 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Virtual Reality and Large Language Models for Team-Based Non-Technical Skills Training and Evaluation in the Operating Room
Jan 19, 2026Although effective teamwork and communication are critical to surgical safety, structured training for non-technical skills (NTS) remains limited compared with technical simulation. The ACS/APDS Phase III Team-Based Skills Curriculum calls for scalable tools that both teach and objectively assess these competencies during laparoscopic emergencies. We introduce the Virtual Operating Room Team Experience (VORTeX), a multi-user virtual reality (VR) platform that integrates immersive team simulation with large language model (LLM) analytics to train and evaluate communication, decision-making, teamwork, and leadership. Team dialogue is analyzed using structured prompts derived from the Non-Technical Skills for Surgeons (NOTSS) framework, enabling automated classification of behaviors and generation of directed interaction graphs that quantify communication structure and hierarchy. Two laparoscopic emergency scenarios, pneumothorax and intra-abdominal bleeding, were implemented to elicit realistic stress and collaboration. Twelve surgical professionals completed pilot sessions at the 2024 SAGES conference, rating VORTeX as intuitive, immersive, and valuable for developing teamwork and communication. The LLM consistently produced interpretable communication networks reflecting expected operative hierarchies, with surgeons as central integrators, nurses as initiators, and anesthesiologists as balanced intermediaries. By integrating immersive VR with LLM-driven behavioral analytics, VORTeX provides a scalable, privacy-compliant framework for objective assessment and automated, data-informed debriefing across distributed training environments.
Airway Skill Assessment with Spatiotemporal Attention Mechanisms Using Human Gaze
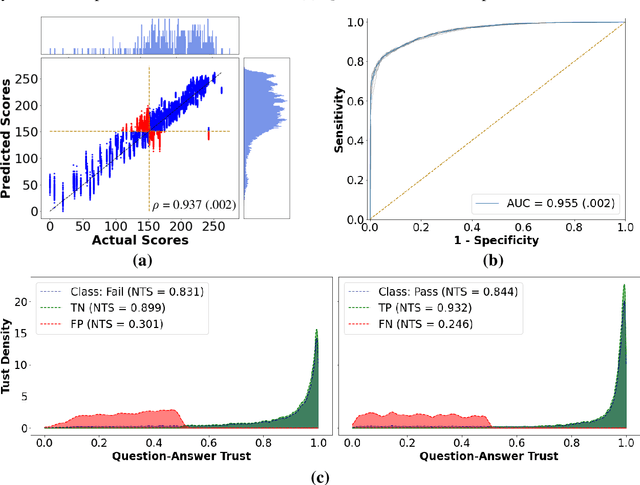
Jun 24, 2025Airway management skills are critical in emergency medicine and are typically assessed through subjective evaluation, often failing to gauge competency in real-world scenarios. This paper proposes a machine learning-based approach for assessing airway skills, specifically endotracheal intubation (ETI), using human gaze data and video recordings. The proposed system leverages an attention mechanism guided by the human gaze to enhance the recognition of successful and unsuccessful ETI procedures. Visual masks were created from gaze points to guide the model in focusing on task-relevant areas, reducing irrelevant features. An autoencoder network extracts features from the videos, while an attention module generates attention from the visual masks, and a classifier outputs a classification score. This method, the first to use human gaze for ETI, demonstrates improved accuracy and efficiency over traditional methods. The integration of human gaze data not only enhances model performance but also offers a robust, objective assessment tool for clinical skills, particularly in high-stress environments such as military settings. The results show improvements in prediction accuracy, sensitivity, and trustworthiness, highlighting the potential for this approach to improve clinical training and patient outcomes in emergency medicine.
