. This has motivated our systematic exploration into using LLMs to generate and evaluate lay summaries of biomedical articles. We propose a novel \textit{Explain-then-Summarise} LS framework, which leverages LLMs to generate high-quality background knowledge to improve supervised LS. We also evaluate the performance of LLMs for zero-shot LS and propose two novel LLM-based LS evaluation metrics, which assess layness from multiple perspectives. Finally, we conduct a human assessment of generated lay summaries. Our experiments reveal that LLM-generated background information can support improved supervised LS. Furthermore, our novel zero-shot LS evaluation metric demonstrates a high degree of alignment with human preferences. We conclude that LLMs have an important part to play in improving both the performance and evaluation of LS methods.
The FinBen: An Holistic Financial Benchmark for Large Language Models
Feb 20, 2024



LLMs have transformed NLP and shown promise in various fields, yet their potential in finance is underexplored due to a lack of thorough evaluations and the complexity of financial tasks. This along with the rapid development of LLMs, highlights the urgent need for a systematic financial evaluation benchmark for LLMs. In this paper, we introduce FinBen, the first comprehensive open-sourced evaluation benchmark, specifically designed to thoroughly assess the capabilities of LLMs in the financial domain. FinBen encompasses 35 datasets across 23 financial tasks, organized into three spectrums of difficulty inspired by the Cattell-Horn-Carroll theory, to evaluate LLMs' cognitive abilities in inductive reasoning, associative memory, quantitative reasoning, crystallized intelligence, and more. Our evaluation of 15 representative LLMs, including GPT-4, ChatGPT, and the latest Gemini, reveals insights into their strengths and limitations within the financial domain. The findings indicate that GPT-4 leads in quantification, extraction, numerical reasoning, and stock trading, while Gemini shines in generation and forecasting; however, both struggle with complex extraction and forecasting, showing a clear need for targeted enhancements. Instruction tuning boosts simple task performance but falls short in improving complex reasoning and forecasting abilities. FinBen seeks to continuously evaluate LLMs in finance, fostering AI development with regular updates of tasks and models.
Overview of the BioLaySumm 2023 Shared Task on Lay Summarization of Biomedical Research Articles
Sep 29, 2023



This paper presents the results of the shared task on Lay Summarisation of Biomedical Research Articles (BioLaySumm), hosted at the BioNLP Workshop at ACL 2023. The goal of this shared task is to develop abstractive summarisation models capable of generating "lay summaries" (i.e., summaries that are comprehensible to non-technical audiences) in both a controllable and non-controllable setting. There are two subtasks: 1) Lay Summarisation, where the goal is for participants to build models for lay summary generation only, given the full article text and the corresponding abstract as input; and 2) Readability-controlled Summarisation, where the goal is for participants to train models to generate both the technical abstract and the lay summary, given an article's main text as input. In addition to overall results, we report on the setup and insights from the BioLaySumm shared task, which attracted a total of 20 participating teams across both subtasks.
* Published at BioNLP@ACL2023
Graph Contrastive Topic Model
Jul 05, 2023Existing NTMs with contrastive learning suffer from the sample bias problem owing to the word frequency-based sampling strategy, which may result in false negative samples with similar semantics to the prototypes. In this paper, we aim to explore the efficient sampling strategy and contrastive learning in NTMs to address the aforementioned issue. We propose a new sampling assumption that negative samples should contain words that are semantically irrelevant to the prototype. Based on it, we propose the graph contrastive topic model (GCTM), which conducts graph contrastive learning (GCL) using informative positive and negative samples that are generated by the graph-based sampling strategy leveraging in-depth correlation and irrelevance among documents and words. In GCTM, we first model the input document as the document word bipartite graph (DWBG), and construct positive and negative word co-occurrence graphs (WCGs), encoded by graph neural networks, to express in-depth semantic correlation and irrelevance among words. Based on the DWBG and WCGs, we design the document-word information propagation (DWIP) process to perform the edge perturbation of DWBG, based on multi-hop correlations/irrelevance among documents and words. This yields the desired negative and positive samples, which will be utilized for GCL together with the prototypes to improve learning document topic representations and latent topics. We further show that GCL can be interpreted as the structured variational graph auto-encoder which maximizes the mutual information of latent topic representations of different perspectives on DWBG. Experiments on several benchmark datasets demonstrate the effectiveness of our method for topic coherence and document representation learning compared with existing SOTA methods.