 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind Your Margin and Boundary: Are Your Distilled Datasets Truly Robust?
May 20, 2026Dataset distillation (DD) compresses a large training set into a small synthetic set for efficient training, but most DD methods optimize only clean accuracy and leave robustness uncontrolled. Recent robust DD methods improve robustness, yet they often suffer from a poor accuracy-robustness trade-off because they (i) treat all adversarially perturbed examples uniformly, despite robust risk being dominated by near-zero robust margins, and (ii) do not explicitly increase inter-class separation in the decision boundary where attacks concentrate. We present Contrastive Curriculum for Robust Dataset Distillation (C$^2$R), a framework that couples an attack-aware curriculum with a contrastive robustness objective. From a robust-margin perspective, we derive a perturbation score that approximates each sample's robust hinge, enabling a curriculum that prioritizes the smallest-margin adversaries that most directly drive robust error. In parallel, a class-balanced contrastive robustness loss enforces adversarial invariance while explicitly widening boundary separation across classes. Experiments on CIFAR-10/100, Tiny-ImageNet, and multiple ImageNet-1K subsets under six attacks show that C$^2$R achieves the best robust accuracy, outperforming prior robust DD by $2.8$% on average.
Mitigating KG Quality Issues: A Robust Multi-Hop GraphRAG Retrieval Framework
Mar 16, 2026Graph Retrieval-Augmented Generation enhances multi-hop reasoning but relies on imperfect knowledge graphs that frequently suffer from inherent quality issues. Current approaches often overlook these issues, consequently struggling with retrieval drift driven by spurious noise and retrieval hallucinations stemming from incomplete information. To address these challenges, we propose C2RAG (Constraint-Checked Retrieval-Augmented Generation), a framework aimed at robust multi-hop retrieval over the imperfect KG. First, C2RAG performs constraint-based retrieval by decomposing each query into atomic constraint triples, with using fine-grained constraint anchoring to filter candidates for suppressing retrieval drift. Second, C2RAG introduces a sufficiency check to explicitly prevent retrieval hallucinations by deciding whether the current evidence is sufficient to justify structural propagation, and activating textual recovery otherwise. Extensive experiments on multi-hop benchmarks demonstrate that C2RAG consistently outperforms the latest baselines by 3.4\% EM and 3.9\% F1 on average, while exhibiting improved robustness under KG issues.
KEPo: Knowledge Evolution Poison on Graph-based Retrieval-Augmented Generation
Mar 12, 2026Graph-based Retrieval-Augmented Generation (GraphRAG) constructs the Knowledge Graph (KG) from external databases to enhance the timeliness and accuracy of Large Language Model (LLM) generations.However,this reliance on external data introduces new attack surfaces.Attackers can inject poisoned texts into databases to manipulate LLMs into producing harmful target responses for attacker-chosen queries.Existing research primarily focuses on attacking conventional RAG systems.However,such methods are ineffective against GraphRAG.This robustness derives from the KG abstraction of GraphRAG,which reorganizes injected text into a graph before retrieval,thereby enabling the LLM to reason based on the restructured context instead of raw poisoned passages.To expose latent security vulnerabilities in GraphRAG,we propose Knowledge Evolution Poison (KEPo),a novel poisoning attack method specifically designed for GraphRAG.For each target query,KEPo first generates a toxic event containing poisoned knowledge based on the target answer.By fabricating event backgrounds and forging knowledge evolution paths from original facts to the toxic event,it then poisons the KG and misleads the LLM into treating the poisoned knowledge as the final result.In multi-target attack scenarios,KEPo further connects multiple attack corpora,enabling their poisoned knowledge to mutually reinforce while expanding the scale of poisoned communities,thereby amplifying attack effectiveness.Experimental results across multiple datasets demonstrate that KEPo achieves state-of-the-art attack success rates for both single-target and multi-target attacks,significantly outperforming previous methods.
