 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVelocitune: A Velocity-based Dynamic Domain Reweighting Method for Continual Pre-training
Nov 21, 2024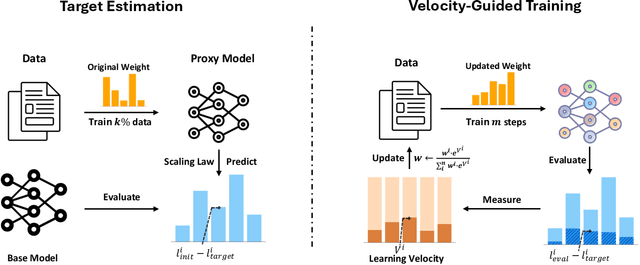
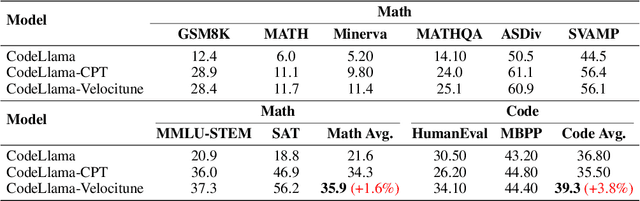
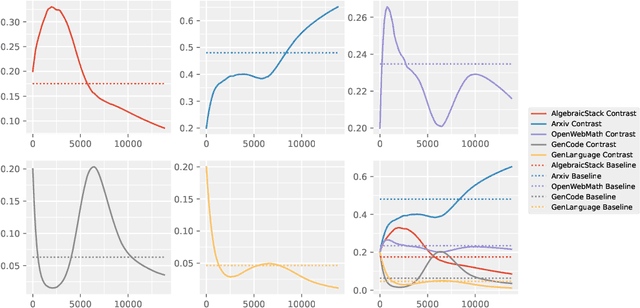
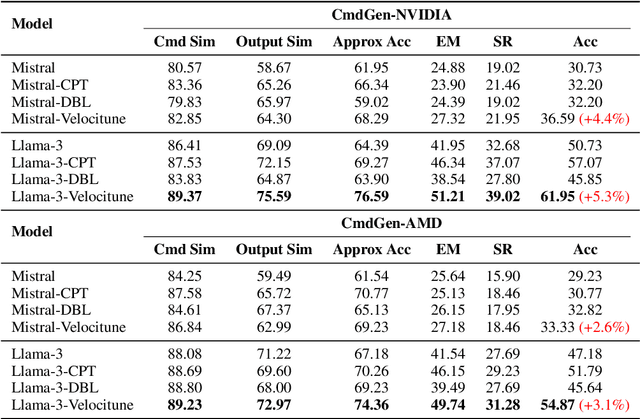
It is well-known that a diverse corpus is critical for training large language models, which are typically constructed from a mixture of various domains. In general, previous efforts resort to sampling training data from different domains with static proportions, as well as adjusting data proportions during training. However, few methods have addressed the complexities of domain-adaptive continual pre-training. To fill this gap, we propose Velocitune, a novel framework dynamically assesses learning velocity and adjusts data proportions accordingly, favoring slower-learning domains while shunning faster-learning ones, which is guided by a scaling law to indicate the desired learning goal for each domain with less associated cost. To evaluate the effectiveness of Velocitune, we conduct experiments in a reasoning-focused dataset with CodeLlama, as well as in a corpus specialised for system command generation with Llama3 and Mistral. Velocitune achieves performance gains in both math and code reasoning tasks and command-line generation benchmarks. Further analysis reveals that key factors driving Velocitune's effectiveness include target loss prediction and data ordering.
ACT-GAN: Radio map construction based on generative adversarial networks with ACT blocks
Jan 17, 2024


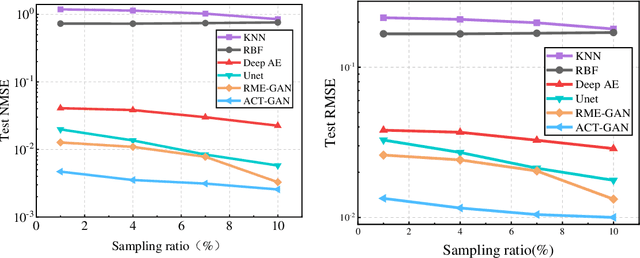
The radio map, serving as a visual representation of electromagnetic spatial characteristics, plays a pivotal role in assessment of wireless communication networks and radio monitoring coverage. Addressing the issue of low accuracy existing in the current radio map construction, this paper presents a novel radio map construction method based on generative adversarial network (GAN) in which the Aggregated Contextual-Transformation (AOT) block, Convolutional Block Attention Module (CBAM), and Transposed Convolution (T-Conv) block are applied to the generator, and we name it as ACT-GAN. It significantly improves the reconstruction accuracy and local texture of the radio maps. The performance of ACT-GAN across three different scenarios is demonstrated. Experiment results reveal that in the scenario without sparse discrete observations, the proposed method reduces the root mean square error (RMSE) by 14.6% in comparison to the state-of-the-art models. In the scenario with sparse discrete observations, the RMSE is diminished by 13.2%. Furthermore, the predictive results of the proposed model show a more lucid representation of electromagnetic spatial field distribution. To verify the universality of this model in radio map construction tasks, the scenario of unknown radio emission source is investigated. The results indicate that the proposed model is robust radio map construction and accurate in predicting the location of the emission source.