* 13 pages, 6 figures, 14 equations,
Beyond Performance Scores: Directed Functional Connectivity as a Brain-Based Biomarker for Motor Skill Learning and Retention
Feb 20, 2025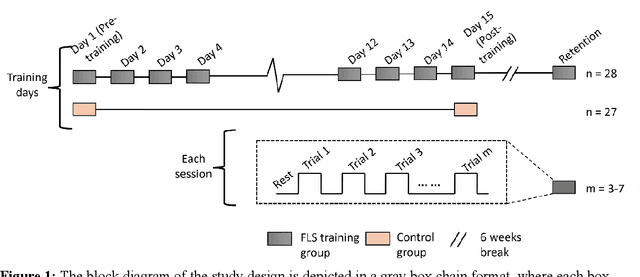

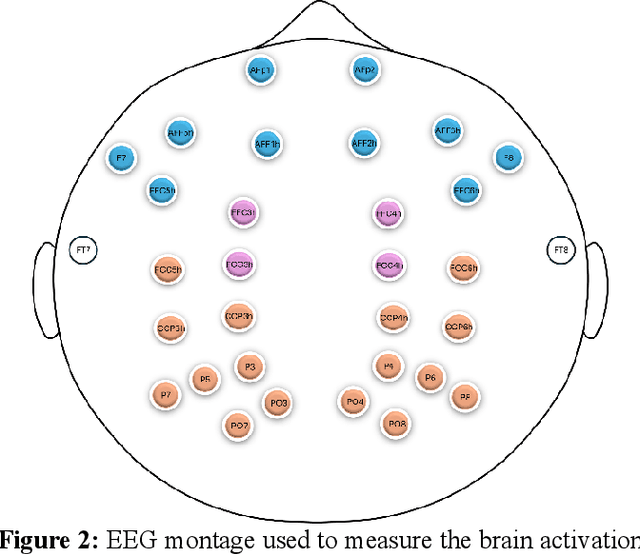
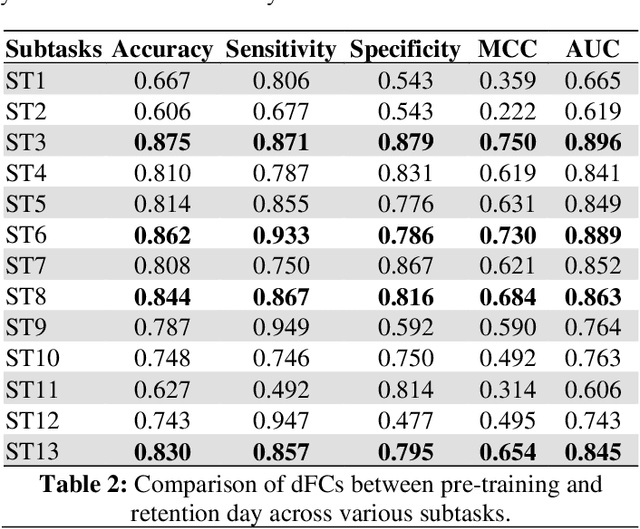
Motor skill acquisition in fields like surgery, robotics, and sports involves learning complex task sequences through extensive training. Traditional performance metrics, like execution time and error rates, offer limited insight as they fail to capture the neural mechanisms underlying skill learning and retention. This study introduces directed functional connectivity (dFC), derived from electroencephalography (EEG), as a novel brain-based biomarker for assessing motor skill learning and retention. For the first time, dFC is applied as a biomarker to map the stages of the Fitts and Posner motor learning model, offering new insights into the neural mechanisms underlying skill acquisition and retention. Unlike traditional measures, it captures both the strength and direction of neural information flow, providing a comprehensive understanding of neural adaptations across different learning stages. The analysis demonstrates that dFC can effectively identify and track the progression through various stages of the Fitts and Posner model. Furthermore, its stability over a six-week washout period highlights its utility in monitoring long-term retention. No significant changes in dFC were observed in a control group, confirming that the observed neural adaptations were specific to training and not due to external factors. By offering a granular view of the learning process at the group and individual levels, dFC facilitates the development of personalized, targeted training protocols aimed at enhancing outcomes in fields where precision and long-term retention are critical, such as surgical education. These findings underscore the value of dFC as a robust biomarker that complements traditional performance metrics, providing a deeper understanding of motor skill learning and retention.
