 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCA-HFP: Curvature-Aware Heterogeneous Federated Pruning with Model Reconstruction
Mar 13, 2026Federated learning on heterogeneous edge devices requires personalized compression while preserving aggregation compatibility and stable convergence. We present Curvature-Aware Heterogeneous Federated Pruning (CA-HFP), a practical framework that enables each client perform structured, device-specific pruning guided by a curvature-informed significance score, and subsequently maps its compact submodel back into a common global parameter space via a lightweight reconstruction. We derive a convergence bound for federated optimization with multiple local SGD steps that explicitly accounts for local computation, data heterogeneity, and pruning-induced perturbations; from which a principled loss-based pruning criterion is derived. Extensive experiments on FMNIST, CIFAR-10, and CIFAR-100 using VGG and ResNet architectures under varying degrees of data heterogeneity demonstrate that CA-HFP preserves model accuracy while significantly reducing per-client computation and communication costs, outperforming standard federated training and existing pruning-based baselines.
FFT-MoE: Efficient Federated Fine-Tuning for Foundation Models via Large-scale Sparse MoE under Heterogeneous Edge
Aug 26, 2025As FMs drive progress toward Artificial General Intelligence (AGI), fine-tuning them under privacy and resource constraints has become increasingly critical particularly when highquality training data resides on distributed edge devices. Federated Learning (FL) offers a compelling solution through Federated Fine-Tuning (FFT), which enables collaborative model adaptation without sharing raw data. Recent approaches incorporate Parameter-Efficient Fine-Tuning (PEFT) techniques such as Low Rank Adaptation (LoRA) to reduce computational overhead. However, LoRA-based FFT faces two major limitations in heterogeneous FL environments: structural incompatibility across clients with varying LoRA configurations and limited adaptability to non-IID data distributions, which hinders convergence and generalization. To address these challenges, we propose FFT MoE, a novel FFT framework that replaces LoRA with sparse Mixture of Experts (MoE) adapters. Each client trains a lightweight gating network to selectively activate a personalized subset of experts, enabling fine-grained adaptation to local resource budgets while preserving aggregation compatibility. To further combat the expert load imbalance caused by device and data heterogeneity, we introduce a heterogeneity-aware auxiliary loss that dynamically regularizes the routing distribution to ensure expert diversity and balanced utilization. Extensive experiments spanning both IID and non-IID conditions demonstrate that FFT MoE consistently outperforms state of the art FFT baselines in generalization performance and training efficiency.
Split Federated Learning Over Heterogeneous Edge Devices: Algorithm and Optimization
Nov 21, 2024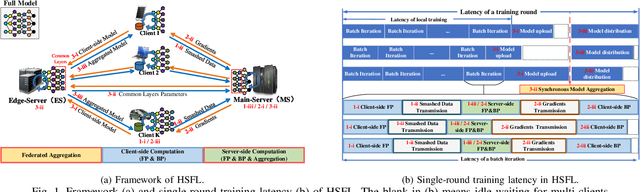
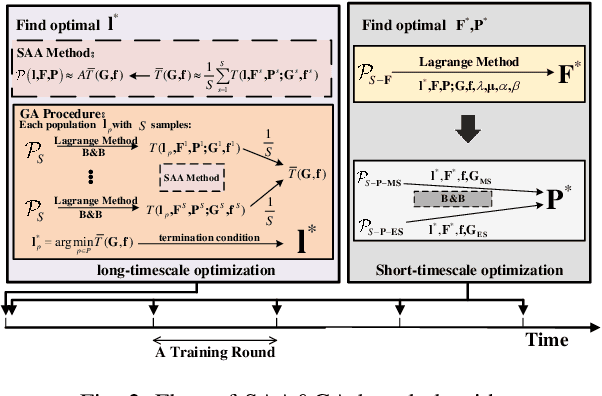
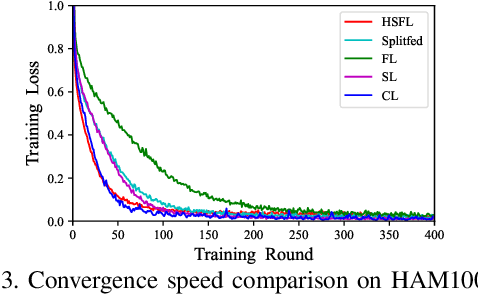
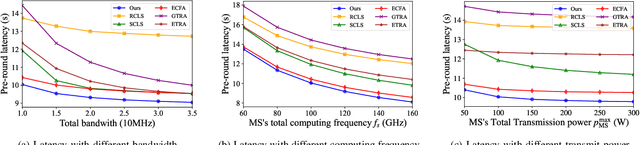
Split Learning (SL) is a promising collaborative machine learning approach, enabling resource-constrained devices to train models without sharing raw data, while reducing computational load and preserving privacy simultaneously. However, current SL algorithms face limitations in training efficiency and suffer from prolonged latency, particularly in sequential settings, where the slowest device can bottleneck the entire process due to heterogeneous resources and frequent data exchanges between clients and servers. To address these challenges, we propose the Heterogeneous Split Federated Learning (HSFL) framework, which allows resource-constrained clients to train their personalized client-side models in parallel, utilizing different cut layers. Aiming to mitigate the impact of heterogeneous environments and accelerate the training process, we formulate a latency minimization problem that optimizes computational and transmission resources jointly. Additionally, we design a resource allocation algorithm that combines the Sample Average Approximation (SAA), Genetic Algorithm (GA), Lagrangian relaxation and Branch and Bound (B\&B) methods to efficiently solve this problem. Simulation results demonstrate that HSFL outperforms other frameworks in terms of both convergence rate and model accuracy on heterogeneous devices with non-iid data, while the optimization algorithm is better than other baseline methods in reducing latency.