Deep Reinforcement Learning with Discrete Normalized Advantage Functions for Resource Management in Network Slicing
Jun 10, 2019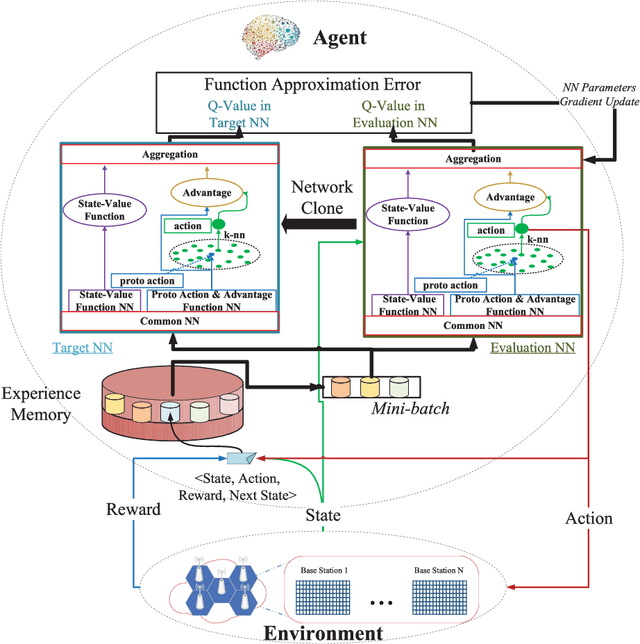
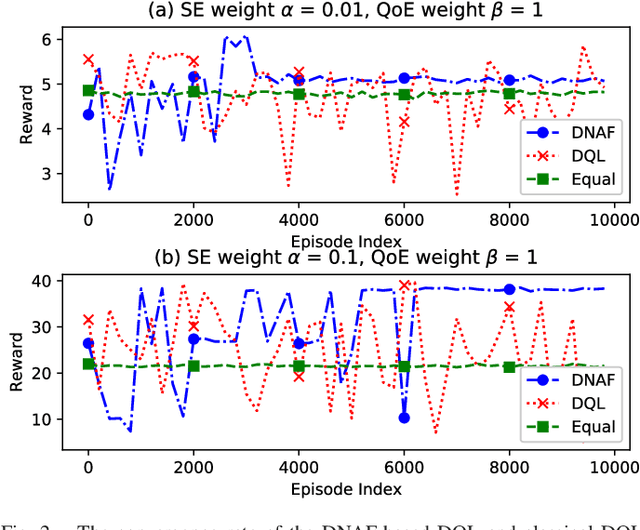
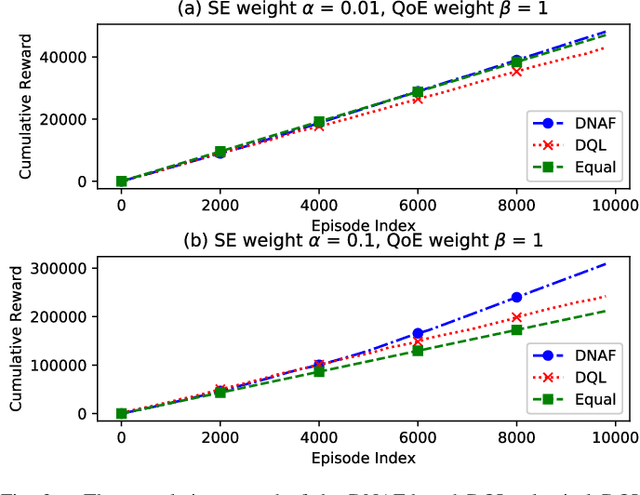
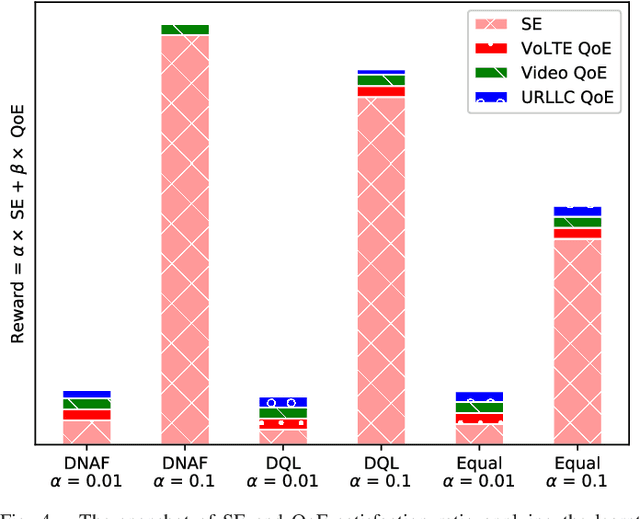
Network slicing promises to provision diversified services with distinct requirements in one infrastructure. Deep reinforcement learning (e.g., deep $\mathcal{Q}$-learning, DQL) is assumed to be an appropriate algorithm to solve the demand-aware inter-slice resource management issue in network slicing by regarding the varying demands and the allocated bandwidth as the environment state and the action, respectively. However, allocating bandwidth in a finer resolution usually implies larger action space, and unfortunately DQL fails to quickly converge in this case. In this paper, we introduce discrete normalized advantage functions (DNAF) into DQL, by separating the $\mathcal{Q}$-value function as a state-value function term and an advantage term and exploiting a deterministic policy gradient descent (DPGD) algorithm to avoid the unnecessary calculation of $\mathcal{Q}$-value for every state-action pair. Furthermore, as DPGD only works in continuous action space, we embed a k-nearest neighbor algorithm into DQL to quickly find a valid action in the discrete space nearest to the DPGD output. Finally, we verify the faster convergence of the DNAF-based DQL through extensive simulations.