Dynamic directed functional connectivity as a neural biomarker for objective motor skill assessment
Feb 19, 2025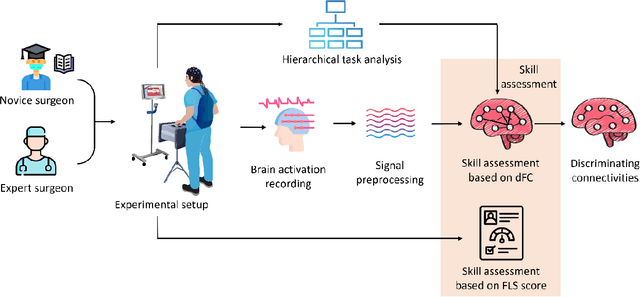
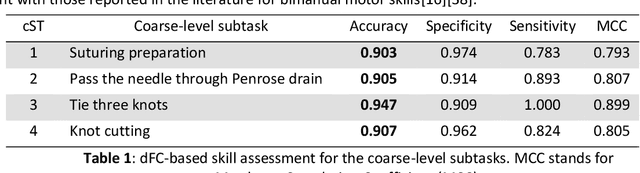
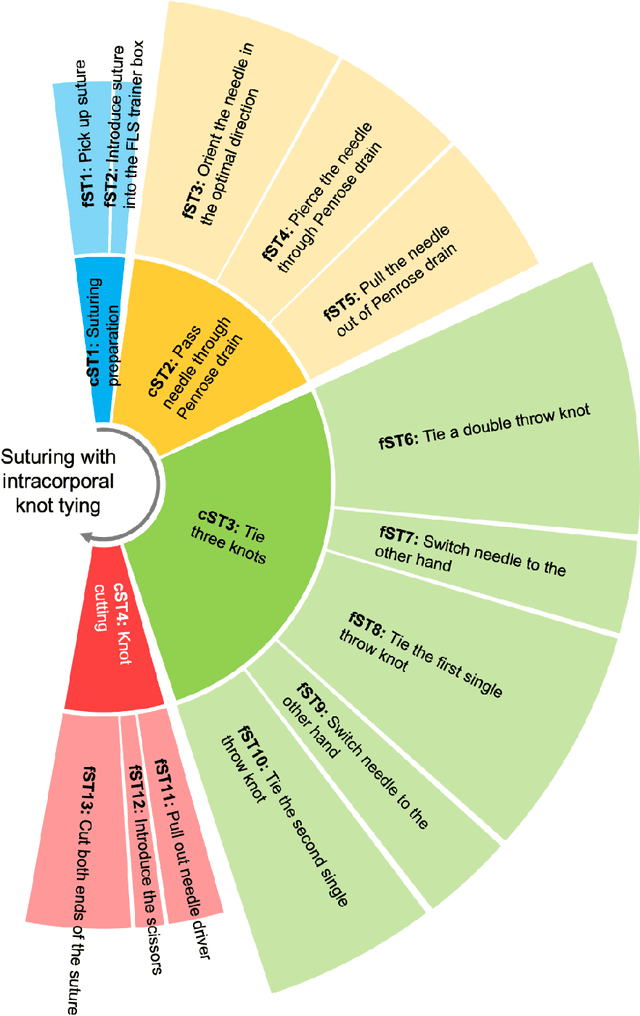
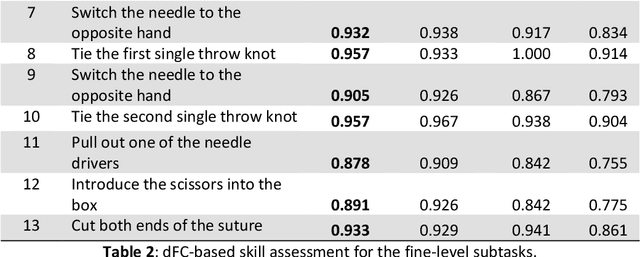
Objective motor skill assessment plays a critical role in fields such as surgery, where proficiency is vital for certification and patient safety. Existing assessment methods, however, rely heavily on subjective human judgment, which introduces bias and limits reproducibility. While recent efforts have leveraged kinematic data and neural imaging to provide more objective evaluations, these approaches often overlook the dynamic neural mechanisms that differentiate expert and novice performance. This study proposes a novel method for motor skill assessment based on dynamic directed functional connectivity (dFC) as a neural biomarker. By using electroencephalography (EEG) to capture brain dynamics and employing an attention-based Long Short-Term Memory (LSTM) model for non-linear Granger causality analysis, we compute dFC among key brain regions involved in psychomotor tasks. Coupled with hierarchical task analysis (HTA), our approach enables subtask-level evaluation of motor skills, offering detailed insights into neural coordination that underpins expert proficiency. A convolutional neural network (CNN) is then used to classify skill levels, achieving greater accuracy and specificity than established performance metrics in laparoscopic surgery. This methodology provides a reliable, objective framework for assessing motor skills, contributing to the development of tailored training protocols and enhancing the certification process.
