 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Look Spatial Reasoning for Dense Surgical Instrument Counting
Feb 11, 2026Accurate counting of surgical instruments in Operating Rooms (OR) is a critical prerequisite for ensuring patient safety during surgery. Despite recent progress of large visual-language models and agentic AI, accurately counting such instruments remains highly challenging, particularly in dense scenarios where instruments are tightly clustered. To address this problem, we introduce Chain-of-Look, a novel visual reasoning framework that mimics the sequential human counting process by enforcing a structured visual chain, rather than relying on classic object detection which is unordered. This visual chain guides the model to count along a coherent spatial trajectory, improving accuracy in complex scenes. To further enforce the physical plausibility of the visual chain, we introduce the neighboring loss function, which explicitly models the spatial constraints inherent to densely packed surgical instruments. We also present SurgCount-HD, a new dataset comprising 1,464 high-density surgical instrument images. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches for counting (e.g., CountGD, REC) as well as Multimodality Large Language Models (e.g., Qwen, ChatGPT) in the challenging task of dense surgical instrument counting.
InT: Self-Proposed Interventions Enable Credit Assignment in LLM Reasoning
Jan 20, 2026Outcome-reward reinforcement learning (RL) has proven effective at improving the reasoning capabilities of large language models (LLMs). However, standard RL assigns credit only at the level of the final answer, penalizing entire reasoning traces when the outcome is incorrect and uniformly reinforcing all steps when it is correct. As a result, correct intermediate steps may be discouraged in failed traces, while spurious steps may be reinforced in successful ones. We refer to this failure mode as the problem of credit assignment. While a natural remedy is to train a process reward model, accurately optimizing such models to identify corrective reasoning steps remains challenging. We introduce Intervention Training (InT), a training paradigm in which the model performs fine-grained credit assignment on its own reasoning traces by proposing short, targeted corrections that steer trajectories toward higher reward. Using reference solutions commonly available in mathematical reasoning datasets and exploiting the fact that verifying a model-generated solution is easier than generating a correct one from scratch, the model identifies the first error in its reasoning and proposes a single-step intervention to redirect the trajectory toward the correct solution. We then apply supervised fine-tuning (SFT) to the on-policy rollout up to the point of error concatenated with the intervention, localizing error to the specific step that caused failure. We show that the resulting model serves as a far better initialization for RL training. After running InT and subsequent fine-tuning with RL, we improve accuracy by nearly 14% over a 4B-parameter base model on IMO-AnswerBench, outperforming larger open-source models such as gpt-oss-20b.
LLaVA-Surg: Towards Multimodal Surgical Assistant via Structured Surgical Video Learning
Aug 15, 2024



Multimodal large language models (LLMs) have achieved notable success across various domains, while research in the medical field has largely focused on unimodal images. Meanwhile, current general-domain multimodal models for videos still lack the capabilities to understand and engage in conversations about surgical videos. One major contributing factor is the absence of datasets in the surgical field. In this paper, we create a new dataset, Surg-QA, consisting of 102,000 surgical video-instruction pairs, the largest of its kind so far. To build such a dataset, we propose a novel two-stage question-answer generation pipeline with LLM to learn surgical knowledge in a structured manner from the publicly available surgical lecture videos. The pipeline breaks down the generation process into two stages to significantly reduce the task complexity, allowing us to use a more affordable, locally deployed open-source LLM than the premium paid LLM services. It also mitigates the risk of LLM hallucinations during question-answer generation, thereby enhancing the overall quality of the generated data. We further train LLaVA-Surg, a novel vision-language conversational assistant capable of answering open-ended questions about surgical videos, on this Surg-QA dataset, and conduct comprehensive evaluations on zero-shot surgical video question-answering tasks. We show that LLaVA-Surg significantly outperforms all previous general-domain models, demonstrating exceptional multimodal conversational skills in answering open-ended questions about surgical videos. We will release our code, model, and the instruction-tuning dataset.
One-shot domain adaptation in video-based assessment of surgical skills
Dec 16, 2022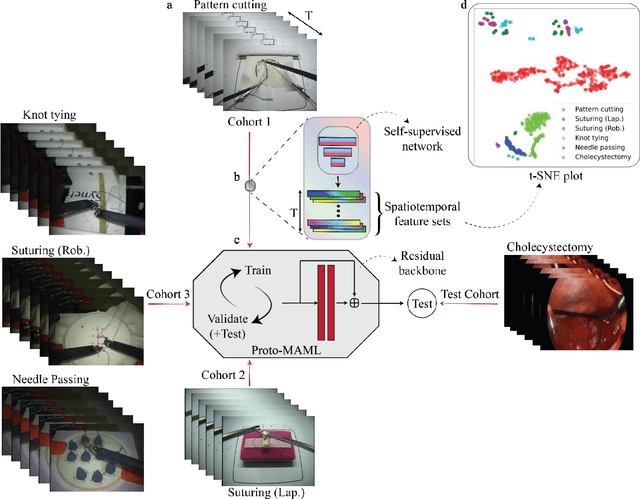
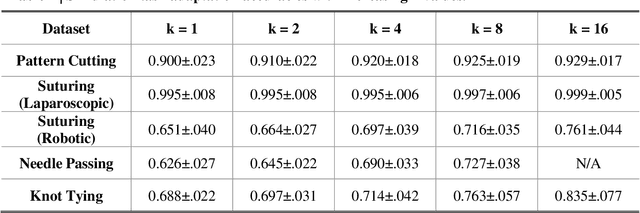
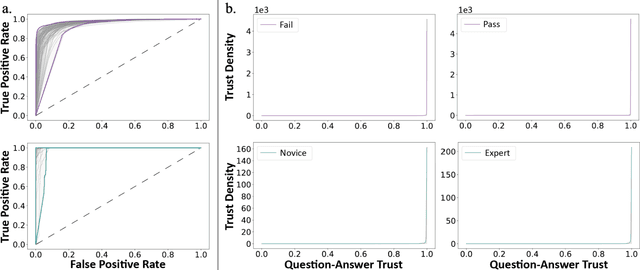
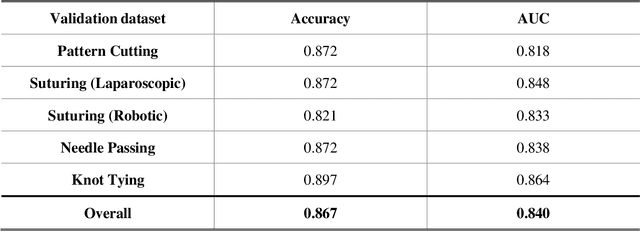
Deep Learning (DL) has achieved automatic and objective assessment of surgical skills. However, DL models are data-hungry and restricted to their training domain. This prevents them from transitioning to new tasks where data is limited. Hence, domain adaptation is crucial to implement DL in real life. Here, we propose a meta-learning model, A-VBANet, that can deliver domain-agnostic surgical skill classification via one-shot learning. We develop the A-VBANet on five laparoscopic and robotic surgical simulators. Additionally, we test it on operating room (OR) videos of laparoscopic cholecystectomy. Our model successfully adapts with accuracies up to 99.5% in one-shot and 99.9% in few-shot settings for simulated tasks and 89.7% for laparoscopic cholecystectomy. For the first time, we provide a domain-agnostic procedure for video-based assessment of surgical skills. A significant implication of this approach is that it allows the use of data from surgical simulators to assess performance in the operating room.