 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQA and Visual Reasoning: An Overview of Recent Datasets, Methods and Challenges
Dec 26, 2022

Artificial Intelligence (AI) and its applications have sparked extraordinary interest in recent years. This achievement can be ascribed in part to advances in AI subfields including Machine Learning (ML), Computer Vision (CV), and Natural Language Processing (NLP). Deep learning, a sub-field of machine learning that employs artificial neural network concepts, has enabled the most rapid growth in these domains. The integration of vision and language has sparked a lot of attention as a result of this. The tasks have been created in such a way that they properly exemplify the concepts of deep learning. In this review paper, we provide a thorough and an extensive review of the state of the arts approaches, key models design principles and discuss existing datasets, methods, their problem formulation and evaluation measures for VQA and Visual reasoning tasks to understand vision and language representation learning. We also present some potential future paths in this field of research, with the hope that our study may generate new ideas and novel approaches to handle existing difficulties and develop new applications.
QuatDE: Dynamic Quaternion Embedding for Knowledge Graph Completion
May 19, 2021
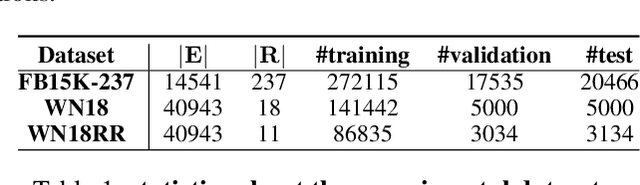
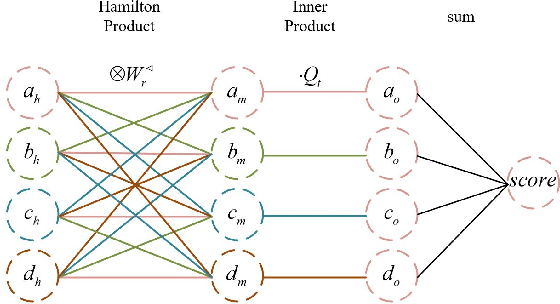
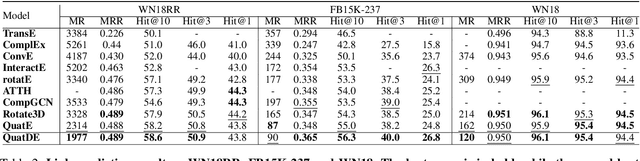
In recent years, knowledge graph completion methods have been extensively studied, in which graph embedding approaches learn low dimensional representations of entities and relations to predict missing facts. Those models usually view the relation vector as a translation (TransE) or rotation (rotatE and QuatE) between entity pairs, enjoying the advantage of simplicity and efficiency. However, QuatE has two main problems: 1) The model to capture the ability of representation and feature interaction between entities and relations are relatively weak because it only relies on the rigorous calculation of three embedding vectors; 2) Although the model can handle various relation patterns including symmetry, anti-symmetry, inversion and composition, but mapping properties of relations are not to be considered, such as one-to-many, many-to-one, and many-to-many. In this paper, we propose a novel model, QuatDE, with a dynamic mapping strategy to explicitly capture a variety of relational patterns, enhancing the feature interaction capability between elements of the triplet. Our model relies on three extra vectors donated as subject transfer vector, object transfer vector and relation transfer vector. The mapping strategy dynamically selects the transition vectors associated with each triplet, used to adjust the point position of the entity embedding vectors in the quaternion space via Hamilton product. Experiment results show QuatDE achieves state-of-the-art performance on three well-established knowledge graph completion benchmarks. In particular, the MR evaluation has relatively increased by 26% on WN18 and 15% on WN18RR, which proves the generalization of QuatDE.
Deep Neural Network Based Relation Extraction: An Overview
Feb 07, 2021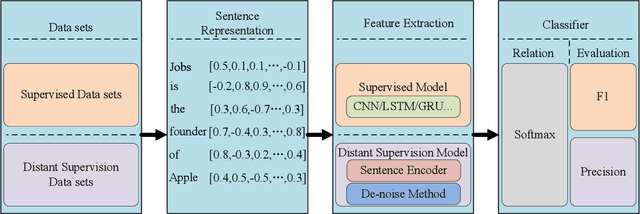
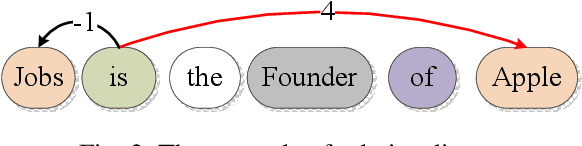
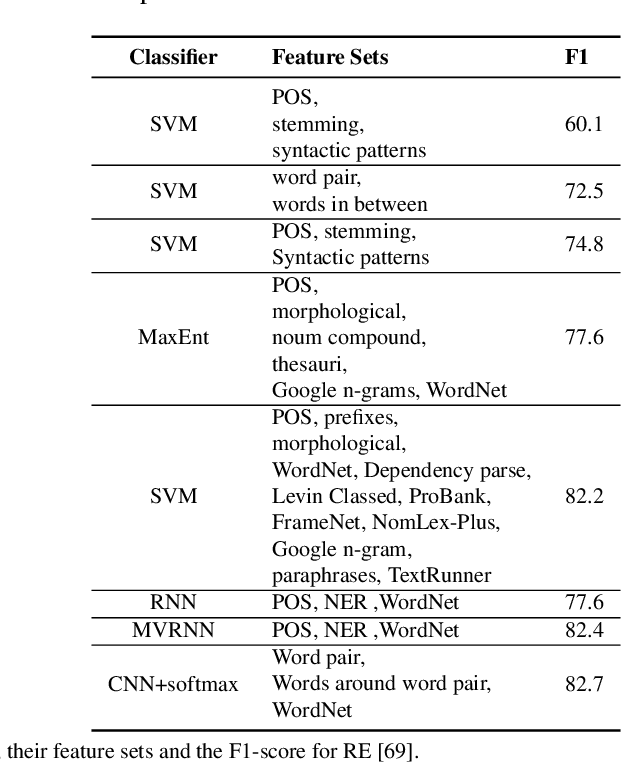
Knowledge is a formal way of understanding the world, providing a human-level cognition and intelligence for the next-generation artificial intelligence (AI). One of the representations of knowledge is semantic relations between entities. An effective way to automatically acquire this important knowledge, called Relation Extraction (RE), a sub-task of information extraction, plays a vital role in Natural Language Processing (NLP). Its purpose is to identify semantic relations between entities from natural language text. To date, there are several studies for RE in previous works, which have documented these techniques based on Deep Neural Networks (DNNs) become a prevailing technique in this research. Especially, the supervised and distant supervision methods based on DNNs are the most popular and reliable solutions for RE. This article 1) introduces some general concepts, and further 2) gives a comprehensive overview of DNNs in RE from two points of view: supervised RE, which attempts to improve the standard RE systems, and distant supervision RE, which adopts DNNs to design sentence encoder and de-noise method. We further 3) cover some novel methods and recent trends as well as discuss possible future research directions for this task.