Deep Learning for Video-Based Assessment of Endotracheal Intubation Skills
Apr 17, 2024



Endotracheal intubation (ETI) is an emergency procedure performed in civilian and combat casualty care settings to establish an airway. Objective and automated assessment of ETI skills is essential for the training and certification of healthcare providers. However, the current approach is based on manual feedback by an expert, which is subjective, time- and resource-intensive, and is prone to poor inter-rater reliability and halo effects. This work proposes a framework to evaluate ETI skills using single and multi-view videos. The framework consists of two stages. First, a 2D convolutional autoencoder (AE) and a pre-trained self-supervision network extract features from videos. Second, a 1D convolutional enhanced with a cross-view attention module takes the features from the AE as input and outputs predictions for skill evaluation. The ETI datasets were collected in two phases. In the first phase, ETI is performed by two subject cohorts: Experts and Novices. In the second phase, novice subjects perform ETI under time pressure, and the outcome is either Successful or Unsuccessful. A third dataset of videos from a single head-mounted camera for Experts and Novices is also analyzed. The study achieved an accuracy of 100% in identifying Expert/Novice trials in the initial phase. In the second phase, the model showed 85% accuracy in classifying Successful/Unsuccessful procedures. Using head-mounted cameras alone, the model showed a 96% accuracy on Expert and Novice classification while maintaining an accuracy of 85% on classifying successful and unsuccessful. In addition, GradCAMs are presented to explain the differences between Expert and Novice behavior and Successful and Unsuccessful trials. The approach offers a reliable and objective method for automated assessment of ETI skills.
Cognitive-Motor Integration in Assessing Bimanual Motor Skills
Apr 16, 2024



Accurate assessment of bimanual motor skills is essential across various professions, yet, traditional methods often rely on subjective assessments or focus solely on motor actions, overlooking the integral role of cognitive processes. This study introduces a novel approach by leveraging deep neural networks (DNNs) to analyze and integrate both cognitive decision-making and motor execution. We tested this methodology by assessing laparoscopic surgery skills within the Fundamentals of Laparoscopic Surgery program, which is a prerequisite for general surgery certification. Utilizing video capture of motor actions and non-invasive functional near-infrared spectroscopy (fNIRS) for measuring neural activations, our approach precisely classifies subjects by expertise level and predicts FLS behavioral performance scores, significantly surpassing traditional single-modality assessments.
One-shot domain adaptation in video-based assessment of surgical skills
