 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Feature-based Deep Reinforcement Learning for Flow Control of Circular Cylinder with Sparse Surface Pressure Sensing
Jul 28, 2023This study proposes a self-learning algorithm for closed-loop cylinder wake control targeting lower drag and lower lift fluctuations with the additional challenge of sparse sensor information, taking deep reinforcement learning as the starting point. DRL performance is significantly improved by lifting the sensor signals to dynamic features (DF), which predict future flow states. The resulting dynamic feature-based DRL (DF-DRL) automatically learns a feedback control in the plant without a dynamic model. Results show that the drag coefficient of the DF-DRL model is 25% less than the vanilla model based on direct sensor feedback. More importantly, using only one surface pressure sensor, DF-DRL can reduce the drag coefficient to a state-of-the-art performance of about 8% at Re = 100 and significantly mitigate lift coefficient fluctuations. Hence, DF-DRL allows the deployment of sparse sensing of the flow without degrading the control performance. This method also shows good robustness in controlling flow under higher Reynolds numbers, which reduces the drag coefficient by 32.2% and 46.55% at Re = 500 and 1000, respectively, indicating the broad applicability of the method. Since surface pressure information is more straightforward to measure in realistic scenarios than flow velocity information, this study provides a valuable reference for experimentally designing the active flow control of a circular cylinder based on wall pressure signals, which is an essential step toward further developing intelligent control in realistic multi-input multi-output (MIMO) system.
A fast converging particle swarm optimization through targeted, position-mutated, elitism (PSO-TPME)
Jul 02, 2022

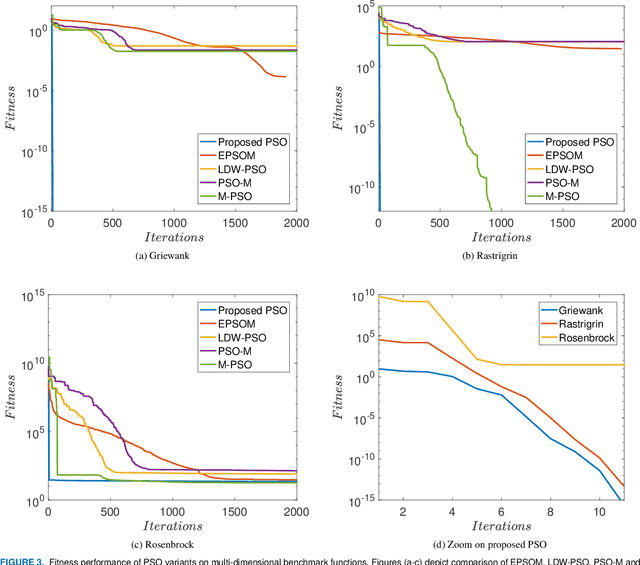
We dramatically improve convergence speed and global exploration capabilities of particle swarm optimization (PSO) through a targeted position-mutated elitism (PSO-TPME). The three key innovations address particle classification, elitism, and mutation in the cognitive and social model. PSO-TPME is benchmarked against five popular PSO variants for multi-dimensional functions, which are extensively adopted in the optimization field, In particular, the convergence accuracy, convergence speed, and the capability to find global minima is investigated. The statistical error is assessed by numerous repetitions. The simulations demonstrate that proposed PSO variant outperforms the other variants in terms of convergence rate and accuracy by orders of magnitude.