 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiCAL:Typicality-Based Consistency-Aware Learning for Multimodal Emotion Recognition
Nov 19, 2025Multimodal Emotion Recognition (MER) aims to accurately identify human emotional states by integrating heterogeneous modalities such as visual, auditory, and textual data. Existing approaches predominantly rely on unified emotion labels to supervise model training, often overlooking a critical challenge: inter-modal emotion conflicts, wherein different modalities within the same sample may express divergent emotional tendencies. In this work, we address this overlooked issue by proposing a novel framework, Typicality-based Consistent-aware Multimodal Emotion Recognition (TiCAL), inspired by the stage-wise nature of human emotion perception. TiCAL dynamically assesses the consistency of each training sample by leveraging pseudo unimodal emotion labels alongside a typicality estimation. To further enhance emotion representation, we embed features in a hyperbolic space, enabling the capture of fine-grained distinctions among emotional categories. By incorporating consistency estimates into the learning process, our method improves model performance, particularly on samples exhibiting high modality inconsistency. Extensive experiments on benchmark datasets, e.g, CMU-MOSEI and MER2023, validate the effectiveness of TiCAL in mitigating inter-modal emotional conflicts and enhancing overall recognition accuracy, e.g., with about 2.6% improvements over the state-of-the-art DMD.
Bid Farewell to Seesaw: Towards Accurate Long-tail Session-based Recommendation via Dual Constraints of Hybrid Intents
Nov 11, 2025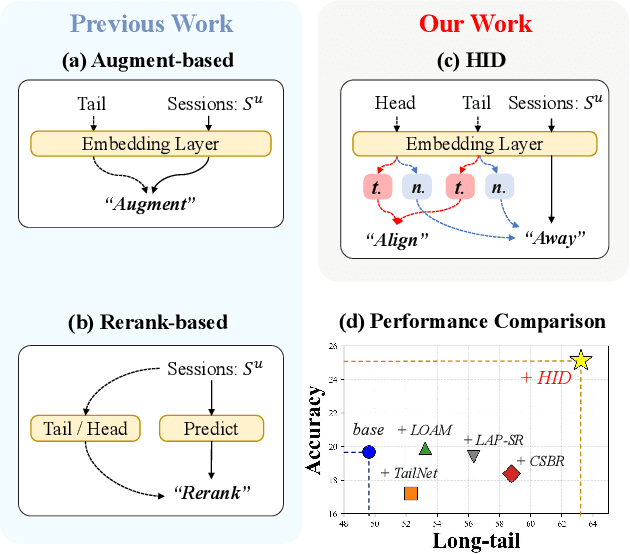
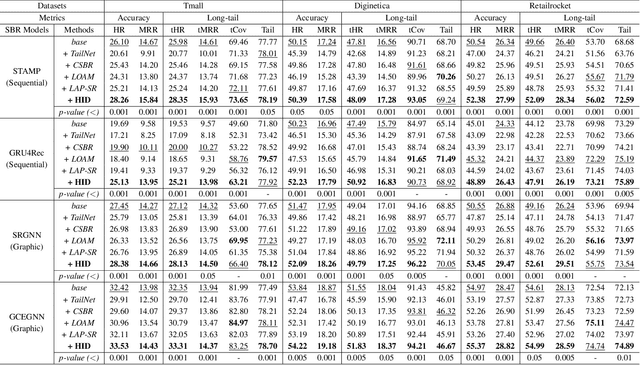
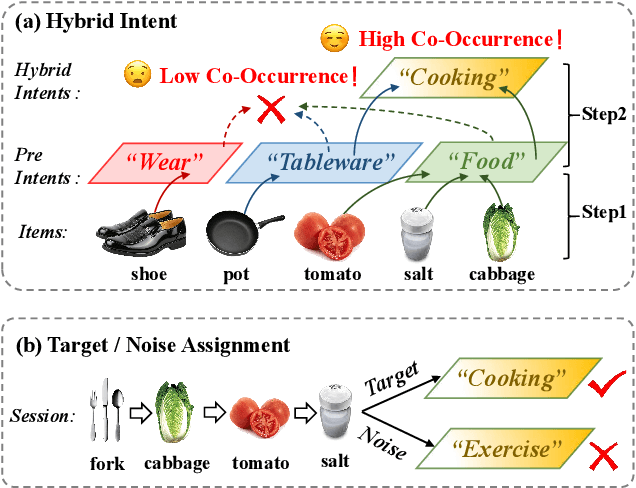

Session-based recommendation (SBR) aims to predict anonymous users' next interaction based on their interaction sessions. In the practical recommendation scenario, low-exposure items constitute the majority of interactions, creating a long-tail distribution that severely compromises recommendation diversity. Existing approaches attempt to address this issue by promoting tail items but incur accuracy degradation, exhibiting a "see-saw" effect between long-tail and accuracy performance. We attribute such conflict to session-irrelevant noise within the tail items, which existing long-tail approaches fail to identify and constrain effectively. To resolve this fundamental conflict, we propose \textbf{HID} (\textbf{H}ybrid \textbf{I}ntent-based \textbf{D}ual Constraint Framework), a plug-and-play framework that transforms the conventional "see-saw" into "win-win" through introducing the hybrid intent-based dual constraints for both long-tail and accuracy. Two key innovations are incorporated in this framework: (i) \textit{Hybrid Intent Learning}, where we reformulate the intent extraction strategies by employing attribute-aware spectral clustering to reconstruct the item-to-intent mapping. Furthermore, discrimination of session-irrelevant noise is achieved through the assignment of the target and noise intents to each session. (ii) \textit{Intent Constraint Loss}, which incorporates two novel constraint paradigms regarding the \textit{diversity} and \textit{accuracy} to regulate the representation learning process of both items and sessions. These two objectives are unified into a single training loss through rigorous theoretical derivation. Extensive experiments across multiple SBR models and datasets demonstrate that HID can enhance both long-tail performance and recommendation accuracy, establishing new state-of-the-art performance in long-tail recommender systems.
