 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKEPo: Knowledge Evolution Poison on Graph-based Retrieval-Augmented Generation
Mar 12, 2026Graph-based Retrieval-Augmented Generation (GraphRAG) constructs the Knowledge Graph (KG) from external databases to enhance the timeliness and accuracy of Large Language Model (LLM) generations.However,this reliance on external data introduces new attack surfaces.Attackers can inject poisoned texts into databases to manipulate LLMs into producing harmful target responses for attacker-chosen queries.Existing research primarily focuses on attacking conventional RAG systems.However,such methods are ineffective against GraphRAG.This robustness derives from the KG abstraction of GraphRAG,which reorganizes injected text into a graph before retrieval,thereby enabling the LLM to reason based on the restructured context instead of raw poisoned passages.To expose latent security vulnerabilities in GraphRAG,we propose Knowledge Evolution Poison (KEPo),a novel poisoning attack method specifically designed for GraphRAG.For each target query,KEPo first generates a toxic event containing poisoned knowledge based on the target answer.By fabricating event backgrounds and forging knowledge evolution paths from original facts to the toxic event,it then poisons the KG and misleads the LLM into treating the poisoned knowledge as the final result.In multi-target attack scenarios,KEPo further connects multiple attack corpora,enabling their poisoned knowledge to mutually reinforce while expanding the scale of poisoned communities,thereby amplifying attack effectiveness.Experimental results across multiple datasets demonstrate that KEPo achieves state-of-the-art attack success rates for both single-target and multi-target attacks,significantly outperforming previous methods.
AlignVAR: Towards Globally Consistent Visual Autoregression for Image Super-Resolution
Mar 05, 2026Visual autoregressive (VAR) models have recently emerged as a promising alternative for image generation, offering stable training, non-iterative inference, and high-fidelity synthesis through next-scale prediction. This encourages the exploration of VAR for image super-resolution (ISR), yet its application remains underexplored and faces two critical challenges: locality-biased attention, which fragments spatial structures, and residual-only supervision, which accumulates errors across scales, severely compromises global consistency of reconstructed images. To address these issues, we propose AlignVAR, a globally consistent visual autoregressive framework tailored for ISR, featuring two key components: (1) Spatial Consistency Autoregression (SCA), which applies an adaptive mask to reweight attention toward structurally correlated regions, thereby mitigating excessive locality and enhancing long-range dependencies; and (2) Hierarchical Consistency Constraint (HCC), which augments residual learning with full reconstruction supervision at each scale, exposing accumulated deviations early and stabilizing the coarse-to-fine refinement process. Extensive experiments demonstrate that AlignVAR consistently enhances structural coherence and perceptual fidelity over existing generative methods, while delivering over 10x faster inference with nearly 50% fewer parameters than leading diffusion-based approaches, establishing a new paradigm for efficient ISR.
Bid Farewell to Seesaw: Towards Accurate Long-tail Session-based Recommendation via Dual Constraints of Hybrid Intents
Nov 11, 2025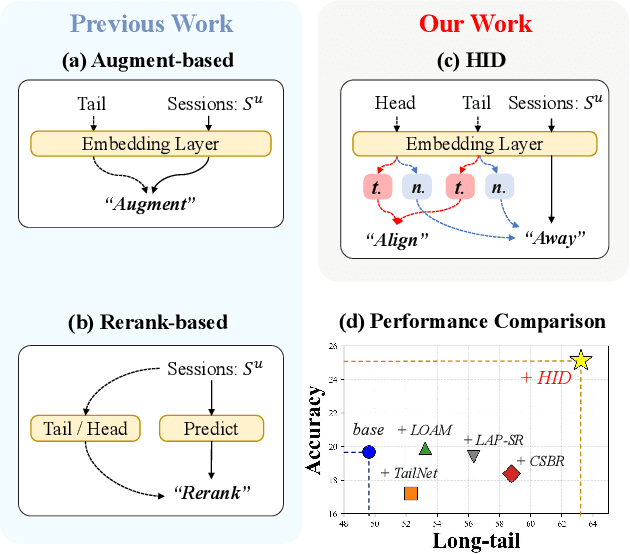
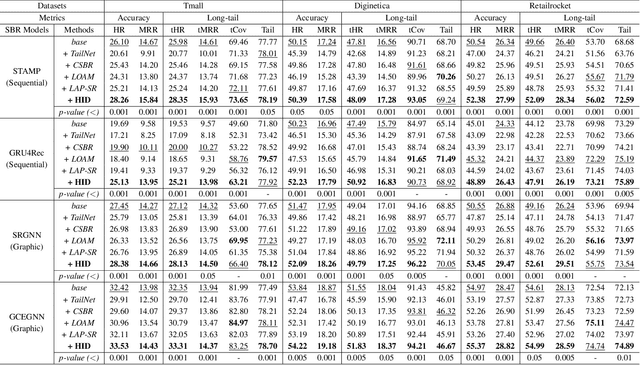
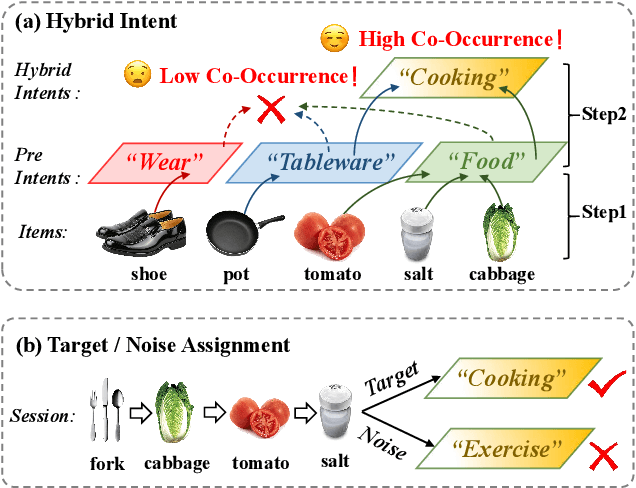

