 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Convergence on Heterogeneous Federated Edge Learning: An Adaptive Sidelink-Assisted Data Multicasting Approach
Paper and Code
Jun 14, 2024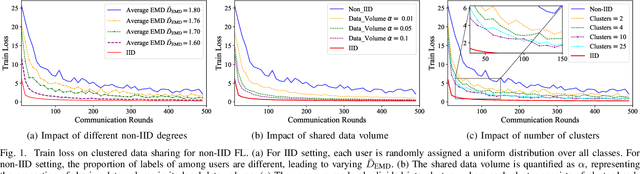


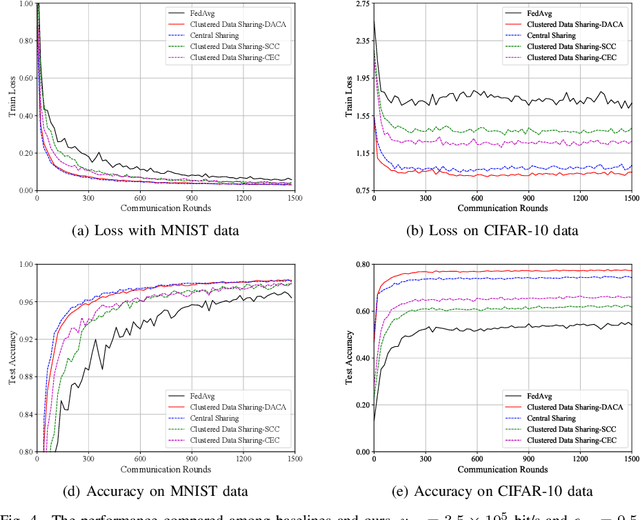
Federated Edge Learning (FEEL) emerges as a pioneering distributed machine learning paradigm for the 6G Hyper-Connectivity, harnessing data from the Internet of Things (IoT) devices while upholding data privacy. However, current FEEL algorithms struggle with non-independent and non-identically distributed (non-IID) data, leading to elevated communication costs and compromised model accuracy. To address these statistical imbalances within FEEL, we introduce a clustered data sharing framework, mitigating data heterogeneity by selectively sharing partial data from cluster heads to trusted associates through sidelink-aided multicasting. The collective communication pattern is integral to FEEL training, where both cluster formation and the efficiency of communication and computation impact training latency and accuracy simultaneously. To tackle the strictly coupled data sharing and resource optimization, we decompose the overall optimization problem into the clients clustering and effective data sharing subproblems. Specifically, a distribution-based adaptive clustering algorithm (DACA) is devised basing on three deductive cluster forming conditions, which ensures the maximum sharing yield. Meanwhile, we design a stochastic optimization based joint computed frequency and shared data volume optimization (JFVO) algorithm, determining the optimal resource allocation with an uncertain objective function. The experiments show that the proposed framework facilitates FEEL on non-IID datasets with faster convergence rate and higher model accuracy in a limited communication environment.