Faster Convergence on Heterogeneous Federated Edge Learning: An Adaptive Sidelink-Assisted Data Multicasting Approach
Jun 14, 2024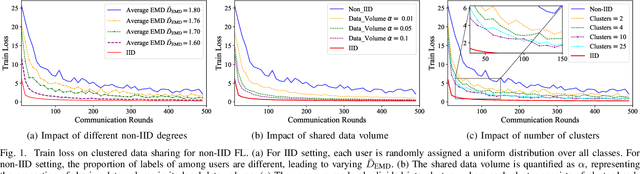


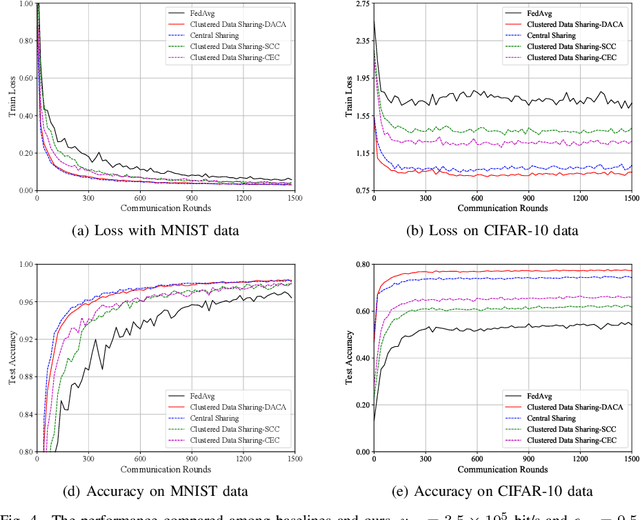
Federated Edge Learning (FEEL) emerges as a pioneering distributed machine learning paradigm for the 6G Hyper-Connectivity, harnessing data from the Internet of Things (IoT) devices while upholding data privacy. However, current FEEL algorithms struggle with non-independent and non-identically distributed (non-IID) data, leading to elevated communication costs and compromised model accuracy. To address these statistical imbalances within FEEL, we introduce a clustered data sharing framework, mitigating data heterogeneity by selectively sharing partial data from cluster heads to trusted associates through sidelink-aided multicasting. The collective communication pattern is integral to FEEL training, where both cluster formation and the efficiency of communication and computation impact training latency and accuracy simultaneously. To tackle the strictly coupled data sharing and resource optimization, we decompose the overall optimization problem into the clients clustering and effective data sharing subproblems. Specifically, a distribution-based adaptive clustering algorithm (DACA) is devised basing on three deductive cluster forming conditions, which ensures the maximum sharing yield. Meanwhile, we design a stochastic optimization based joint computed frequency and shared data volume optimization (JFVO) algorithm, determining the optimal resource allocation with an uncertain objective function. The experiments show that the proposed framework facilitates FEEL on non-IID datasets with faster convergence rate and higher model accuracy in a limited communication environment.
Markowitz Meets Bellman: Knowledge-distilled Reinforcement Learning for Portfolio Management
May 08, 2024Investment portfolios, central to finance, balance potential returns and risks. This paper introduces a hybrid approach combining Markowitz's portfolio theory with reinforcement learning, utilizing knowledge distillation for training agents. In particular, our proposed method, called KDD (Knowledge Distillation DDPG), consist of two training stages: supervised and reinforcement learning stages. The trained agents optimize portfolio assembly. A comparative analysis against standard financial models and AI frameworks, using metrics like returns, the Sharpe ratio, and nine evaluation indices, reveals our model's superiority. It notably achieves the highest yield and Sharpe ratio of 2.03, ensuring top profitability with the lowest risk in comparable return scenarios.