Dec 16, 2022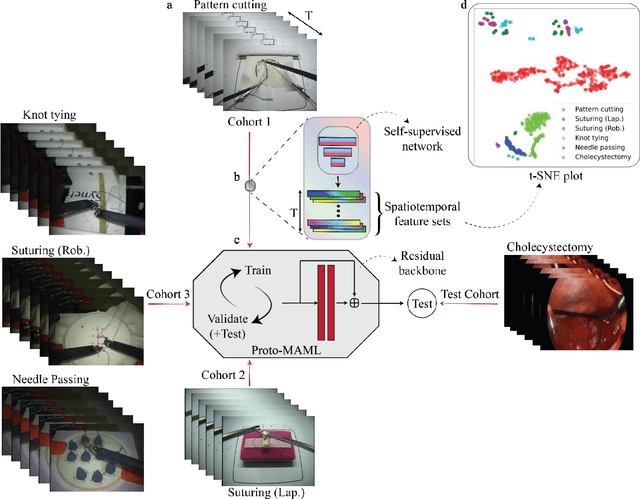
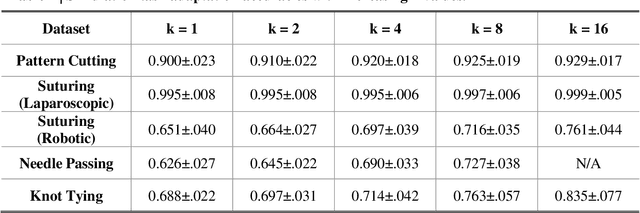
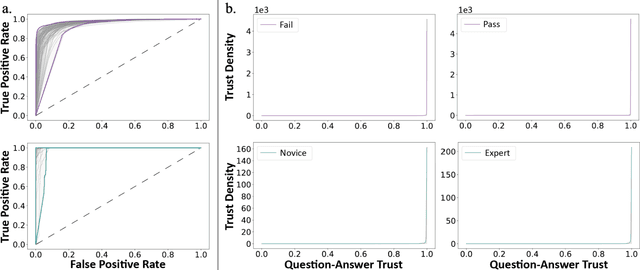
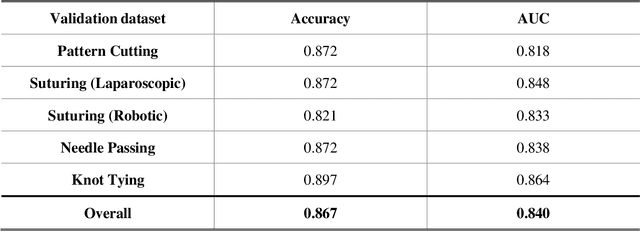
Deep Learning (DL) has achieved automatic and objective assessment of surgical skills. However, DL models are data-hungry and restricted to their training domain. This prevents them from transitioning to new tasks where data is limited. Hence, domain adaptation is crucial to implement DL in real life. Here, we propose a meta-learning model, A-VBANet, that can deliver domain-agnostic surgical skill classification via one-shot learning. We develop the A-VBANet on five laparoscopic and robotic surgical simulators. Additionally, we test it on operating room (OR) videos of laparoscopic cholecystectomy. Our model successfully adapts with accuracies up to 99.5% in one-shot and 99.9% in few-shot settings for simulated tasks and 89.7% for laparoscopic cholecystectomy. For the first time, we provide a domain-agnostic procedure for video-based assessment of surgical skills. A significant implication of this approach is that it allows the use of data from surgical simulators to assess performance in the operating room.
A deep learning model for burn depth classification using ultrasound imaging
Mar 29, 2022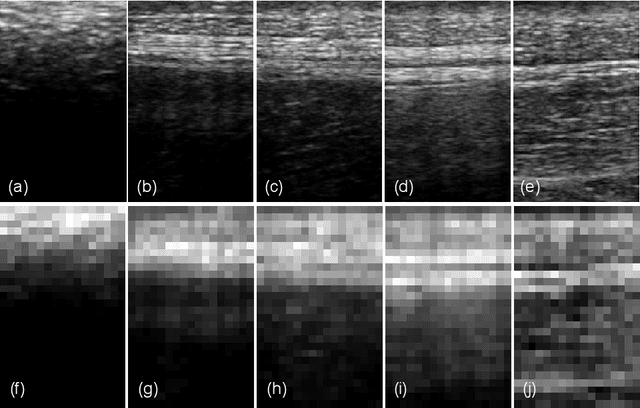
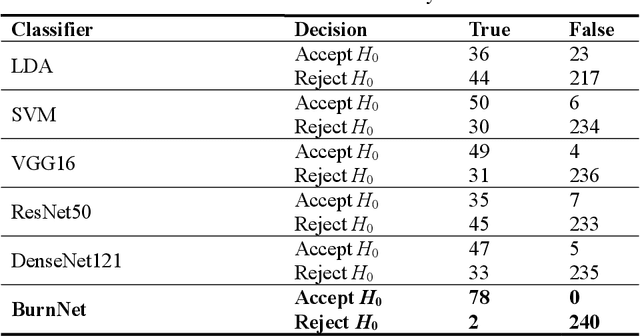
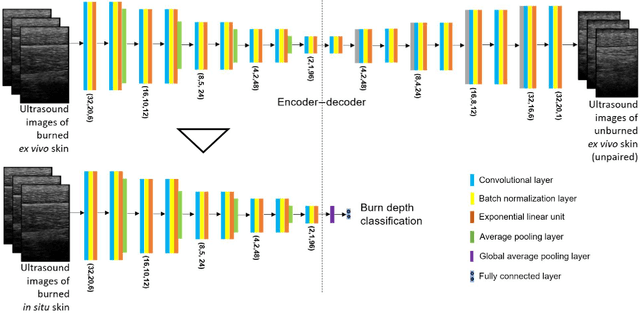
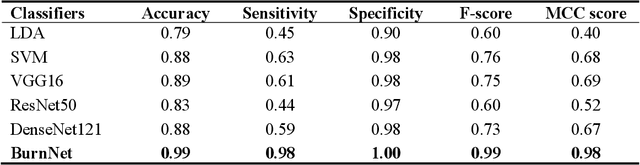
Identification of burn depth with sufficient accuracy is a challenging problem. This paper presents a deep convolutional neural network to classify burn depth based on altered tissue morphology of burned skin manifested as texture patterns in the ultrasound images. The network first learns a low-dimensional manifold of the unburned skin images using an encoder-decoder architecture that reconstructs it from ultrasound images of burned skin. The encoder is then re-trained to classify burn depths. The encoder-decoder network is trained using a dataset comprised of B-mode ultrasound images of unburned and burned ex vivo porcine skin samples. The classifier is developed using B-mode images of burned in situ skin samples obtained from freshly euthanized postmortem pigs. The performance metrics obtained from 20-fold cross-validation show that the model can identify deep-partial thickness burns, which is the most difficult to diagnose clinically, with 99% accuracy, 98% sensitivity, and 100% specificity. The diagnostic accuracy of the classifier is further illustrated by the high area under the curve values of 0.99 and 0.95, respectively, for the receiver operating characteristic and precision-recall curves. A post hoc explanation indicates that the classifier activates the discriminative textural features in the B-mode images for burn classification. The proposed model has the potential for clinical utility in assisting the clinical assessment of burn depths using a widely available clinical imaging device.
