 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Dataset Quantization
Dec 22, 2024Contemporary deep learning, characterized by the training of cumbersome neural networks on massive datasets, confronts substantial computational hurdles. To alleviate heavy data storage burdens on limited hardware resources, numerous dataset compression methods such as dataset distillation (DD) and coreset selection have emerged to obtain a compact but informative dataset through synthesis or selection for efficient training. However, DD involves an expensive optimization procedure and exhibits limited generalization across unseen architectures, while coreset selection is limited by its low data keep ratio and reliance on heuristics, hindering its practicality and feasibility. To address these limitations, we introduce a newly versatile framework for dataset compression, namely Adaptive Dataset Quantization (ADQ). Specifically, we first identify the sub-optimal performance of naive Dataset Quantization (DQ), which relies on uniform sampling and overlooks the varying importance of each generated bin. Subsequently, we propose a novel adaptive sampling strategy through the evaluation of generated bins' representativeness score, diversity score and importance score, where the former two scores are quantified by the texture level and contrastive learning-based techniques, respectively. Extensive experiments demonstrate that our method not only exhibits superior generalization capability across different architectures, but also attains state-of-the-art results, surpassing DQ by average 3\% on various datasets.
Automatic Ischemic Stroke Lesion Segmentation from Computed Tomography Perfusion Images by Image Synthesis and Attention-Based Deep Neural Networks
Jul 07, 2020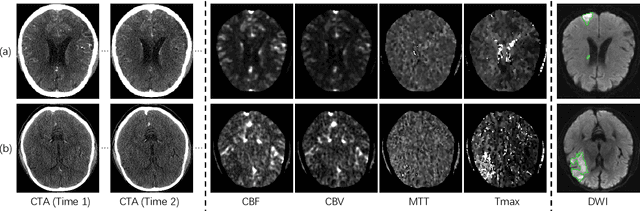
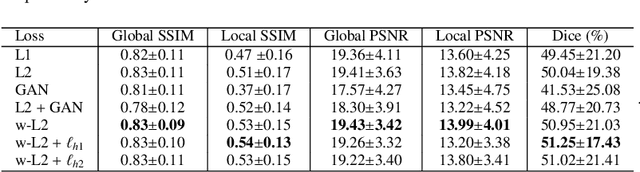
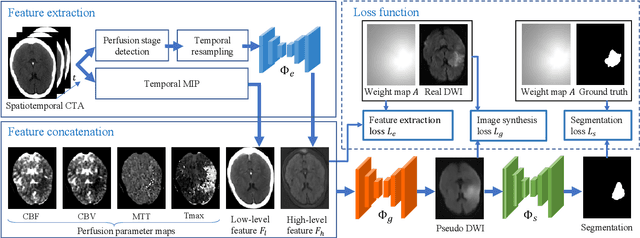
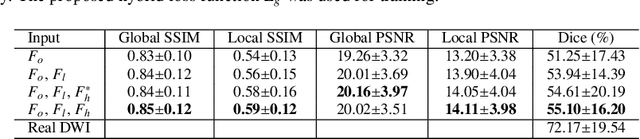
Ischemic stroke lesion segmentation from Computed Tomography Perfusion (CTP) images is important for accurate diagnosis of stroke in acute care units. However, it is challenged by low image contrast and resolution of the perfusion parameter maps, in addition to the complex appearance of the lesion. To deal with this problem, we propose a novel framework based on synthesized pseudo Diffusion-Weighted Imaging (DWI) from perfusion parameter maps to obtain better image quality for more accurate segmentation. Our framework consists of three components based on Convolutional Neural Networks (CNNs) and is trained end-to-end. First, a feature extractor is used to obtain both a low-level and high-level compact representation of the raw spatiotemporal Computed Tomography Angiography (CTA) images. Second, a pseudo DWI generator takes as input the concatenation of CTP perfusion parameter maps and our extracted features to obtain the synthesized pseudo DWI. To achieve better synthesis quality, we propose a hybrid loss function that pays more attention to lesion regions and encourages high-level contextual consistency. Finally, we segment the lesion region from the synthesized pseudo DWI, where the segmentation network is based on switchable normalization and channel calibration for better performance. Experimental results showed that our framework achieved the top performance on ISLES 2018 challenge and: 1) our method using synthesized pseudo DWI outperformed methods segmenting the lesion from perfusion parameter maps directly; 2) the feature extractor exploiting additional spatiotemporal CTA images led to better synthesized pseudo DWI quality and higher segmentation accuracy; and 3) the proposed loss functions and network structure improved the pseudo DWI synthesis and lesion segmentation performance.
