 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Distillation via Relative Distribution Matching and Cognitive Heritage
Feb 05, 2026Dataset distillation seeks to synthesize a highly compact dataset that achieves performance comparable to the original dataset on downstream tasks. For the classification task that use pre-trained self-supervised models as backbones, previous linear gradient matching optimizes synthetic images by encouraging them to mimic the gradient updates induced by real images on the linear classifier. However, this batch-level formulation requires loading thousands of real images and applying multiple rounds of differentiable augmentations to synthetic images at each distillation step, leading to substantial computational and memory overhead. In this paper, we introduce statistical flow matching , a stable and efficient supervised learning framework that optimizes synthetic images by aligning constant statistical flows from target class centers to non-target class centers in the original data. Our approach loads raw statistics only once and performs a single augmentation pass on the synthetic data, achieving performance comparable to or better than the state-of-the-art methods with 10x lower GPU memory usage and 4x shorter runtime. Furthermore, we propose a classifier inheritance strategy that reuses the classifier trained on the original dataset for inference, requiring only an extremely lightweight linear projector and marginal storage while achieving substantial performance gains.
EDITS: Enhancing Dataset Distillation with Implicit Textual Semantics
Sep 17, 2025Dataset distillation aims to synthesize a compact dataset from the original large-scale one, enabling highly efficient learning while preserving competitive model performance. However, traditional techniques primarily capture low-level visual features, neglecting the high-level semantic and structural information inherent in images. In this paper, we propose EDITS, a novel framework that exploits the implicit textual semantics within the image data to achieve enhanced distillation. First, external texts generated by a Vision Language Model (VLM) are fused with image features through a Global Semantic Query module, forming the prior clustered buffer. Local Semantic Awareness then selects representative samples from the buffer to construct image and text prototypes, with the latter produced by guiding a Large Language Model (LLM) with meticulously crafted prompt. Ultimately, Dual Prototype Guidance strategy generates the final synthetic dataset through a diffusion model. Extensive experiments confirm the effectiveness of our method.Source code is available in: https://github.com/einsteinxia/EDITS.
One Prompt to Verify Your Models: Black-Box Text-to-Image Models Verification via Non-Transferable Adversarial Attacks
Oct 31, 2024



Recently, the success of Text-to-Image (T2I) models has led to the rise of numerous third-party platforms, which claim to provide cheaper API services and more flexibility in model options. However, this also raises a new security concern: Are these third-party services truly offering the models they claim? To address this problem, we propose the first T2I model verification method named Text-to-Image Model Verification via Non-Transferable Adversarial Attacks (TVN). The non-transferability of adversarial examples means that these examples are only effective on a target model and ineffective on other models, thereby allowing for the verification of the target model. TVN utilizes the Non-dominated Sorting Genetic Algorithm II (NSGA-II) to optimize the cosine similarity of a prompt's text encoding, generating non-transferable adversarial prompts. By calculating the CLIP-text scores between the non-transferable adversarial prompts without perturbations and the images, we can verify if the model matches the claimed target model, based on a 3-sigma threshold. The experiments showed that TVN performed well in both closed-set and open-set scenarios, achieving a verification accuracy of over 90\%. Moreover, the adversarial prompts generated by TVN significantly reduced the CLIP-text scores of the target model, while having little effect on other models.
Backdoor Attack Against Vision Transformers via Attention Gradient-Based Image Erosion
Oct 30, 2024Vision Transformers (ViTs) have outperformed traditional Convolutional Neural Networks (CNN) across various computer vision tasks. However, akin to CNN, ViTs are vulnerable to backdoor attacks, where the adversary embeds the backdoor into the victim model, causing it to make wrong predictions about testing samples containing a specific trigger. Existing backdoor attacks against ViTs have the limitation of failing to strike an optimal balance between attack stealthiness and attack effectiveness. In this work, we propose an Attention Gradient-based Erosion Backdoor (AGEB) targeted at ViTs. Considering the attention mechanism of ViTs, AGEB selectively erodes pixels in areas of maximal attention gradient, embedding a covert backdoor trigger. Unlike previous backdoor attacks against ViTs, AGEB achieves an optimal balance between attack stealthiness and attack effectiveness, ensuring the trigger remains invisible to human detection while preserving the model's accuracy on clean samples. Extensive experimental evaluations across various ViT architectures and datasets confirm the effectiveness of AGEB, achieving a remarkable Attack Success Rate (ASR) without diminishing Clean Data Accuracy (CDA). Furthermore, the stealthiness of AGEB is rigorously validated, demonstrating minimal visual discrepancies between the clean and the triggered images.