Video-based Formative and Summative Assessment of Surgical Tasks using Deep Learning
Mar 17, 2022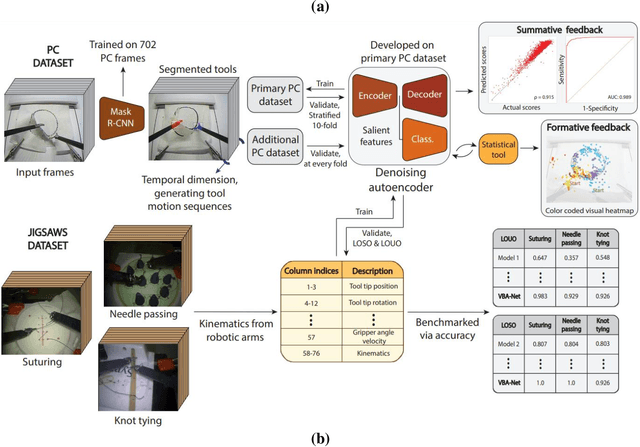
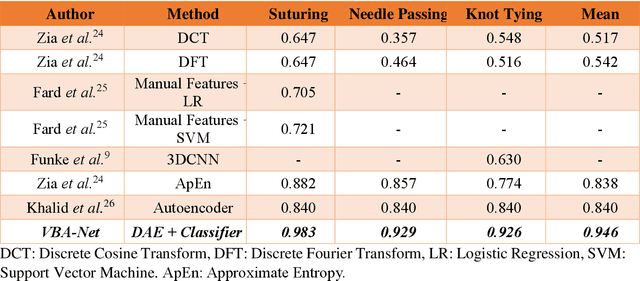
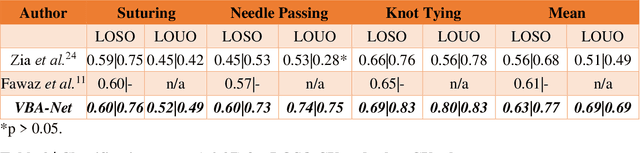
To ensure satisfactory clinical outcomes, surgical skill assessment must be objective, time-efficient, and preferentially automated - none of which is currently achievable. Video-based assessment (VBA) is being deployed in intraoperative and simulation settings to evaluate technical skill execution. However, VBA remains manually- and time-intensive and prone to subjective interpretation and poor inter-rater reliability. Herein, we propose a deep learning (DL) model that can automatically and objectively provide a high-stakes summative assessment of surgical skill execution based on video feeds and low-stakes formative assessment to guide surgical skill acquisition. Formative assessment is generated using heatmaps of visual features that correlate with surgical performance. Hence, the DL model paves the way to the quantitative and reproducible evaluation of surgical tasks from videos with the potential for broad dissemination in surgical training, certification, and credentialing.