Session-based recommendation (SBR) aims to predict anonymous users' next interaction based on their interaction sessions. In the practical recommendation scenario, low-exposure items constitute the majority of interactions, creating a long-tail distribution that severely compromises recommendation diversity. Existing approaches attempt to address this issue by promoting tail items but incur accuracy degradation, exhibiting a "see-saw" effect between long-tail and accuracy performance. We attribute such conflict to session-irrelevant noise within the tail items, which existing long-tail approaches fail to identify and constrain effectively. To resolve this fundamental conflict, we propose \textbf{HID} (\textbf{H}ybrid \textbf{I}ntent-based \textbf{D}ual Constraint Framework), a plug-and-play framework that transforms the conventional "see-saw" into "win-win" through introducing the hybrid intent-based dual constraints for both long-tail and accuracy. Two key innovations are incorporated in this framework: (i) \textit{Hybrid Intent Learning}, where we reformulate the intent extraction strategies by employing attribute-aware spectral clustering to reconstruct the item-to-intent mapping. Furthermore, discrimination of session-irrelevant noise is achieved through the assignment of the target and noise intents to each session. (ii) \textit{Intent Constraint Loss}, which incorporates two novel constraint paradigms regarding the \textit{diversity} and \textit{accuracy} to regulate the representation learning process of both items and sessions. These two objectives are unified into a single training loss through rigorous theoretical derivation. Extensive experiments across multiple SBR models and datasets demonstrate that HID can enhance both long-tail performance and recommendation accuracy, establishing new state-of-the-art performance in long-tail recommender systems.
Beyond Random: Automatic Inner-loop Optimization in Dataset Distillation
Oct 06, 2025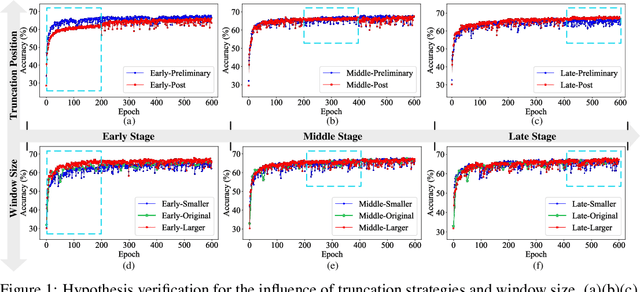
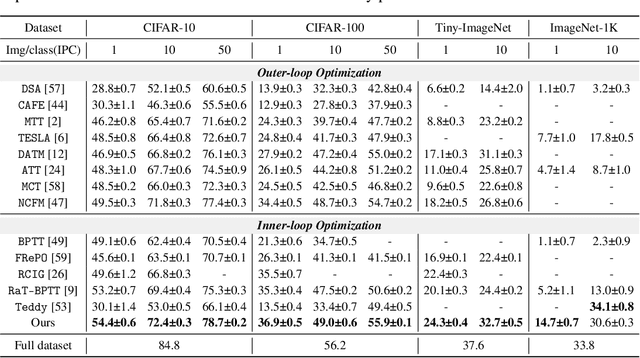
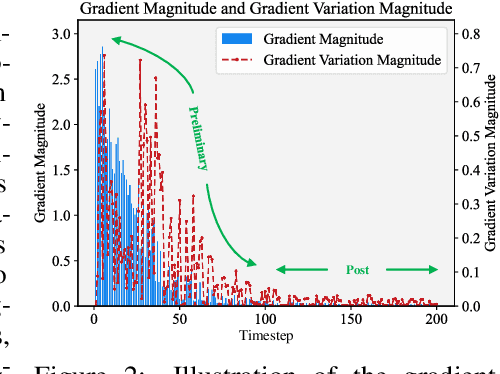
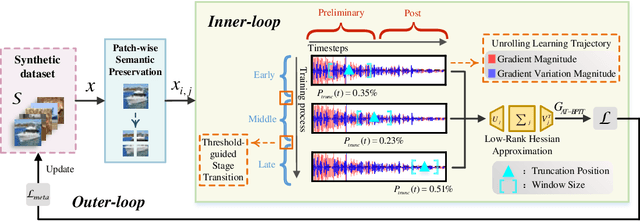
The growing demand for efficient deep learning has positioned dataset distillation as a pivotal technique for compressing training dataset while preserving model performance. However, existing inner-loop optimization methods for dataset distillation typically rely on random truncation strategies, which lack flexibility and often yield suboptimal results. In this work, we observe that neural networks exhibit distinct learning dynamics across different training stages-early, middle, and late-making random truncation ineffective. To address this limitation, we propose Automatic Truncated Backpropagation Through Time (AT-BPTT), a novel framework that dynamically adapts both truncation positions and window sizes according to intrinsic gradient behavior. AT-BPTT introduces three key components: (1) a probabilistic mechanism for stage-aware timestep selection, (2) an adaptive window sizing strategy based on gradient variation, and (3) a low-rank Hessian approximation to reduce computational overhead. Extensive experiments on CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet-1K show that AT-BPTT achieves state-of-the-art performance, improving accuracy by an average of 6.16% over baseline methods. Moreover, our approach accelerates inner-loop optimization by 3.9x while saving 63% memory cost.
Knowledge-Aligned Counterfactual-Enhancement Diffusion Perception for Unsupervised Cross-Domain Visual Emotion Recognition
