 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeatureBench: Benchmarking Agentic Coding for Complex Feature Development
Feb 11, 2026Agents powered by large language models (LLMs) are increasingly adopted in the software industry, contributing code as collaborators or even autonomous developers. As their presence grows, it becomes important to assess the current boundaries of their coding abilities. Existing agentic coding benchmarks, however, cover a limited task scope, e.g., bug fixing within a single pull request (PR), and often rely on non-executable evaluations or lack an automated approach for continually updating the evaluation coverage. To address such issues, we propose FeatureBench, a benchmark designed to evaluate agentic coding performance in end-to-end, feature-oriented software development. FeatureBench incorporates an execution-based evaluation protocol and a scalable test-driven method that automatically derives tasks from code repositories with minimal human effort. By tracing from unit tests along a dependency graph, our approach can identify feature-level coding tasks spanning multiple commits and PRs scattered across the development timeline, while ensuring the proper functioning of other features after the separation. Using this framework, we curated 200 challenging evaluation tasks and 3825 executable environments from 24 open-source repositories in the first version of our benchmark. Empirical evaluation reveals that the state-of-the-art agentic model, such as Claude 4.5 Opus, which achieves a 74.4% resolved rate on SWE-bench, succeeds on only 11.0% of tasks, opening new opportunities for advancing agentic coding. Moreover, benefiting from our automated task collection toolkit, FeatureBench can be easily scaled and updated over time to mitigate data leakage. The inherent verifiability of constructed environments also makes our method potentially valuable for agent training.
NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos
Jan 01, 2026In this paper, we propose NeoVerse, a versatile 4D world model that is capable of 4D reconstruction, novel-trajectory video generation, and rich downstream applications. We first identify a common limitation of scalability in current 4D world modeling methods, caused either by expensive and specialized multi-view 4D data or by cumbersome training pre-processing. In contrast, our NeoVerse is built upon a core philosophy that makes the full pipeline scalable to diverse in-the-wild monocular videos. Specifically, NeoVerse features pose-free feed-forward 4D reconstruction, online monocular degradation pattern simulation, and other well-aligned techniques. These designs empower NeoVerse with versatility and generalization to various domains. Meanwhile, NeoVerse achieves state-of-the-art performance in standard reconstruction and generation benchmarks. Our project page is available at https://neoverse-4d.github.io
LayerAnimate: Layer-specific Control for Animation
Jan 14, 2025



Animated video separates foreground and background elements into layers, with distinct processes for sketching, refining, coloring, and in-betweening. Existing video generation methods typically treat animation as a monolithic data domain, lacking fine-grained control over individual layers. In this paper, we introduce LayerAnimate, a novel architectural approach that enhances fine-grained control over individual animation layers within a video diffusion model, allowing users to independently manipulate foreground and background elements in distinct layers. To address the challenge of limited layer-specific data, we propose a data curation pipeline that features automated element segmentation, motion-state hierarchical merging, and motion coherence refinement. Through quantitative and qualitative comparisons, and user study, we demonstrate that LayerAnimate outperforms current methods in terms of animation quality, control precision, and usability, making it an ideal tool for both professional animators and amateur enthusiasts. This framework opens up new possibilities for layer-specific animation applications and creative flexibility. Our code is available at https://layeranimate.github.io.
Trim 3D Gaussian Splatting for Accurate Geometry Representation
Jun 11, 2024In this paper, we introduce Trim 3D Gaussian Splatting (TrimGS) to reconstruct accurate 3D geometry from images. Previous arts for geometry reconstruction from 3D Gaussians mainly focus on exploring strong geometry regularization. Instead, from a fresh perspective, we propose to obtain accurate 3D geometry of a scene by Gaussian trimming, which selectively removes the inaccurate geometry while preserving accurate structures. To achieve this, we analyze the contributions of individual 3D Gaussians and propose a contribution-based trimming strategy to remove the redundant or inaccurate Gaussians. Furthermore, our experimental and theoretical analyses reveal that a relatively small Gaussian scale is a non-negligible factor in representing and optimizing the intricate details. Therefore the proposed TrimGS maintains relatively small Gaussian scales. In addition, TrimGS is also compatible with the effective geometry regularization strategies in previous arts. When combined with the original 3DGS and the state-of-the-art 2DGS, TrimGS consistently yields more accurate geometry and higher perceptual quality. Our project page is https://trimgs.github.io
MixSup: Mixed-grained Supervision for Label-efficient LiDAR-based 3D Object Detection
Jan 29, 2024Label-efficient LiDAR-based 3D object detection is currently dominated by weakly/semi-supervised methods. Instead of exclusively following one of them, we propose MixSup, a more practical paradigm simultaneously utilizing massive cheap coarse labels and a limited number of accurate labels for Mixed-grained Supervision. We start by observing that point clouds are usually textureless, making it hard to learn semantics. However, point clouds are geometrically rich and scale-invariant to the distances from sensors, making it relatively easy to learn the geometry of objects, such as poses and shapes. Thus, MixSup leverages massive coarse cluster-level labels to learn semantics and a few expensive box-level labels to learn accurate poses and shapes. We redesign the label assignment in mainstream detectors, which allows them seamlessly integrated into MixSup, enabling practicality and universality. We validate its effectiveness in nuScenes, Waymo Open Dataset, and KITTI, employing various detectors. MixSup achieves up to 97.31% of fully supervised performance, using cheap cluster annotations and only 10% box annotations. Furthermore, we propose PointSAM based on the Segment Anything Model for automated coarse labeling, further reducing the annotation burden. The code is available at https://github.com/BraveGroup/PointSAM-for-MixSup.