Fixed Anchors Are Not Enough: Dynamic Retrieval and Persistent Homology for Dataset Distillation
Feb 27, 2026Decoupled dataset distillation (DD) compresses large corpora into a few synthetic images by matching a frozen teacher's statistics. However, current residual-matching pipelines rely on static real patches, creating a fit-complexity gap and a pull-to-anchor effect that reduce intra-class diversity and hurt generalization. To address these issues, we introduce RETA -- a Retrieval and Topology Alignment framework for decoupled DD. First, Dynamic Retrieval Connection (DRC) selects a real patch from a prebuilt pool by minimizing a fit-complexity score in teacher feature space; the chosen patch is injected via a residual connection to tighten feature fit while controlling injected complexity. Second, Persistent Topology Alignment (PTA) regularizes synthesis with persistent homology: we build a mutual k-NN feature graph, compute persistence images of components and loops, and penalize topology discrepancies between real and synthetic sets, mitigating pull-to-anchor effect. Across CIFAR-100, Tiny-ImageNet, ImageNet-1K, and multiple ImageNet subsets, RETA consistently outperforms various baselines under comparable time and memory, especially reaching 64.3% top-1 accuracy on ImageNet-1K with ResNet-18 at 50 images per class, +3.1% over the best prior.
LLM-based Embeddings: Attention Values Encode Sentence Semantics Better Than Hidden States
Feb 02, 2026Sentence representations are foundational to many Natural Language Processing (NLP) applications. While recent methods leverage Large Language Models (LLMs) to derive sentence representations, most rely on final-layer hidden states, which are optimized for next-token prediction and thus often fail to capture global, sentence-level semantics. This paper introduces a novel perspective, demonstrating that attention value vectors capture sentence semantics more effectively than hidden states. We propose Value Aggregation (VA), a simple method that pools token values across multiple layers and token indices. In a training-free setting, VA outperforms other LLM-based embeddings, even matches or surpasses the ensemble-based MetaEOL. Furthermore, we demonstrate that when paired with suitable prompts, the layer attention outputs can be interpreted as aligned weighted value vectors. Specifically, the attention scores of the last token function as the weights, while the output projection matrix ($W_O$) aligns these weighted value vectors with the common space of the LLM residual stream. This refined method, termed Aligned Weighted VA (AlignedWVA), achieves state-of-the-art performance among training-free LLM-based embeddings, outperforming the high-cost MetaEOL by a substantial margin. Finally, we highlight the potential of obtaining strong LLM embedding models through fine-tuning Value Aggregation.
Bid Farewell to Seesaw: Towards Accurate Long-tail Session-based Recommendation via Dual Constraints of Hybrid Intents