May 26, 2025Visual Emotion Recognition (VER) is a critical yet challenging task aimed at inferring emotional states of individuals based on visual cues. However, existing works focus on single domains, e.g., realistic images or stickers, limiting VER models' cross-domain generalizability. To fill this gap, we introduce an Unsupervised Cross-Domain Visual Emotion Recognition (UCDVER) task, which aims to generalize visual emotion recognition from the source domain (e.g., realistic images) to the low-resource target domain (e.g., stickers) in an unsupervised manner. Compared to the conventional unsupervised domain adaptation problems, UCDVER presents two key challenges: a significant emotional expression variability and an affective distribution shift. To mitigate these issues, we propose the Knowledge-aligned Counterfactual-enhancement Diffusion Perception (KCDP) framework. Specifically, KCDP leverages a VLM to align emotional representations in a shared knowledge space and guides diffusion models for improved visual affective perception. Furthermore, a Counterfactual-Enhanced Language-image Emotional Alignment (CLIEA) method generates high-quality pseudo-labels for the target domain. Extensive experiments demonstrate that our model surpasses SOTA models in both perceptibility and generalization, e.g., gaining 12% improvements over the SOTA VER model TGCA-PVT. The project page is at https://yinwen2019.github.io/ucdver.
Adaptive Dataset Quantization
Dec 22, 2024Contemporary deep learning, characterized by the training of cumbersome neural networks on massive datasets, confronts substantial computational hurdles. To alleviate heavy data storage burdens on limited hardware resources, numerous dataset compression methods such as dataset distillation (DD) and coreset selection have emerged to obtain a compact but informative dataset through synthesis or selection for efficient training. However, DD involves an expensive optimization procedure and exhibits limited generalization across unseen architectures, while coreset selection is limited by its low data keep ratio and reliance on heuristics, hindering its practicality and feasibility. To address these limitations, we introduce a newly versatile framework for dataset compression, namely Adaptive Dataset Quantization (ADQ). Specifically, we first identify the sub-optimal performance of naive Dataset Quantization (DQ), which relies on uniform sampling and overlooks the varying importance of each generated bin. Subsequently, we propose a novel adaptive sampling strategy through the evaluation of generated bins' representativeness score, diversity score and importance score, where the former two scores are quantified by the texture level and contrastive learning-based techniques, respectively. Extensive experiments demonstrate that our method not only exhibits superior generalization capability across different architectures, but also attains state-of-the-art results, surpassing DQ by average 3\% on various datasets.
Towards Effective Data-Free Knowledge Distillation via Diverse Diffusion Augmentation
Oct 23, 2024Data-free knowledge distillation (DFKD) has emerged as a pivotal technique in the domain of model compression, substantially reducing the dependency on the original training data. Nonetheless, conventional DFKD methods that employ synthesized training data are prone to the limitations of inadequate diversity and discrepancies in distribution between the synthesized and original datasets. To address these challenges, this paper introduces an innovative approach to DFKD through diverse diffusion augmentation (DDA). Specifically, we revise the paradigm of common data synthesis in DFKD to a composite process through leveraging diffusion models subsequent to data synthesis for self-supervised augmentation, which generates a spectrum of data samples with similar distributions while retaining controlled variations. Furthermore, to mitigate excessive deviation in the embedding space, we introduce an image filtering technique grounded in cosine similarity to maintain fidelity during the knowledge distillation process. Comprehensive experiments conducted on CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets showcase the superior performance of our method across various teacher-student network configurations, outperforming the contemporary state-of-the-art DFKD methods. Code will be available at:https://github.com/SLGSP/DDA.