Beyond Random: Automatic Inner-loop Optimization in Dataset Distillation
Oct 06, 2025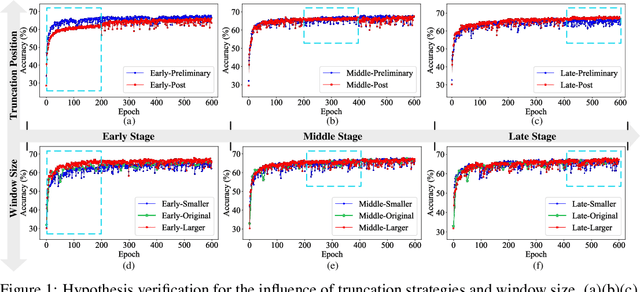
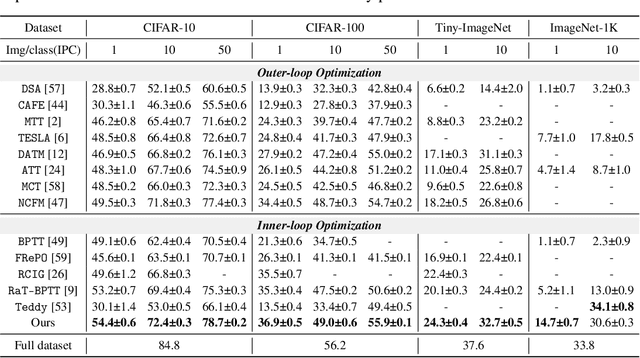
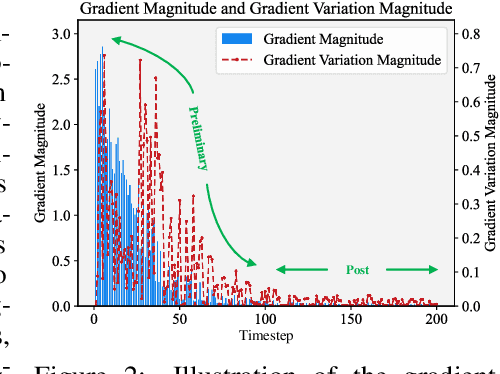
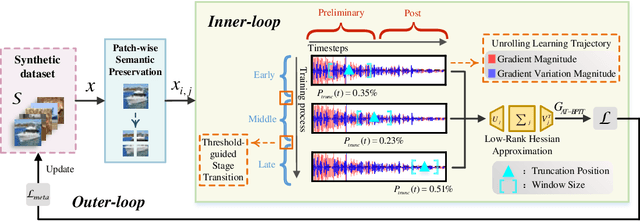
The growing demand for efficient deep learning has positioned dataset distillation as a pivotal technique for compressing training dataset while preserving model performance. However, existing inner-loop optimization methods for dataset distillation typically rely on random truncation strategies, which lack flexibility and often yield suboptimal results. In this work, we observe that neural networks exhibit distinct learning dynamics across different training stages-early, middle, and late-making random truncation ineffective. To address this limitation, we propose Automatic Truncated Backpropagation Through Time (AT-BPTT), a novel framework that dynamically adapts both truncation positions and window sizes according to intrinsic gradient behavior. AT-BPTT introduces three key components: (1) a probabilistic mechanism for stage-aware timestep selection, (2) an adaptive window sizing strategy based on gradient variation, and (3) a low-rank Hessian approximation to reduce computational overhead. Extensive experiments on CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet-1K show that AT-BPTT achieves state-of-the-art performance, improving accuracy by an average of 6.16% over baseline methods. Moreover, our approach accelerates inner-loop optimization by 3.9x while saving 63% memory cost.
