 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFedHIFI: Fire Rate-Based Heterogeneous Information Fusion for Spiking Federated Learning
Mar 16, 2026Spiking Federated Learning (SFL) has been widely studied with the energy efficiency of Spiking Neural Networks (SNNs). However, existing SFL methods require model homogeneity and assume all clients have sufficient computational resources, resulting in the exclusion of some resource-constrained clients. To address the prevalent system heterogeneity in real-world scenarios, enabling heterogeneous SFL systems that allow clients to adaptively deploy models of different scales based on their local resources is crucial. To this end, we introduce SFedHIFI, a novel Spiking Federated Learning framework with Fire Rate-Based Heterogeneous Information Fusion. Specifically, SFedHIFI employs channel-wise matrix decomposition to deploy SNN models of adaptive complexity on clients with heterogeneous resources. Building on this, the proposed heterogeneous information fusion module enables cross-scale aggregation among models of different widths, thereby enhancing the utilization of diverse local knowledge. Extensive experiments on three public benchmarks demonstrate that SFedHIFI can effectively enable heterogeneous SFL, consistently outperforming all three baseline methods. Compared with ANN-based FL, it achieves significant energy savings with only a marginal trade-off in accuracy.
Traceable Latent Variable Discovery Based on Multi-Agent Collaboration
Feb 16, 2026Revealing the underlying causal mechanisms in the real world is crucial for scientific and technological progress. Despite notable advances in recent decades, the lack of high-quality data and the reliance of traditional causal discovery algorithms (TCDA) on the assumption of no latent confounders, as well as their tendency to overlook the precise semantics of latent variables, have long been major obstacles to the broader application of causal discovery. To address this issue, we propose a novel causal modeling framework, TLVD, which integrates the metadata-based reasoning capabilities of large language models (LLMs) with the data-driven modeling capabilities of TCDA for inferring latent variables and their semantics. Specifically, we first employ a data-driven approach to construct a causal graph that incorporates latent variables. Then, we employ multi-LLM collaboration for latent variable inference, modeling this process as a game with incomplete information and seeking its Bayesian Nash Equilibrium (BNE) to infer the possible specific latent variables. Finally, to validate the inferred latent variables across multiple real-world web-based data sources, we leverage LLMs for evidence exploration to ensure traceability. We comprehensively evaluate TLVD on three de-identified real patient datasets provided by a hospital and two benchmark datasets. Extensive experimental results confirm the effectiveness and reliability of TLVD, with average improvements of 32.67% in Acc, 62.21% in CAcc, and 26.72% in ECit across the five datasets.
Transferable Graph Condensation from the Causal Perspective
Jan 29, 2026The increasing scale of graph datasets has significantly improved the performance of graph representation learning methods, but it has also introduced substantial training challenges. Graph dataset condensation techniques have emerged to compress large datasets into smaller yet information-rich datasets, while maintaining similar test performance. However, these methods strictly require downstream applications to match the original dataset and task, which often fails in cross-task and cross-domain scenarios. To address these challenges, we propose a novel causal-invariance-based and transferable graph dataset condensation method, named \textbf{TGCC}, providing effective and transferable condensed datasets. Specifically, to preserve domain-invariant knowledge, we first extract domain causal-invariant features from the spatial domain of the graph using causal interventions. Then, to fully capture the structural and feature information of the original graph, we perform enhanced condensation operations. Finally, through spectral-domain enhanced contrastive learning, we inject the causal-invariant features into the condensed graph, ensuring that the compressed graph retains the causal information of the original graph. Experimental results on five public datasets and our novel \textbf{FinReport} dataset demonstrate that TGCC achieves up to a 13.41\% improvement in cross-task and cross-domain complex scenarios compared to existing methods, and achieves state-of-the-art performance on 5 out of 6 datasets in the single dataset and task scenario.
