 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAirway Skill Assessment with Spatiotemporal Attention Mechanisms Using Human Gaze
Jun 24, 2025


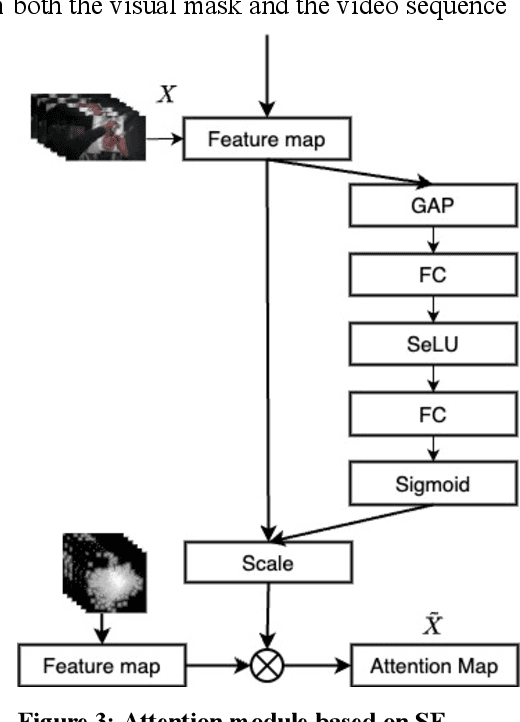
Airway management skills are critical in emergency medicine and are typically assessed through subjective evaluation, often failing to gauge competency in real-world scenarios. This paper proposes a machine learning-based approach for assessing airway skills, specifically endotracheal intubation (ETI), using human gaze data and video recordings. The proposed system leverages an attention mechanism guided by the human gaze to enhance the recognition of successful and unsuccessful ETI procedures. Visual masks were created from gaze points to guide the model in focusing on task-relevant areas, reducing irrelevant features. An autoencoder network extracts features from the videos, while an attention module generates attention from the visual masks, and a classifier outputs a classification score. This method, the first to use human gaze for ETI, demonstrates improved accuracy and efficiency over traditional methods. The integration of human gaze data not only enhances model performance but also offers a robust, objective assessment tool for clinical skills, particularly in high-stress environments such as military settings. The results show improvements in prediction accuracy, sensitivity, and trustworthiness, highlighting the potential for this approach to improve clinical training and patient outcomes in emergency medicine.
* 13 pages, 6 figures, 14 equations,
Deep Learning for Video-Based Assessment of Endotracheal Intubation Skills
Apr 17, 2024



Endotracheal intubation (ETI) is an emergency procedure performed in civilian and combat casualty care settings to establish an airway. Objective and automated assessment of ETI skills is essential for the training and certification of healthcare providers. However, the current approach is based on manual feedback by an expert, which is subjective, time- and resource-intensive, and is prone to poor inter-rater reliability and halo effects. This work proposes a framework to evaluate ETI skills using single and multi-view videos. The framework consists of two stages. First, a 2D convolutional autoencoder (AE) and a pre-trained self-supervision network extract features from videos. Second, a 1D convolutional enhanced with a cross-view attention module takes the features from the AE as input and outputs predictions for skill evaluation. The ETI datasets were collected in two phases. In the first phase, ETI is performed by two subject cohorts: Experts and Novices. In the second phase, novice subjects perform ETI under time pressure, and the outcome is either Successful or Unsuccessful. A third dataset of videos from a single head-mounted camera for Experts and Novices is also analyzed. The study achieved an accuracy of 100% in identifying Expert/Novice trials in the initial phase. In the second phase, the model showed 85% accuracy in classifying Successful/Unsuccessful procedures. Using head-mounted cameras alone, the model showed a 96% accuracy on Expert and Novice classification while maintaining an accuracy of 85% on classifying successful and unsuccessful. In addition, GradCAMs are presented to explain the differences between Expert and Novice behavior and Successful and Unsuccessful trials. The approach offers a reliable and objective method for automated assessment of ETI skills.