Once Detected, Never Lost: Surpassing Human Performance in Offline LiDAR based 3D Object Detection
Apr 24, 2023



This paper aims for high-performance offline LiDAR-based 3D object detection. We first observe that experienced human annotators annotate objects from a track-centric perspective. They first label the objects with clear shapes in a track, and then leverage the temporal coherence to infer the annotations of obscure objects. Drawing inspiration from this, we propose a high-performance offline detector in a track-centric perspective instead of the conventional object-centric perspective. Our method features a bidirectional tracking module and a track-centric learning module. Such a design allows our detector to infer and refine a complete track once the object is detected at a certain moment. We refer to this characteristic as "onCe detecTed, neveR Lost" and name the proposed system CTRL. Extensive experiments demonstrate the remarkable performance of our method, surpassing the human-level annotating accuracy and the previous state-of-the-art methods in the highly competitive Waymo Open Dataset without model ensemble. The code will be made publicly available at https://github.com/tusen-ai/SST.
Super Sparse 3D Object Detection
Jan 05, 2023As the perception range of LiDAR expands, LiDAR-based 3D object detection contributes ever-increasingly to the long-range perception in autonomous driving. Mainstream 3D object detectors often build dense feature maps, where the cost is quadratic to the perception range, making them hardly scale up to the long-range settings. To enable efficient long-range detection, we first propose a fully sparse object detector termed FSD. FSD is built upon the general sparse voxel encoder and a novel sparse instance recognition (SIR) module. SIR groups the points into instances and applies highly-efficient instance-wise feature extraction. The instance-wise grouping sidesteps the issue of the center feature missing, which hinders the design of the fully sparse architecture. To further enjoy the benefit of fully sparse characteristic, we leverage temporal information to remove data redundancy and propose a super sparse detector named FSD++. FSD++ first generates residual points, which indicate the point changes between consecutive frames. The residual points, along with a few previous foreground points, form the super sparse input data, greatly reducing data redundancy and computational overhead. We comprehensively analyze our method on the large-scale Waymo Open Dataset, and state-of-the-art performance is reported. To showcase the superiority of our method in long-range detection, we also conduct experiments on Argoverse 2 Dataset, where the perception range ($200m$) is much larger than Waymo Open Dataset ($75m$). Code is open-sourced at https://github.com/tusen-ai/SST.
QuatDE: Dynamic Quaternion Embedding for Knowledge Graph Completion
May 19, 2021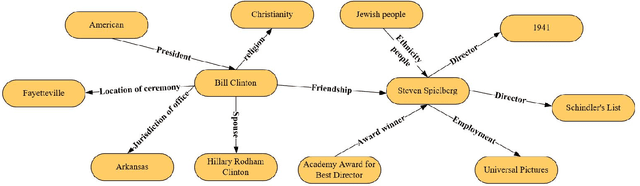
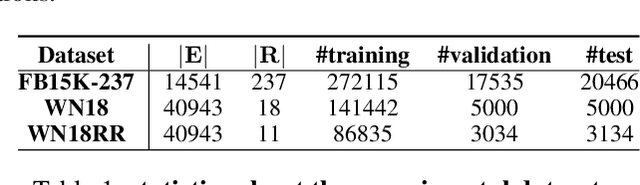
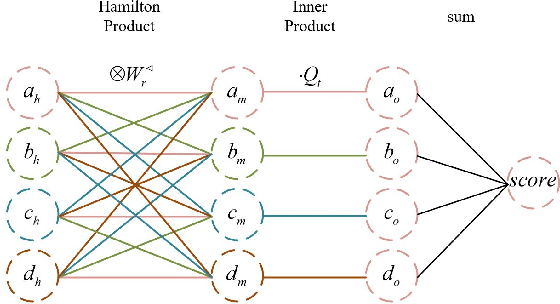
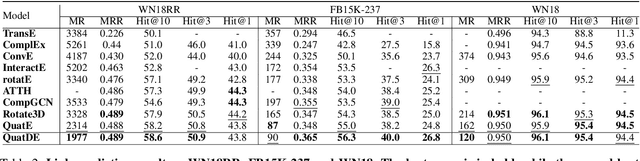
In recent years, knowledge graph completion methods have been extensively studied, in which graph embedding approaches learn low dimensional representations of entities and relations to predict missing facts. Those models usually view the relation vector as a translation (TransE) or rotation (rotatE and QuatE) between entity pairs, enjoying the advantage of simplicity and efficiency. However, QuatE has two main problems: 1) The model to capture the ability of representation and feature interaction between entities and relations are relatively weak because it only relies on the rigorous calculation of three embedding vectors; 2) Although the model can handle various relation patterns including symmetry, anti-symmetry, inversion and composition, but mapping properties of relations are not to be considered, such as one-to-many, many-to-one, and many-to-many. In this paper, we propose a novel model, QuatDE, with a dynamic mapping strategy to explicitly capture a variety of relational patterns, enhancing the feature interaction capability between elements of the triplet. Our model relies on three extra vectors donated as subject transfer vector, object transfer vector and relation transfer vector. The mapping strategy dynamically selects the transition vectors associated with each triplet, used to adjust the point position of the entity embedding vectors in the quaternion space via Hamilton product. Experiment results show QuatDE achieves state-of-the-art performance on three well-established knowledge graph completion benchmarks. In particular, the MR evaluation has relatively increased by 26% on WN18 and 15% on WN18RR, which proves the generalization of QuatDE.