Deep Neural Networks for the Assessment of Surgical Skills: A Systematic Review
Mar 03, 2021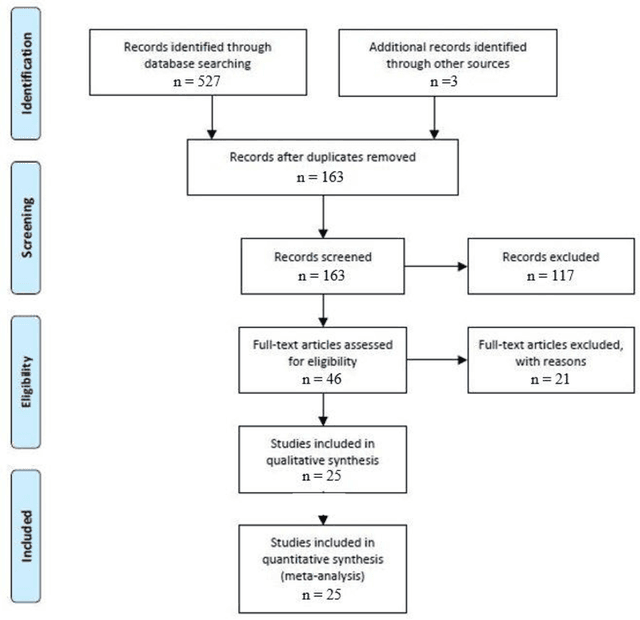
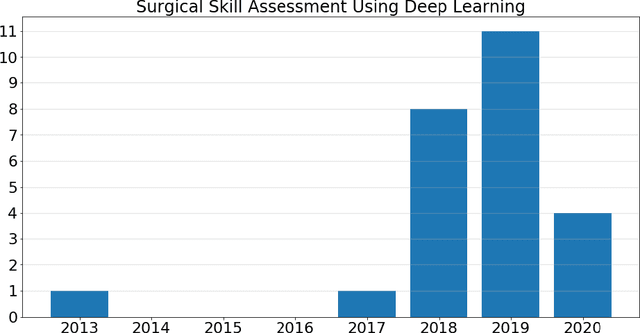
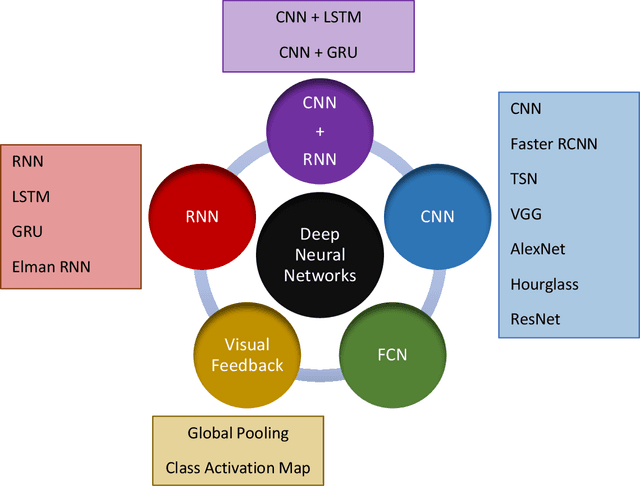
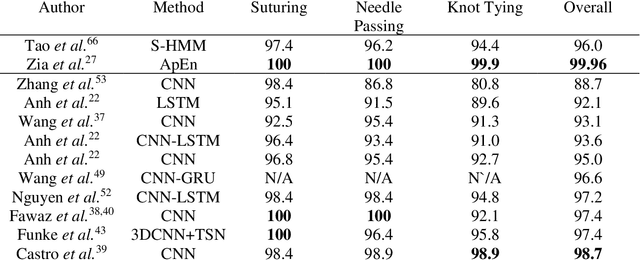
Surgical training in medical school residency programs has followed the apprenticeship model. The learning and assessment process is inherently subjective and time-consuming. Thus, there is a need for objective methods to assess surgical skills. Here, we use the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines to systematically survey the literature on the use of Deep Neural Networks for automated and objective surgical skill assessment, with a focus on kinematic data as putative markers of surgical competency. There is considerable recent interest in deep neural networks (DNN) due to the availability of powerful algorithms, multiple datasets, some of which are publicly available, as well as efficient computational hardware to train and host them. We have reviewed 530 papers, of which we selected 25 for this systematic review. Based on this review, we concluded that DNNs are powerful tools for automated, objective surgical skill assessment using both kinematic and video data. The field would benefit from large, publicly available, annotated datasets that are representative of the surgical trainee and expert demographics and multimodal data beyond kinematics and videos.