Adaptive Dataset Quantization
Dec 22, 2024Contemporary deep learning, characterized by the training of cumbersome neural networks on massive datasets, confronts substantial computational hurdles. To alleviate heavy data storage burdens on limited hardware resources, numerous dataset compression methods such as dataset distillation (DD) and coreset selection have emerged to obtain a compact but informative dataset through synthesis or selection for efficient training. However, DD involves an expensive optimization procedure and exhibits limited generalization across unseen architectures, while coreset selection is limited by its low data keep ratio and reliance on heuristics, hindering its practicality and feasibility. To address these limitations, we introduce a newly versatile framework for dataset compression, namely Adaptive Dataset Quantization (ADQ). Specifically, we first identify the sub-optimal performance of naive Dataset Quantization (DQ), which relies on uniform sampling and overlooks the varying importance of each generated bin. Subsequently, we propose a novel adaptive sampling strategy through the evaluation of generated bins' representativeness score, diversity score and importance score, where the former two scores are quantified by the texture level and contrastive learning-based techniques, respectively. Extensive experiments demonstrate that our method not only exhibits superior generalization capability across different architectures, but also attains state-of-the-art results, surpassing DQ by average 3\% on various datasets.
Towards Effective Data-Free Knowledge Distillation via Diverse Diffusion Augmentation
Oct 23, 2024Data-free knowledge distillation (DFKD) has emerged as a pivotal technique in the domain of model compression, substantially reducing the dependency on the original training data. Nonetheless, conventional DFKD methods that employ synthesized training data are prone to the limitations of inadequate diversity and discrepancies in distribution between the synthesized and original datasets. To address these challenges, this paper introduces an innovative approach to DFKD through diverse diffusion augmentation (DDA). Specifically, we revise the paradigm of common data synthesis in DFKD to a composite process through leveraging diffusion models subsequent to data synthesis for self-supervised augmentation, which generates a spectrum of data samples with similar distributions while retaining controlled variations. Furthermore, to mitigate excessive deviation in the embedding space, we introduce an image filtering technique grounded in cosine similarity to maintain fidelity during the knowledge distillation process. Comprehensive experiments conducted on CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets showcase the superior performance of our method across various teacher-student network configurations, outperforming the contemporary state-of-the-art DFKD methods. Code will be available at:https://github.com/SLGSP/DDA.
SFedCA: Credit Assignment-Based Active Client Selection Strategy for Spiking Federated Learning
Jun 18, 2024



Spiking federated learning is an emerging distributed learning paradigm that allows resource-constrained devices to train collaboratively at low power consumption without exchanging local data. It takes advantage of both the privacy computation property in federated learning (FL) and the energy efficiency in spiking neural networks (SNN). Thus, it is highly promising to revolutionize the efficient processing of multimedia data. However, existing spiking federated learning methods employ a random selection approach for client aggregation, assuming unbiased client participation. This neglect of statistical heterogeneity affects the convergence and accuracy of the global model significantly. In our work, we propose a credit assignment-based active client selection strategy, the SFedCA, to judiciously aggregate clients that contribute to the global sample distribution balance. Specifically, the client credits are assigned by the firing intensity state before and after local model training, which reflects the local data distribution difference from the global model. Comprehensive experiments are conducted on various non-identical and independent distribution (non-IID) scenarios. The experimental results demonstrate that the SFedCA outperforms the existing state-of-the-art spiking federated learning methods, and requires fewer communication rounds.
ESVAE: An Efficient Spiking Variational Autoencoder with Reparameterizable Poisson Spiking Sampling
Oct 23, 2023



In recent years, studies on image generation models of spiking neural networks (SNNs) have gained the attention of many researchers. Variational autoencoders (VAEs), as one of the most popular image generation models, have attracted a lot of work exploring their SNN implementation. Due to the constrained binary representation in SNNs, existing SNN VAE methods implicitly construct the latent space by an elaborated autoregressive network and use the network outputs as the sampling variables. However, this unspecified implicit representation of the latent space will increase the difficulty of generating high-quality images and introduces additional network parameters. In this paper, we propose an efficient spiking variational autoencoder (ESVAE) that constructs an interpretable latent space distribution and design a reparameterizable spiking sampling method. Specifically, we construct the prior and posterior of the latent space as a Poisson distribution using the firing rate of the spiking neurons. Subsequently, we propose a reparameterizable Poisson spiking sampling method, which is free from the additional network. Comprehensive experiments have been conducted, and the experimental results show that the proposed ESVAE outperforms previous SNN VAE methods in reconstructed & generated images quality. In addition, experiments demonstrate that ESVAE's encoder is able to retain the original image information more efficiently, and the decoder is more robust. The source code is available at https://github.com/QgZhan/ESVAE.