 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Random: Automatic Inner-loop Optimization in Dataset Distillation
Oct 06, 2025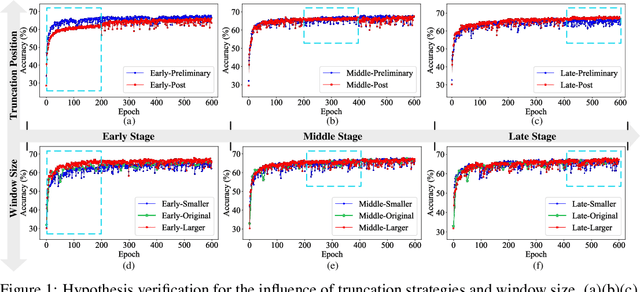
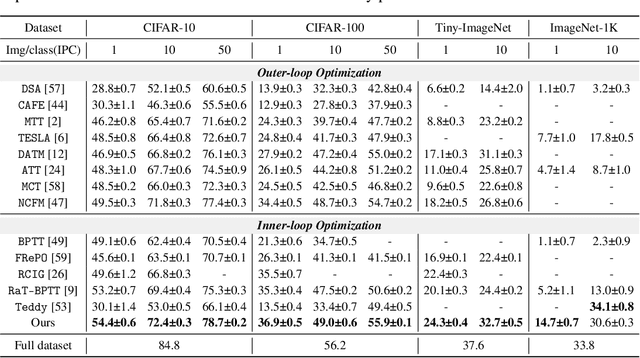
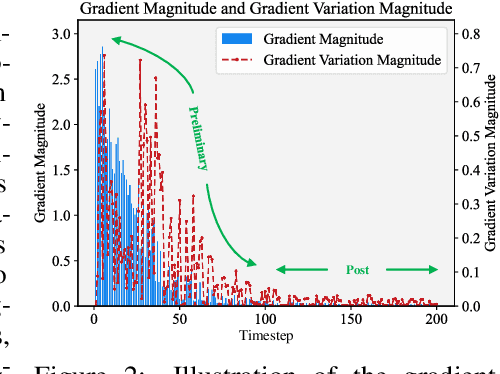
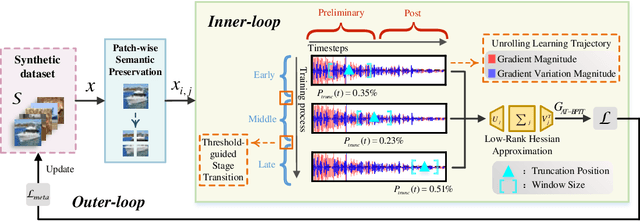
The growing demand for efficient deep learning has positioned dataset distillation as a pivotal technique for compressing training dataset while preserving model performance. However, existing inner-loop optimization methods for dataset distillation typically rely on random truncation strategies, which lack flexibility and often yield suboptimal results. In this work, we observe that neural networks exhibit distinct learning dynamics across different training stages-early, middle, and late-making random truncation ineffective. To address this limitation, we propose Automatic Truncated Backpropagation Through Time (AT-BPTT), a novel framework that dynamically adapts both truncation positions and window sizes according to intrinsic gradient behavior. AT-BPTT introduces three key components: (1) a probabilistic mechanism for stage-aware timestep selection, (2) an adaptive window sizing strategy based on gradient variation, and (3) a low-rank Hessian approximation to reduce computational overhead. Extensive experiments on CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet-1K show that AT-BPTT achieves state-of-the-art performance, improving accuracy by an average of 6.16% over baseline methods. Moreover, our approach accelerates inner-loop optimization by 3.9x while saving 63% memory cost.