Real-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024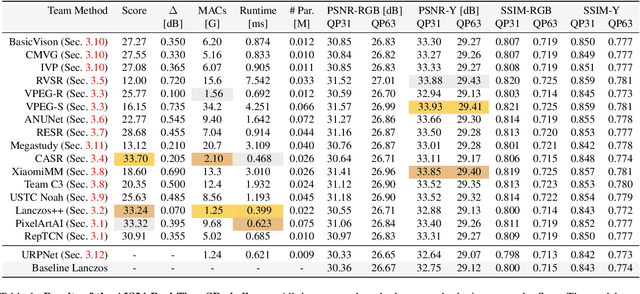
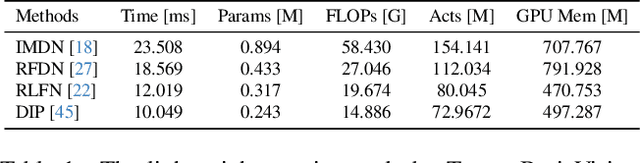
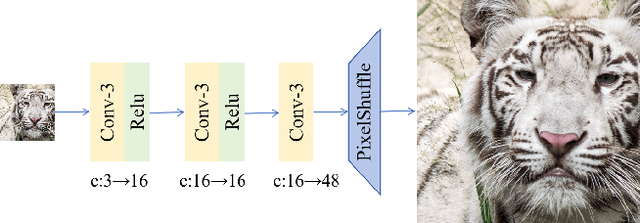
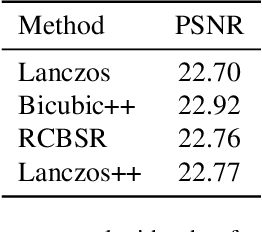
This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.
Towards Lifelong Scene Graph Generation with Knowledge-ware In-context Prompt Learning
Jan 26, 2024Scene graph generation (SGG) endeavors to predict visual relationships between pairs of objects within an image. Prevailing SGG methods traditionally assume a one-off learning process for SGG. This conventional paradigm may necessitate repetitive training on all previously observed samples whenever new relationships emerge, mitigating the risk of forgetting previously acquired knowledge. This work seeks to address this pitfall inherent in a suite of prior relationship predictions. Motivated by the achievements of in-context learning in pretrained language models, our approach imbues the model with the capability to predict relationships and continuously acquire novel knowledge without succumbing to catastrophic forgetting. To achieve this goal, we introduce a novel and pragmatic framework for scene graph generation, namely Lifelong Scene Graph Generation (LSGG), where tasks, such as predicates, unfold in a streaming fashion. In this framework, the model is constrained to exclusive training on the present task, devoid of access to previously encountered training data, except for a limited number of exemplars, but the model is tasked with inferring all predicates it has encountered thus far. Rigorous experiments demonstrate the superiority of our proposed method over state-of-the-art SGG models in the context of LSGG across a diverse array of metrics. Besides, extensive experiments on the two mainstream benchmark datasets, VG and Open-Image(v6), show the superiority of our proposed model to a number of competitive SGG models in terms of continuous learning and conventional settings. Moreover, comprehensive ablation experiments demonstrate the effectiveness of each component in our model.
AIM 2020 Challenge on Video Extreme Super-Resolution: Methods and Results
Sep 14, 2020This paper reviews the video extreme super-resolution challenge associated with the AIM 2020 workshop at ECCV 2020. Common scaling factors for learned video super-resolution (VSR) do not go beyond factor 4. Missing information can be restored well in this region, especially in HR videos, where the high-frequency content mostly consists of texture details. The task in this challenge is to upscale videos with an extreme factor of 16, which results in more serious degradations that also affect the structural integrity of the videos. A single pixel in the low-resolution (LR) domain corresponds to 256 pixels in the high-resolution (HR) domain. Due to this massive information loss, it is hard to accurately restore the missing information. Track 1 is set up to gauge the state-of-the-art for such a demanding task, where fidelity to the ground truth is measured by PSNR and SSIM. Perceptually higher quality can be achieved in trade-off for fidelity by generating plausible high-frequency content. Track 2 therefore aims at generating visually pleasing results, which are ranked according to human perception, evaluated by a user study. In contrast to single image super-resolution (SISR), VSR can benefit from additional information in the temporal domain. However, this also imposes an additional requirement, as the generated frames need to be consistent along time.