Scene Recognition with Objectness, Attribute and Category Learning
Jul 20, 2022
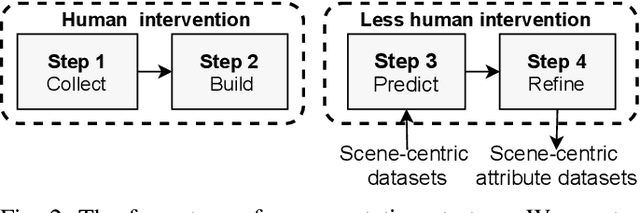
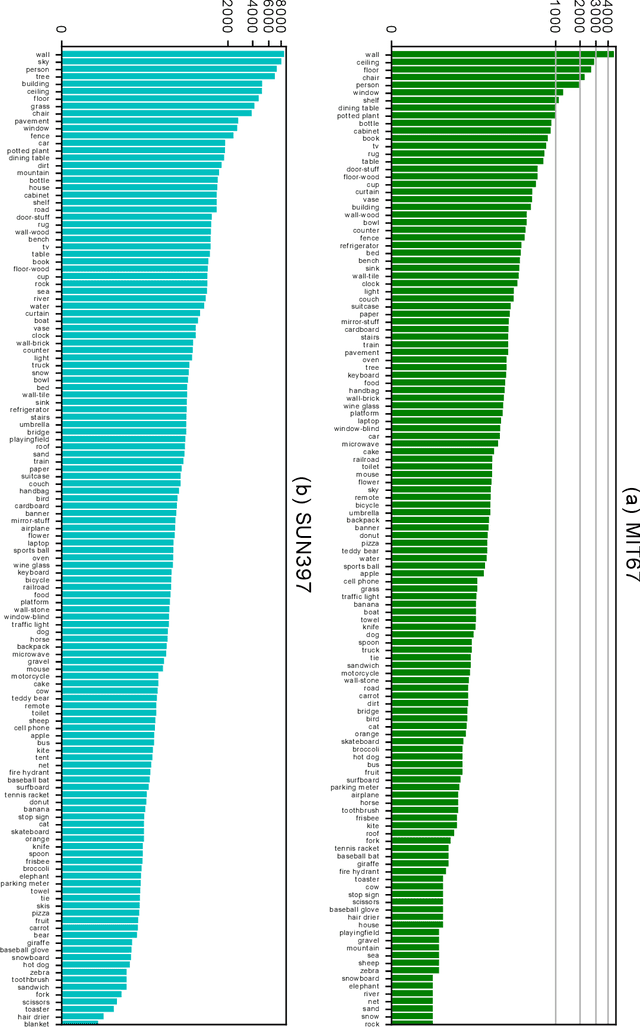
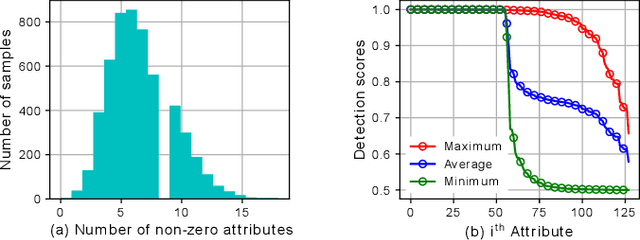
Scene classification has established itself as a challenging research problem. Compared to images of individual objects, scene images could be much more semantically complex and abstract. Their difference mainly lies in the level of granularity of recognition. Yet, image recognition serves as a key pillar for the good performance of scene recognition as the knowledge attained from object images can be used for accurate recognition of scenes. The existing scene recognition methods only take the category label of the scene into consideration. However, we find that the contextual information that contains detailed local descriptions are also beneficial in allowing the scene recognition model to be more discriminative. In this paper, we aim to improve scene recognition using attribute and category label information encoded in objects. Based on the complementarity of attribute and category labels, we propose a Multi-task Attribute-Scene Recognition (MASR) network which learns a category embedding and at the same time predicts scene attributes. Attribute acquisition and object annotation are tedious and time consuming tasks. We tackle the problem by proposing a partially supervised annotation strategy in which human intervention is significantly reduced. The strategy provides a much more cost-effective solution to real world scenarios, and requires considerably less annotation efforts. Moreover, we re-weight the attribute predictions considering the level of importance indicated by the object detected scores. Using the proposed method, we efficiently annotate attribute labels for four large-scale datasets, and systematically investigate how scene and attribute recognition benefit from each other. The experimental results demonstrate that MASR learns a more discriminative representation and achieves competitive recognition performance compared to the state-of-the-art methods
Sparse Label Smoothing for Semi-supervised Person Re-Identification
Oct 11, 2018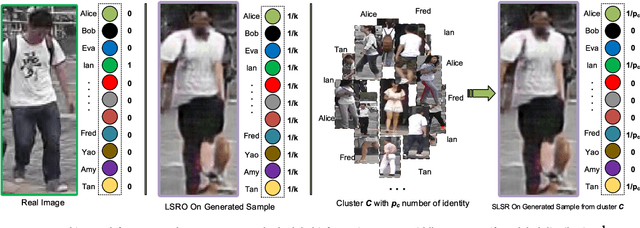

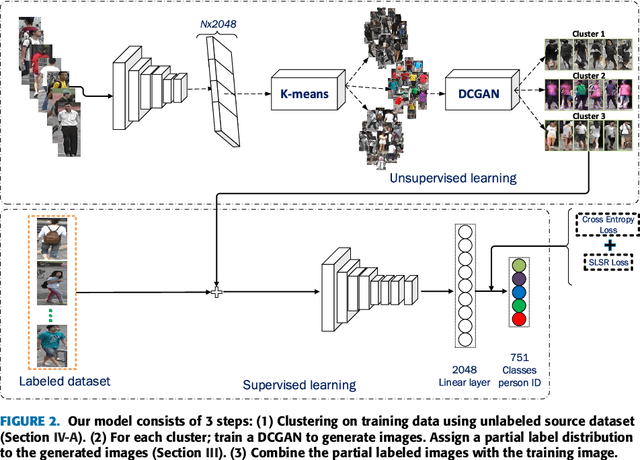

Person re-identification (re-id) is a cross-camera retrieval task which establishes a correspondence between images of a person from multiple cameras. Deep Learning methods have been successfully applied to the problem and achieved impressive results. However, these methods require large amounts of labeled training data. Current labeled datasets in person re-id are limited in scale and manually acquiring such large-scale dataset in surveillance camera is a tedious and labor-intensive task. In this paper, we