 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph Embedding with Electronic Health Records Data via Latent Graphical Block Model
May 31, 2023Due to the increasing adoption of electronic health records (EHR), large scale EHRs have become another rich data source for translational clinical research. Despite its potential, deriving generalizable knowledge from EHR data remains challenging. First, EHR data are generated as part of clinical care with data elements too detailed and fragmented for research. Despite recent progress in mapping EHR data to common ontology with hierarchical structures, much development is still needed to enable automatic grouping of local EHR codes to meaningful clinical concepts at a large scale. Second, the total number of unique EHR features is large, imposing methodological challenges to derive reproducible knowledge graph, especially when interest lies in conditional dependency structure. Third, the detailed EHR data on a very large patient cohort imposes additional computational challenge to deriving a knowledge network. To overcome these challenges, we propose to infer the conditional dependency structure among EHR features via a latent graphical block model (LGBM). The LGBM has a two layer structure with the first providing semantic embedding vector (SEV) representation for the EHR features and the second overlaying a graphical block model on the latent SEVs. The block structures on the graphical model also allows us to cluster synonymous features in EHR. We propose to learn the LGBM efficiently, in both statistical and computational sense, based on the empirical point mutual information matrix. We establish the statistical rates of the proposed estimators and show the perfect recovery of the block structure. Numerical results from simulation studies and real EHR data analyses suggest that the proposed LGBM estimator performs well in finite sample.
Deep Neural Network Based Relation Extraction: An Overview
Feb 07, 2021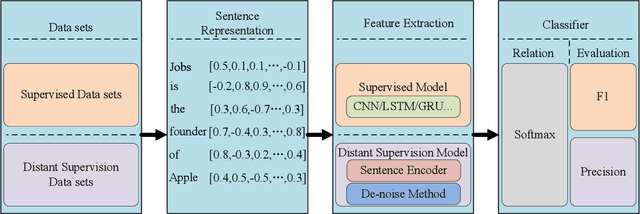
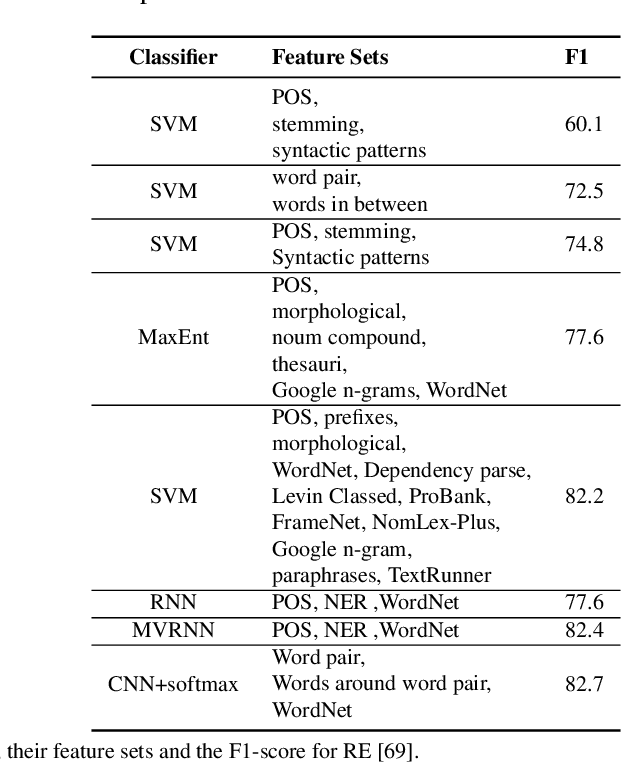
Knowledge is a formal way of understanding the world, providing a human-level cognition and intelligence for the next-generation artificial intelligence (AI). One of the representations of knowledge is semantic relations between entities. An effective way to automatically acquire this important knowledge, called Relation Extraction (RE), a sub-task of information extraction, plays a vital role in Natural Language Processing (NLP). Its purpose is to identify semantic relations between entities from natural language text. To date, there are several studies for RE in previous works, which have documented these techniques based on Deep Neural Networks (DNNs) become a prevailing technique in this research. Especially, the supervised and distant supervision methods based on DNNs are the most popular and reliable solutions for RE. This article 1) introduces some general concepts, and further 2) gives a comprehensive overview of DNNs in RE from two points of view: supervised RE, which attempts to improve the standard RE systems, and distant supervision RE, which adopts DNNs to design sentence encoder and de-noise method. We further 3) cover some novel methods and recent trends as well as discuss possible future research directions for this task.