GraphCogent: Overcoming LLMs' Working Memory Constraints via Multi-Agent Collaboration in Complex Graph Understanding
Aug 17, 2025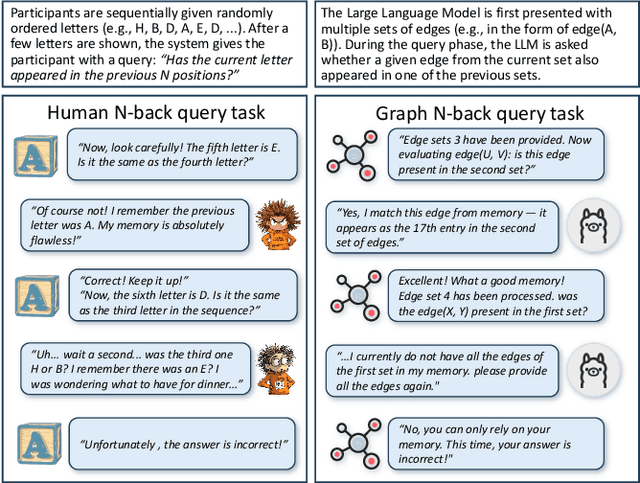
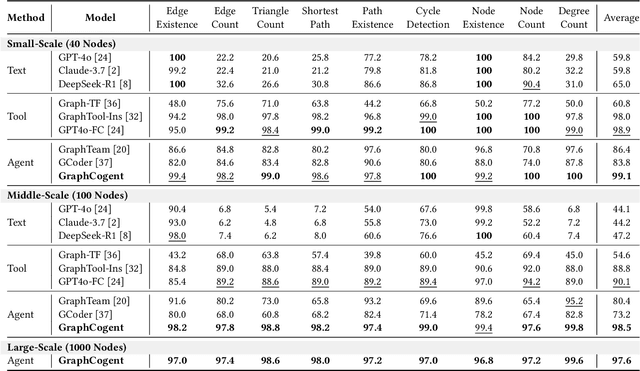
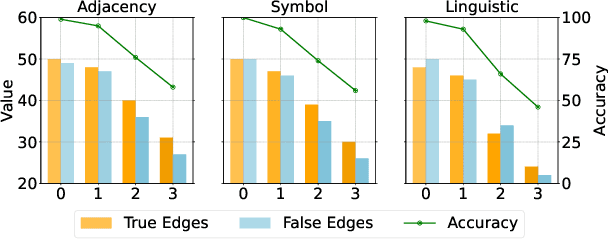

Large language models (LLMs) show promising performance on small-scale graph reasoning tasks but fail when handling real-world graphs with complex queries. This phenomenon stems from LLMs' inability to effectively process complex graph topology and perform multi-step reasoning simultaneously. To address these limitations, we propose GraphCogent, a collaborative agent framework inspired by human Working Memory Model that decomposes graph reasoning into specialized cognitive processes: sense, buffer, and execute. The framework consists of three modules: Sensory Module standardizes diverse graph text representations via subgraph sampling, Buffer Module integrates and indexes graph data across multiple formats, and Execution Module combines tool calling and model generation for efficient reasoning. We also introduce Graph4real, a comprehensive benchmark contains with four domains of real-world graphs (Web, Social, Transportation, and Citation) to evaluate LLMs' graph reasoning capabilities. Our Graph4real covers 21 different graph reasoning tasks, categorized into three types (Structural Querying, Algorithmic Reasoning, and Predictive Modeling tasks), with graph scales that are 10 times larger than existing benchmarks. Experiments show that Llama3.1-8B based GraphCogent achieves a 50% improvement over massive-scale LLMs like DeepSeek-R1 (671B). Compared to state-of-the-art agent-based baseline, our framework outperforms by 20% in accuracy while reducing token usage by 80% for in-toolset tasks and 30% for out-toolset tasks. Code will be available after review.
Adaptive Dataset Quantization
Dec 22, 2024Contemporary deep learning, characterized by the training of cumbersome neural networks on massive datasets, confronts substantial computational hurdles. To alleviate heavy data storage burdens on limited hardware resources, numerous dataset compression methods such as dataset distillation (DD) and coreset selection have emerged to obtain a compact but informative dataset through synthesis or selection for efficient training. However, DD involves an expensive optimization procedure and exhibits limited generalization across unseen architectures, while coreset selection is limited by its low data keep ratio and reliance on heuristics, hindering its practicality and feasibility. To address these limitations, we introduce a newly versatile framework for dataset compression, namely Adaptive Dataset Quantization (ADQ). Specifically, we first identify the sub-optimal performance of naive Dataset Quantization (DQ), which relies on uniform sampling and overlooks the varying importance of each generated bin. Subsequently, we propose a novel adaptive sampling strategy through the evaluation of generated bins' representativeness score, diversity score and importance score, where the former two scores are quantified by the texture level and contrastive learning-based techniques, respectively. Extensive experiments demonstrate that our method not only exhibits superior generalization capability across different architectures, but also attains state-of-the-art results, surpassing DQ by average 3\% on various datasets.
Towards Effective Data-Free Knowledge Distillation via Diverse Diffusion Augmentation
Oct 23, 2024Data-free knowledge distillation (DFKD) has emerged as a pivotal technique in the domain of model compression, substantially reducing the dependency on the original training data. Nonetheless, conventional DFKD methods that employ synthesized training data are prone to the limitations of inadequate diversity and discrepancies in distribution between the synthesized and original datasets. To address these challenges, this paper introduces an innovative approach to DFKD through diverse diffusion augmentation (DDA). Specifically, we revise the paradigm of common data synthesis in DFKD to a composite process through leveraging diffusion models subsequent to data synthesis for self-supervised augmentation, which generates a spectrum of data samples with similar distributions while retaining controlled variations. Furthermore, to mitigate excessive deviation in the embedding space, we introduce an image filtering technique grounded in cosine similarity to maintain fidelity during the knowledge distillation process. Comprehensive experiments conducted on CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets showcase the superior performance of our method across various teacher-student network configurations, outperforming the contemporary state-of-the-art DFKD methods. Code will be available at:https://github.com/SLGSP/DDA.