propose a semi-supervised framework that performs Sparse Label Smoothing Regularization (SLSR) by considering similarities between unlabeled sample and training sample in the same feature space. Our approach first exploits the clustering property of existing person re-id datasets to create groups of similar objects that model the correlation among view. We make use of the training set to create cluster of similar objects using the intermediate feature representation of a CNN model. Each cluster is used to generate synthetic data samples using a generative adversarial model. We finally defined a sparse smoothing regularization term and train the network with join supervision of cross-entropy loss. The proposed approach tackles two problems (1) how to efficiently use the generated data and (2) how to address the over-smoothness problem found in current regularization. We solve these two problems by using a generative model for data augmentation and by maintaining and propagating similarities across the network through the concatenation of training images and generated images into one homogeneous feature space. Extensive experiments on four large-scale datasets show that our regularization method significantly improves the Re-ID accuracy compared to existing semi-supervised methods.
Self Attention Grid for Person Re-Identification
Sep 23, 2018
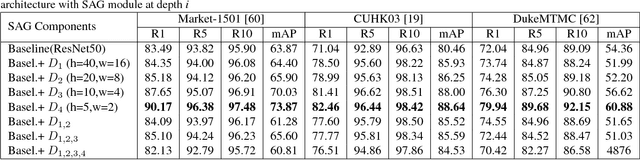
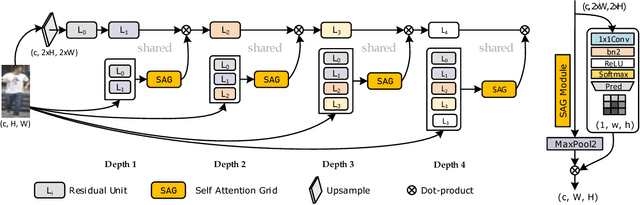
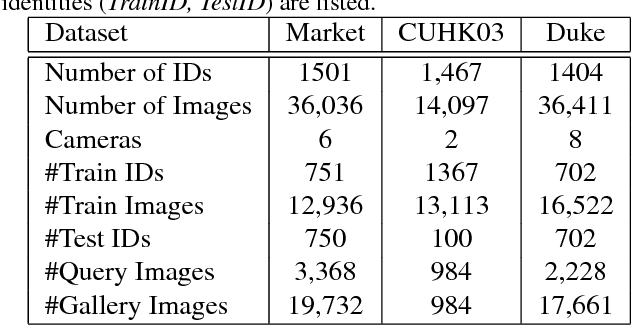
In this paper, we present an attention mechanism scheme to improve person re-identification task. Inspired by biology, we propose Self Attention Grid (SAG) to discover the most informative parts from a high-resolution image using its internal representation. In particular, given an input image, the proposed model is fed with two copies of the same image and consists of two branches. The upper branch processes the high-resolution image and learns high dimensional feature representation while the lower branch processes the low-resolution image and learn a filtering attention grid. We apply a max filter operation to non-overlapping sub-regions on the high feature representation before element-wise multiplied with the output of the second branch. The feature maps of the second branch are subsequently weighted to reflect the importance of each patch of the grid using a softmax operation. Our attention module helps the network learn the most discriminative visual features of multiple image regions and is specifically optimized to attend feature representation at different levels. Extensive experiments on three large-scale datasets show that our self-attention mechanism significantly improves the baseline model and outperforms various state-of-art models by a large margin.