Nov 11, 2025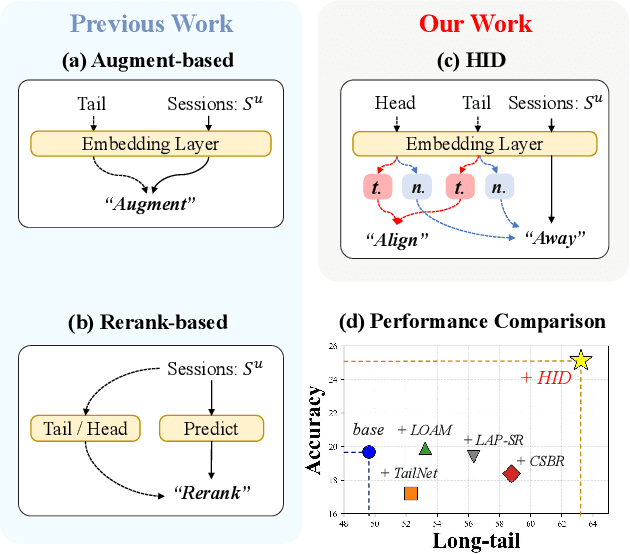
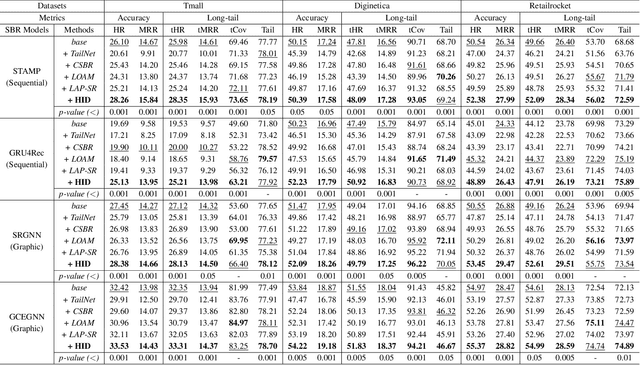
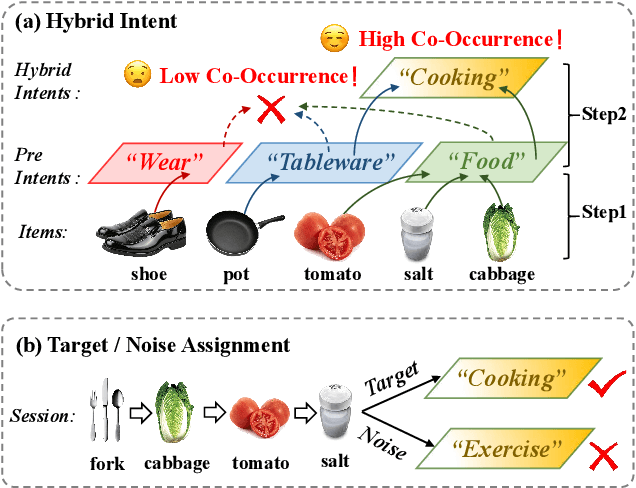

Session-based recommendation (SBR) aims to predict anonymous users' next interaction based on their interaction sessions. In the practical recommendation scenario, low-exposure items constitute the majority of interactions, creating a long-tail distribution that severely compromises recommendation diversity. Existing approaches attempt to address this issue by promoting tail items but incur accuracy degradation, exhibiting a "see-saw" effect between long-tail and accuracy performance. We attribute such conflict to session-irrelevant noise within the tail items, which existing long-tail approaches fail to identify and constrain effectively. To resolve this fundamental conflict, we propose \textbf{HID} (\textbf{H}ybrid \textbf{I}ntent-based \textbf{D}ual Constraint Framework), a plug-and-play framework that transforms the conventional "see-saw" into "win-win" through introducing the hybrid intent-based dual constraints for both long-tail and accuracy. Two key innovations are incorporated in this framework: (i) \textit{Hybrid Intent Learning}, where we reformulate the intent extraction strategies by employing attribute-aware spectral clustering to reconstruct the item-to-intent mapping. Furthermore, discrimination of session-irrelevant noise is achieved through the assignment of the target and noise intents to each session. (ii) \textit{Intent Constraint Loss}, which incorporates two novel constraint paradigms regarding the \textit{diversity} and \textit{accuracy} to regulate the representation learning process of both items and sessions. These two objectives are unified into a single training loss through rigorous theoretical derivation. Extensive experiments across multiple SBR models and datasets demonstrate that HID can enhance both long-tail performance and recommendation accuracy, establishing new state-of-the-art performance in long-tail recommender systems.
Beyond Random: Automatic Inner-loop Optimization in Dataset Distillation
Oct 06, 2025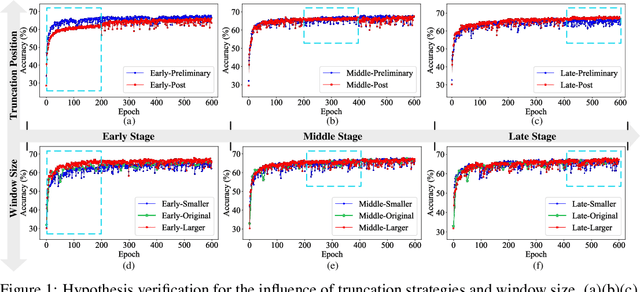
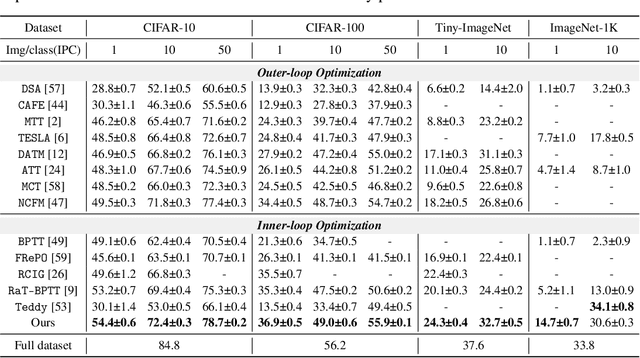
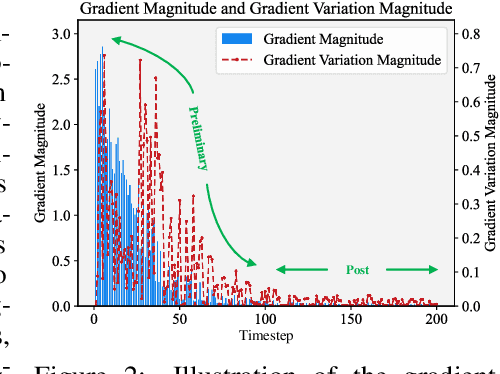
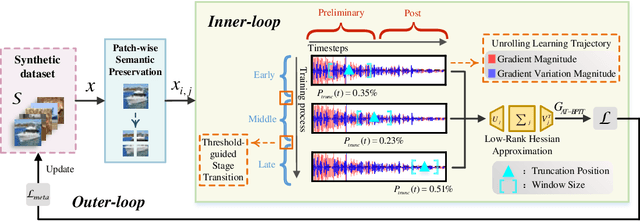
The growing demand for efficient deep learning has positioned dataset distillation as a pivotal technique for compressing training dataset while preserving model performance. However, existing inner-loop optimization methods for dataset distillation typically rely on random truncation strategies, which lack flexibility and often yield suboptimal results. In this work, we observe that neural networks exhibit distinct learning dynamics across different training stages-early, middle, and late-making random truncation ineffective. To address this limitation, we propose Automatic Truncated Backpropagation Through Time (AT-BPTT), a novel framework that dynamically adapts both truncation positions and window sizes according to