 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024
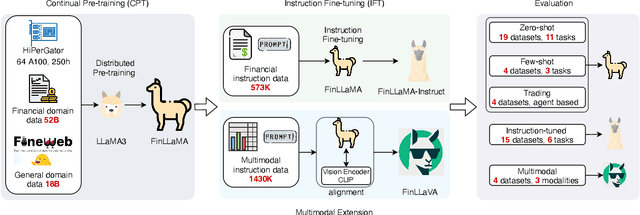
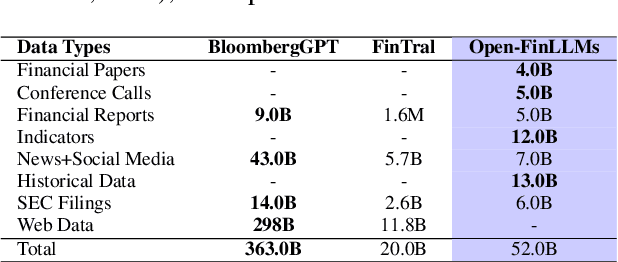
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
HARMONIC: Harnessing LLMs for Tabular Data Synthesis and Privacy Protection
Aug 06, 2024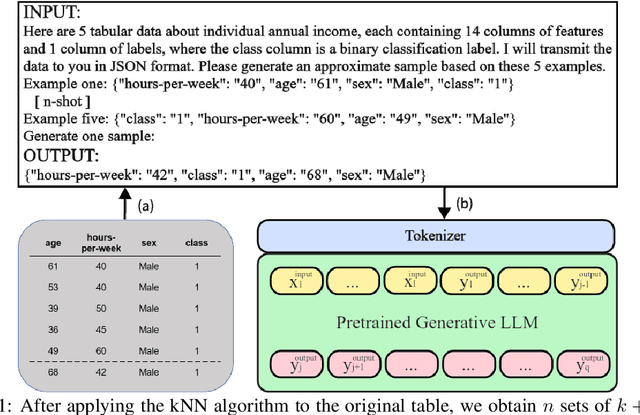

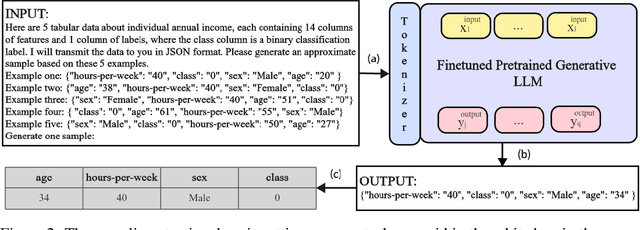

Data serves as the fundamental foundation for advancing deep learning, particularly tabular data presented in a structured format, which is highly conducive to modeling. However, even in the era of LLM, obtaining tabular data from sensitive domains remains a challenge due to privacy or copyright concerns. Hence, exploring how to effectively use models like LLMs to generate realistic and privacy-preserving synthetic tabular data is urgent. In this paper, we take a step forward to explore LLMs for tabular data synthesis and privacy protection, by introducing a new framework HARMONIC for tabular data generation and evaluation. In the tabular data generation of our framework, unlike previous small-scale LLM-based methods that rely on continued pre-training, we explore the larger-scale LLMs with fine-tuning to generate tabular data and enhance privacy. Based on idea of the k-nearest neighbors algorithm, an instruction fine-tuning dataset is constructed to inspire LLMs to discover inter-row relationships. Then, with fine-tuning, LLMs are trained to remember the format and connections of the data rather than the data itself, which reduces the risk of privacy leakage. In the evaluation part of our framework, we develop specific privacy risk metrics DLT for LLM synthetic data generation, as well as performance evaluation metrics LLE for downstream LLM tasks. Our experiments find that this tabular data generation framework achieves equivalent performance to existing methods with better privacy, which also demonstrates our evaluation framework for the effectiveness of synthetic data and privacy risks in LLM scenarios.
The FinBen: An Holistic Financial Benchmark for Large Language Models
Feb 20, 2024



LLMs have transformed NLP and shown promise in various fields, yet their potential in finance is underexplored due to a lack of thorough evaluations and the complexity of financial tasks. This along with the rapid development of LLMs, highlights the urgent need for a systematic financial evaluation benchmark for LLMs. In this paper, we introduce FinBen, the first comprehensive open-sourced evaluation benchmark, specifically designed to thoroughly assess the capabilities of LLMs in the financial domain. FinBen encompasses 35 datasets across 23 financial tasks, organized into three spectrums of difficulty inspired by the Cattell-Horn-Carroll theory, to evaluate LLMs' cognitive abilities in inductive reasoning, associative memory, quantitative reasoning, crystallized intelligence, and more. Our evaluation of 15 representative LLMs, including GPT-4, ChatGPT, and the latest Gemini, reveals insights into their strengths and limitations within the financial domain. The findings indicate that GPT-4 leads in quantification, extraction, numerical reasoning, and stock trading, while Gemini shines in generation and forecasting; however, both struggle with complex extraction and forecasting, showing a clear need for targeted enhancements. Instruction tuning boosts simple task performance but falls short in improving complex reasoning and forecasting abilities. FinBen seeks to continuously evaluate LLMs in finance, fostering AI development with regular updates of tasks and models.
LAiW: A Chinese Legal Large Language Models Benchmark
Oct 09, 2023With the emergence of numerous legal LLMs, there is currently a lack of a comprehensive benchmark for evaluating their legal abilities. In this paper, we propose the first Chinese Legal LLMs benchmark based on legal capabilities. Through the collaborative efforts of legal and artificial intelligence experts, we divide the legal capabilities of LLMs into three levels: basic legal NLP capability, basic legal application capability, and complex legal application capability. We have completed the first phase of evaluation, which mainly focuses on the capability of basic legal NLP. The evaluation results show that although some legal LLMs have better performance than their backbones, there is still a gap compared to ChatGPT. Our benchmark can be found at URL.
Empowering Many, Biasing a Few: Generalist Credit Scoring through Large Language Models
Oct 01, 2023



Credit and risk assessments are cornerstones of the financial landscape, impacting both individual futures and broader societal constructs. Existing credit scoring models often exhibit limitations stemming from knowledge myopia and task isolation. In response, we formulate three hypotheses and undertake an extensive case study to investigate LLMs' viability in credit assessment. Our empirical investigations unveil LLMs' ability to overcome the limitations inherent in conventional models. We introduce a novel benchmark curated for credit assessment purposes, fine-tune a specialized Credit and Risk Assessment Large Language Model (CALM), and rigorously examine the biases that LLMs may harbor. Our findings underscore LLMs' potential in revolutionizing credit assessment, showcasing their adaptability across diverse financial evaluations, and emphasizing the critical importance of impartial decision-making in the financial sector. Our datasets, models, and benchmarks are open-sourced for other researchers.