No Language is an Island: Unifying Chinese and English in Financial Large Language Models, Instruction Data, and Benchmarks
Mar 10, 2024



While the progression of Large Language Models (LLMs) has notably propelled financial analysis, their application has largely been confined to singular language realms, leaving untapped the potential of bilingual Chinese-English capacity. To bridge this chasm, we introduce ICE-PIXIU, seamlessly amalgamating the ICE-INTENT model and ICE-FLARE benchmark for bilingual financial analysis. ICE-PIXIU uniquely integrates a spectrum of Chinese tasks, alongside translated and original English datasets, enriching the breadth and depth of bilingual financial modeling. It provides unrestricted access to diverse model variants, a substantial compilation of diverse cross-lingual and multi-modal instruction data, and an evaluation benchmark with expert annotations, comprising 10 NLP tasks, 20 bilingual specific tasks, totaling 1,185k datasets. Our thorough evaluation emphasizes the advantages of incorporating these bilingual datasets, especially in translation tasks and utilizing original English data, enhancing both linguistic flexibility and analytical acuity in financial contexts. Notably, ICE-INTENT distinguishes itself by showcasing significant enhancements over conventional LLMs and existing financial LLMs in bilingual milieus, underscoring the profound impact of robust bilingual data on the accuracy and efficacy of financial NLP.
The FinBen: An Holistic Financial Benchmark for Large Language Models
Feb 20, 2024



LLMs have transformed NLP and shown promise in various fields, yet their potential in finance is underexplored due to a lack of thorough evaluations and the complexity of financial tasks. This along with the rapid development of LLMs, highlights the urgent need for a systematic financial evaluation benchmark for LLMs. In this paper, we introduce FinBen, the first comprehensive open-sourced evaluation benchmark, specifically designed to thoroughly assess the capabilities of LLMs in the financial domain. FinBen encompasses 35 datasets across 23 financial tasks, organized into three spectrums of difficulty inspired by the Cattell-Horn-Carroll theory, to evaluate LLMs' cognitive abilities in inductive reasoning, associative memory, quantitative reasoning, crystallized intelligence, and more. Our evaluation of 15 representative LLMs, including GPT-4, ChatGPT, and the latest Gemini, reveals insights into their strengths and limitations within the financial domain. The findings indicate that GPT-4 leads in quantification, extraction, numerical reasoning, and stock trading, while Gemini shines in generation and forecasting; however, both struggle with complex extraction and forecasting, showing a clear need for targeted enhancements. Instruction tuning boosts simple task performance but falls short in improving complex reasoning and forecasting abilities. FinBen seeks to continuously evaluate LLMs in finance, fostering AI development with regular updates of tasks and models.
Dynamic Feature-based Deep Reinforcement Learning for Flow Control of Circular Cylinder with Sparse Surface Pressure Sensing
Jul 28, 2023This study proposes a self-learning algorithm for closed-loop cylinder wake control targeting lower drag and lower lift fluctuations with the additional challenge of sparse sensor information, taking deep reinforcement learning as the starting point. DRL performance is significantly improved by lifting the sensor signals to dynamic features (DF), which predict future flow states. The resulting dynamic feature-based DRL (DF-DRL) automatically learns a feedback control in the plant without a dynamic model. Results show that the drag coefficient of the DF-DRL model is 25% less than the vanilla model based on direct sensor feedback. More importantly, using only one surface pressure sensor, DF-DRL can reduce the drag coefficient to a state-of-the-art performance of about 8% at Re = 100 and significantly mitigate lift coefficient fluctuations. Hence, DF-DRL allows the deployment of sparse sensing of the flow without degrading the control performance. This method also shows good robustness in controlling flow under higher Reynolds numbers, which reduces the drag coefficient by 32.2% and 46.55% at Re = 500 and 1000, respectively, indicating the broad applicability of the method. Since surface pressure information is more straightforward to measure in realistic scenarios than flow velocity information, this study provides a valuable reference for experimentally designing the active flow control of a circular cylinder based on wall pressure signals, which is an essential step toward further developing intelligent control in realistic multi-input multi-output (MIMO) system.