Deep Neural Network Based Relation Extraction: An Overview
Feb 07, 2021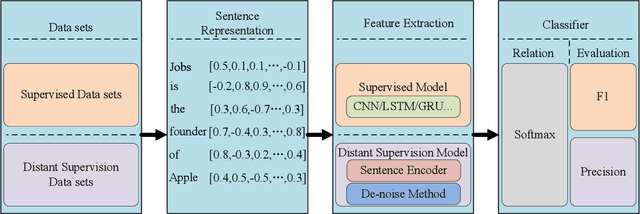
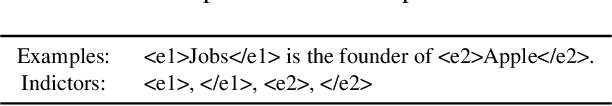
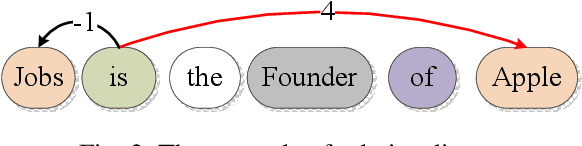
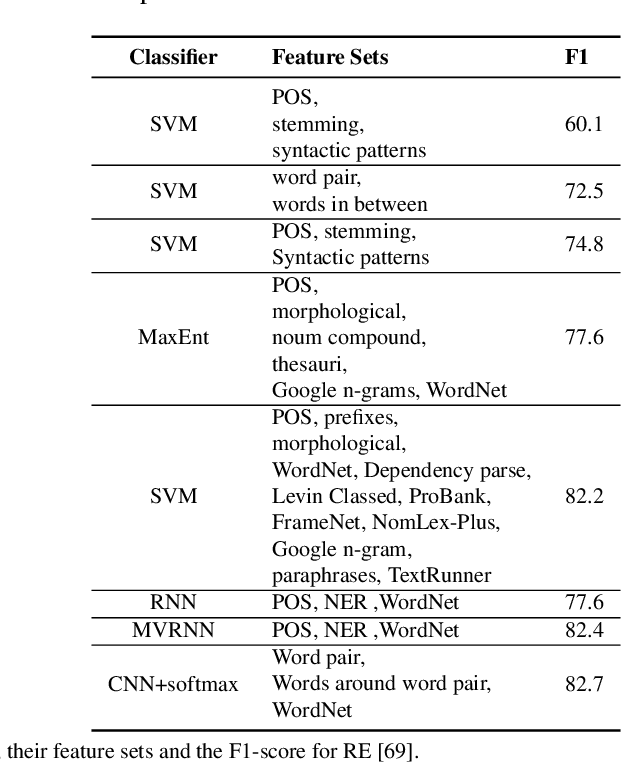
Knowledge is a formal way of understanding the world, providing a human-level cognition and intelligence for the next-generation artificial intelligence (AI). One of the representations of knowledge is semantic relations between entities. An effective way to automatically acquire this important knowledge, called Relation Extraction (RE), a sub-task of information extraction, plays a vital role in Natural Language Processing (NLP). Its purpose is to identify semantic relations between entities from natural language text. To date, there are several studies for RE in previous works, which have documented these techniques based on Deep Neural Networks (DNNs) become a prevailing technique in this research. Especially, the supervised and distant supervision methods based on DNNs are the most popular and reliable solutions for RE. This article 1) introduces some general concepts, and further 2) gives a comprehensive overview of DNNs in RE from two points of view: supervised RE, which attempts to improve the standard RE systems, and distant supervision RE, which adopts DNNs to design sentence encoder and de-noise method. We further 3) cover some novel methods and recent trends as well as discuss possible future research directions for this task.