 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQA and Visual Reasoning: An Overview of Recent Datasets, Methods and Challenges
Dec 26, 2022
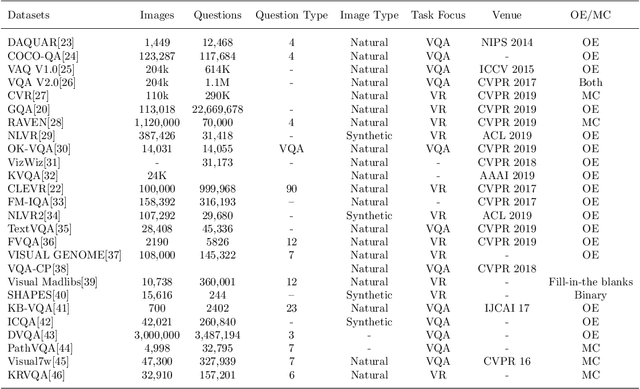
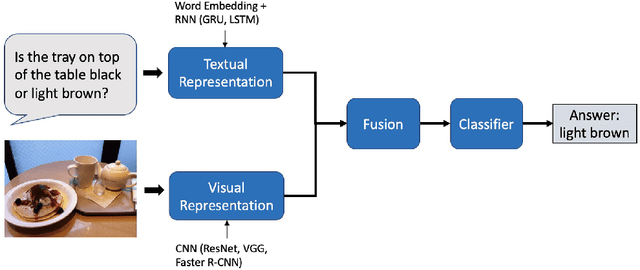

Artificial Intelligence (AI) and its applications have sparked extraordinary interest in recent years. This achievement can be ascribed in part to advances in AI subfields including Machine Learning (ML), Computer Vision (CV), and Natural Language Processing (NLP). Deep learning, a sub-field of machine learning that employs artificial neural network concepts, has enabled the most rapid growth in these domains. The integration of vision and language has sparked a lot of attention as a result of this. The tasks have been created in such a way that they properly exemplify the concepts of deep learning. In this review paper, we provide a thorough and an extensive review of the state of the arts approaches, key models design principles and discuss existing datasets, methods, their problem formulation and evaluation measures for VQA and Visual reasoning tasks to understand vision and language representation learning. We also present some potential future paths in this field of research, with the hope that our study may generate new ideas and novel approaches to handle existing difficulties and develop new applications.