SGDP: A Stream-Graph Neural Network Based Data Prefetcher
Apr 07, 2023



Data prefetching is important for storage system optimization and access performance improvement. Traditional prefetchers work well for mining access patterns of sequential logical block address (LBA) but cannot handle complex non-sequential patterns that commonly exist in real-world applications. The state-of-the-art (SOTA) learning-based prefetchers cover more LBA accesses. However, they do not adequately consider the spatial interdependencies between LBA deltas, which leads to limited performance and robustness. This paper proposes a novel Stream-Graph neural network-based Data Prefetcher (SGDP). Specifically, SGDP models LBA delta streams using a weighted directed graph structure to represent interactive relations among LBA deltas and further extracts hybrid features by graph neural networks for data prefetching. We conduct extensive experiments on eight real-world datasets. Empirical results verify that SGDP outperforms the SOTA methods in terms of the hit ratio by 6.21%, the effective prefetching ratio by 7.00%, and speeds up inference time by 3.13X on average. Besides, we generalize SGDP to different variants by different stream constructions, further expanding its application scenarios and demonstrating its robustness. SGDP offers a novel data prefetching solution and has been verified in commercial hybrid storage systems in the experimental phase. Our codes and appendix are available at https://github.com/yyysjz1997/SGDP/.
Clustered Data Sharing for Non-IID Federated Learning over Wireless Networks
Mar 01, 2023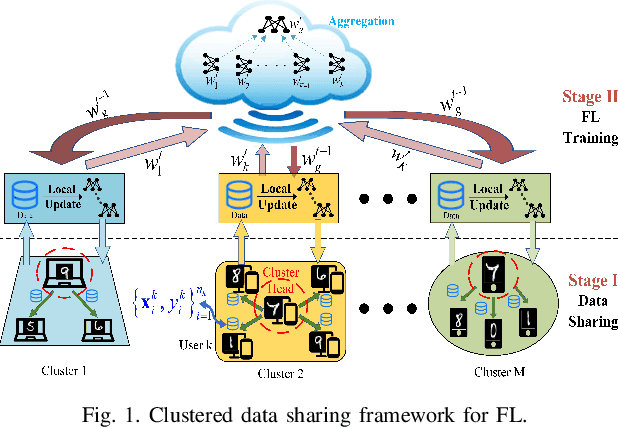
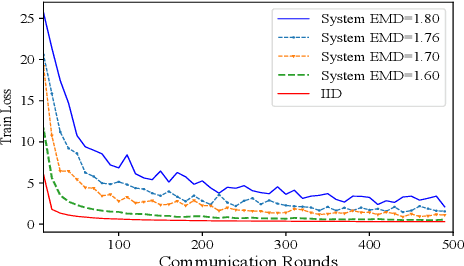
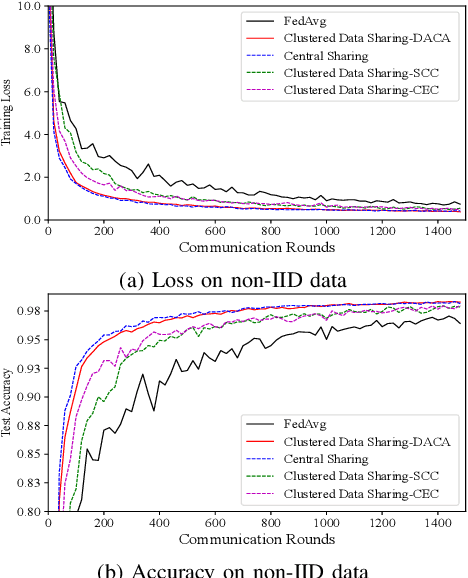
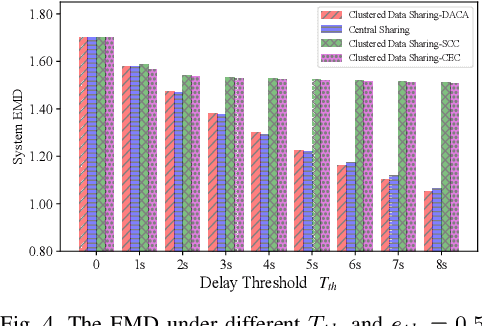
Federated Learning (FL) is a novel distributed machine learning approach to leverage data from Internet of Things (IoT) devices while maintaining data privacy. However, the current FL algorithms face the challenges of non-independent and identically distributed (non-IID) data, which causes high communication costs and model accuracy declines. To address the statistical imbalances in FL, we propose a clustered data sharing framework which spares the partial data from cluster heads to credible associates through device-to-device (D2D) communication. Moreover, aiming at diluting the data skew on nodes, we formulate the joint clustering and data sharing problem based on the privacy-preserving constrained graph. To tackle the serious coupling of decisions on the graph, we devise a distribution-based adaptive clustering algorithm (DACA) basing on three deductive cluster-forming conditions, which ensures the maximum yield of data sharing. The experiments show that the proposed framework facilitates FL on non-IID datasets with better convergence and model accuracy under a limited communication environment.