SFedCA: Credit Assignment-Based Active Client Selection Strategy for Spiking Federated Learning
Jun 18, 2024



Spiking federated learning is an emerging distributed learning paradigm that allows resource-constrained devices to train collaboratively at low power consumption without exchanging local data. It takes advantage of both the privacy computation property in federated learning (FL) and the energy efficiency in spiking neural networks (SNN). Thus, it is highly promising to revolutionize the efficient processing of multimedia data. However, existing spiking federated learning methods employ a random selection approach for client aggregation, assuming unbiased client participation. This neglect of statistical heterogeneity affects the convergence and accuracy of the global model significantly. In our work, we propose a credit assignment-based active client selection strategy, the SFedCA, to judiciously aggregate clients that contribute to the global sample distribution balance. Specifically, the client credits are assigned by the firing intensity state before and after local model training, which reflects the local data distribution difference from the global model. Comprehensive experiments are conducted on various non-identical and independent distribution (non-IID) scenarios. The experimental results demonstrate that the SFedCA outperforms the existing state-of-the-art spiking federated learning methods, and requires fewer communication rounds.
ESVAE: An Efficient Spiking Variational Autoencoder with Reparameterizable Poisson Spiking Sampling
Oct 23, 2023



In recent years, studies on image generation models of spiking neural networks (SNNs) have gained the attention of many researchers. Variational autoencoders (VAEs), as one of the most popular image generation models, have attracted a lot of work exploring their SNN implementation. Due to the constrained binary representation in SNNs, existing SNN VAE methods implicitly construct the latent space by an elaborated autoregressive network and use the network outputs as the sampling variables. However, this unspecified implicit representation of the latent space will increase the difficulty of generating high-quality images and introduces additional network parameters. In this paper, we propose an efficient spiking variational autoencoder (ESVAE) that constructs an interpretable latent space distribution and design a reparameterizable spiking sampling method. Specifically, we construct the prior and posterior of the latent space as a Poisson distribution using the firing rate of the spiking neurons. Subsequently, we propose a reparameterizable Poisson spiking sampling method, which is free from the additional network. Comprehensive experiments have been conducted, and the experimental results show that the proposed ESVAE outperforms previous SNN VAE methods in reconstructed & generated images quality. In addition, experiments demonstrate that ESVAE's encoder is able to retain the original image information more efficiently, and the decoder is more robust. The source code is available at https://github.com/QgZhan/ESVAE.
Sparse Label Smoothing for Semi-supervised Person Re-Identification
Oct 11, 2018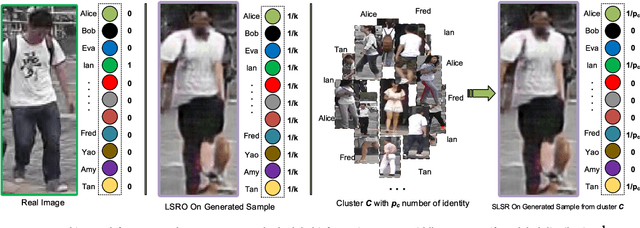

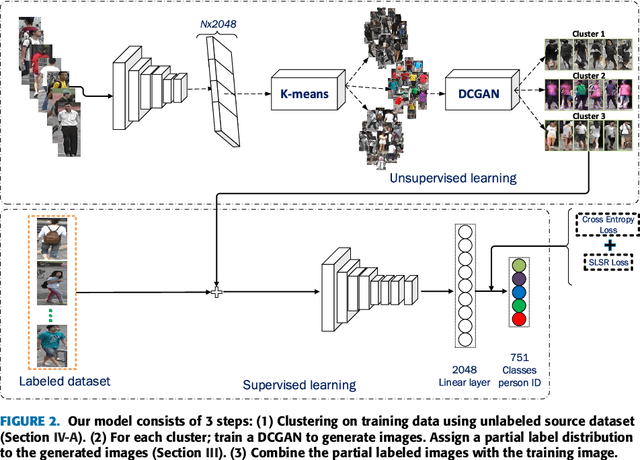