OpenHowNet: An Open Sememe-based Lexical Knowledge Base
Jan 28, 2019
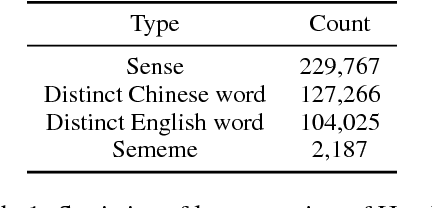

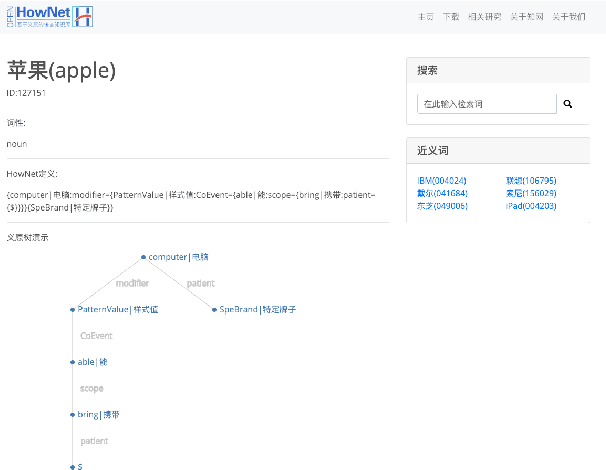
In this paper, we present an open sememe-based lexical knowledge base OpenHowNet. Based on well-known HowNet, OpenHowNet comprises three components: core data which is composed of more than 100 thousand senses annotated with sememes, OpenHowNet Web which gives a brief introduction to OpenHowNet as well as provides online exhibition of OpenHowNet information, and OpenHowNet API which includes several useful APIs such as accessing OpenHowNet core data and drawing sememe tree structures of senses. In the main text, we first give some backgrounds including definition of sememe and details of HowNet. And then we introduce some previous HowNet and sememe-based research works. Last but not least, we detail the constituents of OpenHowNet and their basic features and functionalities. Additionally, we briefly make a summary and list some future works.
Resource Mention Extraction for MOOC Discussion Forums
Nov 21, 2018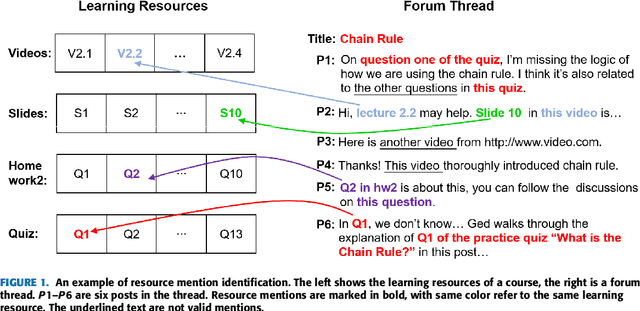
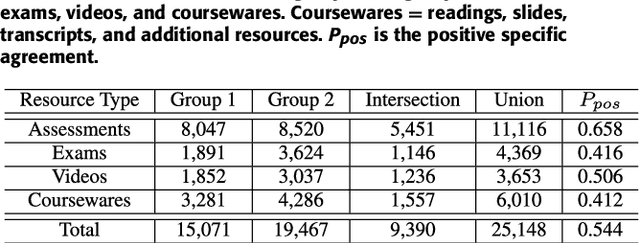

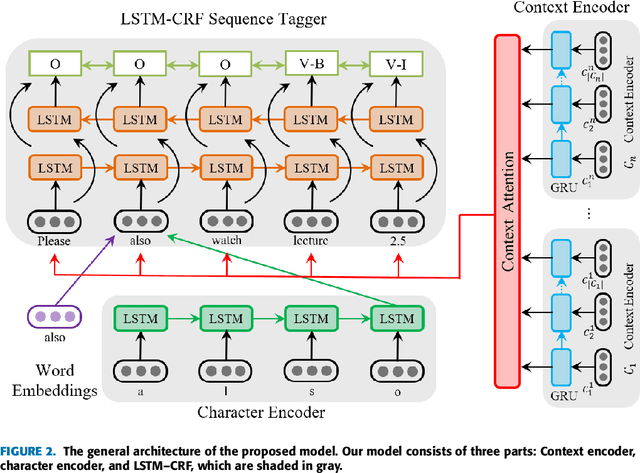
In discussions hosted on discussion forums for MOOCs, references to online learning resources are often of central importance. They contextualize the discussion, anchoring the discussion participants' presentation of the issues and their understanding. However they are usually mentioned in free text, without appropriate hyperlinking to their associated resource. Automated learning resource mention hyperlinking and categorization will facilitate discussion and searching within MOOC forums, and also benefit the contextualization of such resources across disparate views. We propose the novel problem of learning resource mention identification in MOOC forums. As this is a novel task with no publicly available data, we first contribute a large-scale labeled dataset, dubbed the Forum Resource Mention (FoRM) dataset, to facilitate our current research and future research on this task. We then formulate this task as a sequence tagging problem and investigate solution architectures to address the problem. Importantly, we identify two major challenges that hinder the application of sequence tagging models to the task: (1) the diversity of resource mention expression, and (2) long-range contextual dependencies. We address these challenges by incorporating character-level and thread context information into a LSTM-CRF model. First, we incorporate a character encoder to address the out-of-vocabulary problem caused by the diversity of mention expressions. Second, to address the context dependency challenge, we encode thread contexts using an RNN-based context encoder, and apply the attention mechanism to selectively leverage useful context information during sequence tagging. Experiments on FoRM show that the proposed method improves the baseline deep sequence tagging models notably, significantly bettering performance on instances that exemplify the two challenges.