intrinsic gradient behavior. AT-BPTT introduces three key components: (1) a probabilistic mechanism for stage-aware timestep selection, (2) an adaptive window sizing strategy based on gradient variation, and (3) a low-rank Hessian approximation to reduce computational overhead. Extensive experiments on CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet-1K show that AT-BPTT achieves state-of-the-art performance, improving accuracy by an average of 6.16% over baseline methods. Moreover, our approach accelerates inner-loop optimization by 3.9x while saving 63% memory cost.
GraphCogent: Overcoming LLMs' Working Memory Constraints via Multi-Agent Collaboration in Complex Graph Understanding
Aug 17, 2025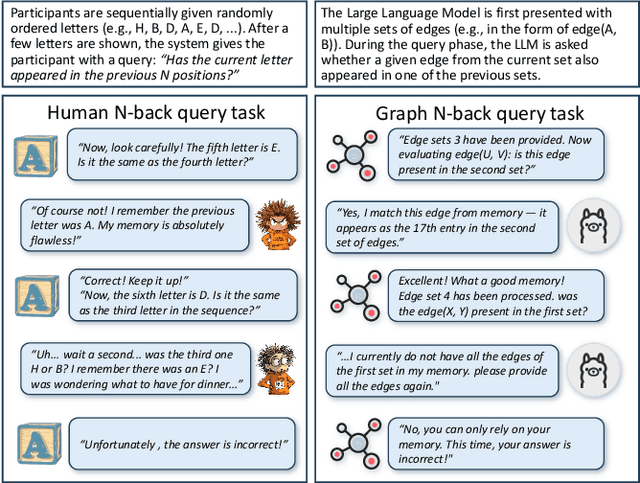
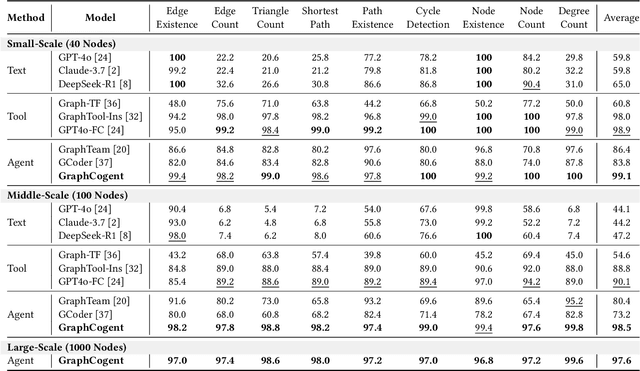
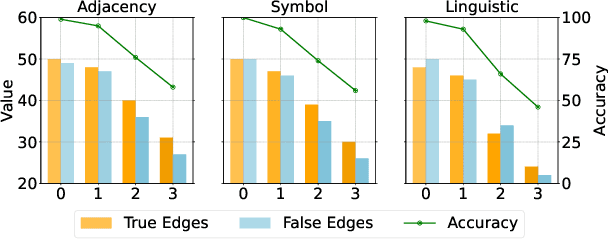

Large language models (LLMs) show promising performance on small-scale graph reasoning tasks but fail when handling real-world graphs with complex queries. This phenomenon stems from LLMs' inability to effectively process complex graph topology and perform multi-step reasoning simultaneously. To address these limitations, we propose GraphCogent, a collaborative agent framework inspired by human Working Memory Model that decomposes graph reasoning into specialized cognitive processes: sense, buffer, and execute. The framework consists of three modules: Sensory Module standardizes diverse graph text representations via subgraph sampling, Buffer Module integrates and indexes graph data across multiple formats, and Execution Module combines tool calling and model generation for efficient reasoning. We also introduce Graph4real, a comprehensive benchmark contains with four domains of real-world graphs (Web, Social, Transportation, and Citation) to evaluate LLMs' graph reasoning capabilities. Our Graph4real covers 21 different graph reasoning tasks, categorized into three types (Structural Querying, Algorithmic Reasoning, and Predictive Modeling tasks), with graph scales that are 10 times larger than existing benchmarks. Experiments show that Llama3.1-8B based GraphCogent achieves a 50% improvement over massive-scale LLMs like DeepSeek-R1 (671B). Compared to state-of-the-art agent-based baseline, our framework outperforms by 20% in accuracy while reducing token usage by 80% for in-toolset tasks and 30% for out-toolset tasks. Code will be available after review.
Adaptive Dataset Quantization
Dec 22, 2024Contemporary deep learning, characterized by the training of cumbersome neural networks on massive datasets, confronts substantial computational hurdles. To alleviate heavy data storage burdens on limited hardware resources, numerous dataset compression methods such as dataset distillation (DD) and coreset selection have emerged to obtain a compact but informative dataset through synthesis or selection for efficient training. However, DD involves an expensive optimization procedure and exhibits limited generalization across unseen