 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Large Language Models True Healthcare Jacks-of-All-Trades? Benchmarking Across Health Professions Beyond Physician Exams
Paper and Code


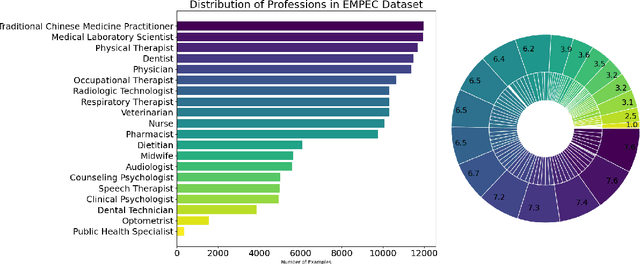

Recent advancements in Large Language Models (LLMs) have demonstrated their potential in delivering accurate answers to questions about world knowledge. Despite this, existing benchmarks for evaluating LLMs in healthcare predominantly focus on medical doctors, leaving other critical healthcare professions underrepresented. To fill this research gap, we introduce the Examinations for Medical Personnel in Chinese (EMPEC), a pioneering large-scale healthcare knowledge benchmark in traditional Chinese. EMPEC consists of 157,803 exam questions across 124 subjects and 20 healthcare professions, including underrepresented occupations like Optometrists and Audiologists. Each question is tagged with its release time and source, ensuring relevance and authenticity. We conducted extensive experiments on 17 LLMs, including proprietary, open-source models, general domain models and medical specific models, evaluating their performance under various settings. Our findings reveal that while leading models like GPT-4 achieve over 75\% accuracy, they still struggle with specialized fields and alternative medicine. Surprisingly, general-purpose LLMs outperformed medical-specific models, and incorporating EMPEC's training data significantly enhanced performance. Additionally, the results on questions released after the models' training cutoff date were consistent with overall performance trends, suggesting that the models' performance on the test set can predict their effectiveness in addressing unseen healthcare-related queries. The transition from traditional to simplified Chinese characters had a negligible impact on model performance, indicating robust linguistic versatility. Our study underscores the importance of expanding benchmarks to cover a broader range of healthcare professions to better assess the applicability of LLMs in real-world healthcare scenarios.