Person re-identification (re-id) is a cross-camera retrieval task which establishes a correspondence between images of a person from multiple cameras. Deep Learning methods have been successfully applied to the problem and achieved impressive results. However, these methods require large amounts of labeled training data. Current labeled datasets in person re-id are limited in scale and manually acquiring such large-scale dataset in surveillance camera is a tedious and labor-intensive task. In this paper, we propose a semi-supervised framework that performs Sparse Label Smoothing Regularization (SLSR) by considering similarities between unlabeled sample and training sample in the same feature space. Our approach first exploits the clustering property of existing person re-id datasets to create groups of similar objects that model the correlation among view. We make use of the training set to create cluster of similar objects using the intermediate feature representation of a CNN model. Each cluster is used to generate synthetic data samples using a generative adversarial model. We finally defined a sparse smoothing regularization term and train the network with join supervision of cross-entropy loss. The proposed approach tackles two problems (1) how to efficiently use the generated data and (2) how to address the over-smoothness problem found in current regularization. We solve these two problems by using a generative model for data augmentation and by maintaining and propagating similarities across the network through the concatenation of training images and generated images into one homogeneous feature space. Extensive experiments on four large-scale datasets show that our regularization method significantly improves the Re-ID accuracy compared to existing semi-supervised methods.
Self Attention Grid for Person Re-Identification
Sep 23, 2018
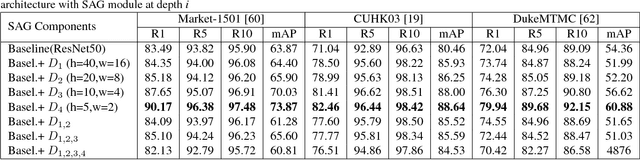
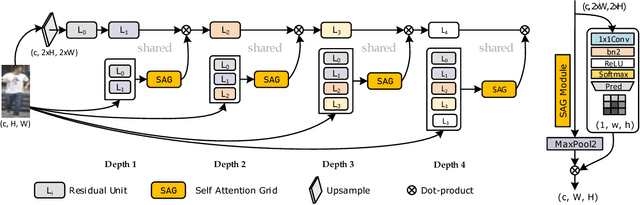
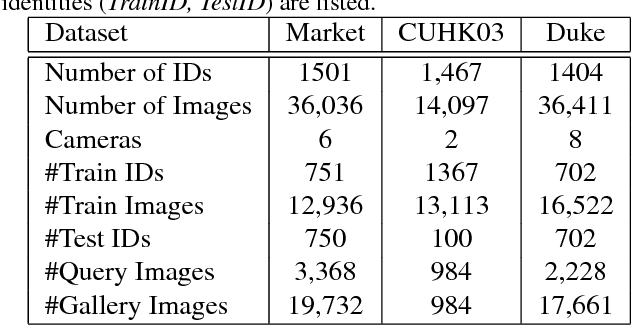
In this paper, we present an attention mechanism scheme to improve person re-identification task. Inspired by biology, we propose Self Attention Grid (SAG) to discover the most informative parts from a high-resolution image using its internal representation. In particular, given an input image, the proposed model is fed with two copies of the same image and consists of two branches. The upper branch processes the high-resolution image and learns high dimensional feature representation while the lower branch processes the low-resolution image and learn a filtering attention grid. We apply a max filter operation to non-overlapping sub-regions on the high feature representation before element-wise multiplied with the output of the second branch. The feature maps of the second branch are subsequently weighted to reflect the importance of each patch of the grid using a softmax operation. Our attention module helps the network learn the most discriminative visual features of multiple image regions and is specifically optimized to attend feature representation at different levels. Extensive experiments on three large-scale datasets show that our self-attention mechanism significantly improves the baseline model and outperforms various state-of-art models by a large margin.