architectures, while coreset selection is limited by its low data keep ratio and reliance on heuristics, hindering its practicality and feasibility. To address these limitations, we introduce a newly versatile framework for dataset compression, namely Adaptive Dataset Quantization (ADQ). Specifically, we first identify the sub-optimal performance of naive Dataset Quantization (DQ), which relies on uniform sampling and overlooks the varying importance of each generated bin. Subsequently, we propose a novel adaptive sampling strategy through the evaluation of generated bins' representativeness score, diversity score and importance score, where the former two scores are quantified by the texture level and contrastive learning-based techniques, respectively. Extensive experiments demonstrate that our method not only exhibits superior generalization capability across different architectures, but also attains state-of-the-art results, surpassing DQ by average 3\% on various datasets.
GraphTool-Instruction: Revolutionizing Graph Reasoning in LLMs through Decomposed Subtask Instruction
Dec 11, 2024



Large language models (LLMs) have been demonstrated to possess the capabilities to understand fundamental graph properties and address various graph reasoning tasks. Existing methods fine-tune LLMs to understand and execute graph reasoning tasks by specially designed task instructions. However, these Text-Instruction methods generally exhibit poor performance. Inspired by tool learning, researchers propose Tool-Instruction methods to solve various graph problems by special tool calling (e.g., function, API and model), achieving significant improvements in graph reasoning tasks. Nevertheless, current Tool-Instruction approaches focus on the tool information and ignore the graph structure information, which leads to significantly inferior performance on small-scale LLMs (less than 13B). To tackle this issue, we propose GraphTool-Instruction, an innovative Instruction-tuning approach that decomposes the graph reasoning task into three distinct subtasks (i.e., graph extraction, tool name identification and tool parameter extraction), and design specialized instructions for each subtask. Our GraphTool-Instruction can be used as a plug-and-play prompt for different LLMs without fine-tuning. Moreover, building on GraphTool-Instruction, we develop GTools, a dataset that includes twenty graph reasoning tasks, and create a graph reasoning LLM called GraphForge based on Llama3-8B. We conduct extensive experiments on twenty graph reasoning tasks with different graph types (e.g., graph size or graph direction), and we find that GraphTool-Instruction achieves SOTA compared to Text-Instruction and Tool-Instruction methods. Fine-tuned on GTools, GraphForge gets further improvement of over 30% compared to the Tool-Instruction enhanced GPT-3.5-turbo, and it performs comparably to the high-cost GPT-4o. Our codes and data are available at https://anonymous.4open.science/r/GraphTool-Instruction.