 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Video-Based Assessment of Endotracheal Intubation Skills
Apr 17, 2024



Endotracheal intubation (ETI) is an emergency procedure performed in civilian and combat casualty care settings to establish an airway. Objective and automated assessment of ETI skills is essential for the training and certification of healthcare providers. However, the current approach is based on manual feedback by an expert, which is subjective, time- and resource-intensive, and is prone to poor inter-rater reliability and halo effects. This work proposes a framework to evaluate ETI skills using single and multi-view videos. The framework consists of two stages. First, a 2D convolutional autoencoder (AE) and a pre-trained self-supervision network extract features from videos. Second, a 1D convolutional enhanced with a cross-view attention module takes the features from the AE as input and outputs predictions for skill evaluation. The ETI datasets were collected in two phases. In the first phase, ETI is performed by two subject cohorts: Experts and Novices. In the second phase, novice subjects perform ETI under time pressure, and the outcome is either Successful or Unsuccessful. A third dataset of videos from a single head-mounted camera for Experts and Novices is also analyzed. The study achieved an accuracy of 100% in identifying Expert/Novice trials in the initial phase. In the second phase, the model showed 85% accuracy in classifying Successful/Unsuccessful procedures. Using head-mounted cameras alone, the model showed a 96% accuracy on Expert and Novice classification while maintaining an accuracy of 85% on classifying successful and unsuccessful. In addition, GradCAMs are presented to explain the differences between Expert and Novice behavior and Successful and Unsuccessful trials. The approach offers a reliable and objective method for automated assessment of ETI skills.
Cognitive-Motor Integration in Assessing Bimanual Motor Skills
Apr 16, 2024



Accurate assessment of bimanual motor skills is essential across various professions, yet, traditional methods often rely on subjective assessments or focus solely on motor actions, overlooking the integral role of cognitive processes. This study introduces a novel approach by leveraging deep neural networks (DNNs) to analyze and integrate both cognitive decision-making and motor execution. We tested this methodology by assessing laparoscopic surgery skills within the Fundamentals of Laparoscopic Surgery program, which is a prerequisite for general surgery certification. Utilizing video capture of motor actions and non-invasive functional near-infrared spectroscopy (fNIRS) for measuring neural activations, our approach precisely classifies subjects by expertise level and predicts FLS behavioral performance scores, significantly surpassing traditional single-modality assessments.
One-shot domain adaptation in video-based assessment of surgical skills
Dec 16, 2022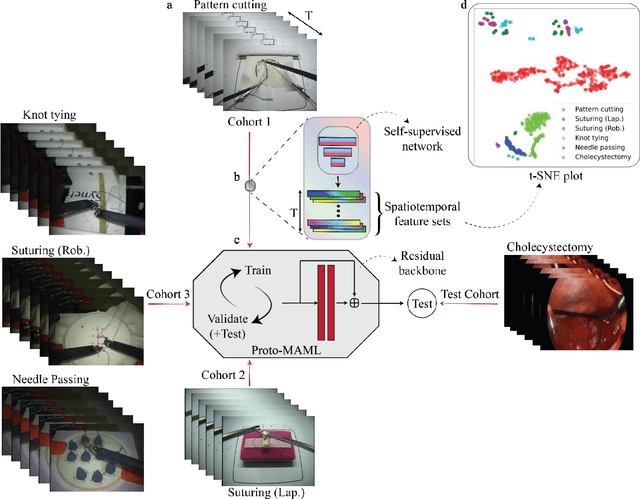
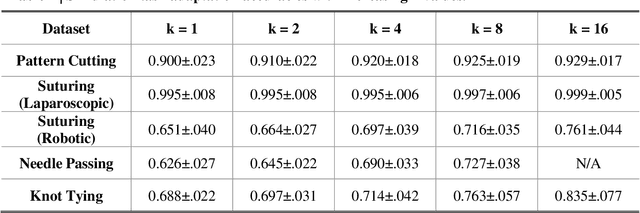
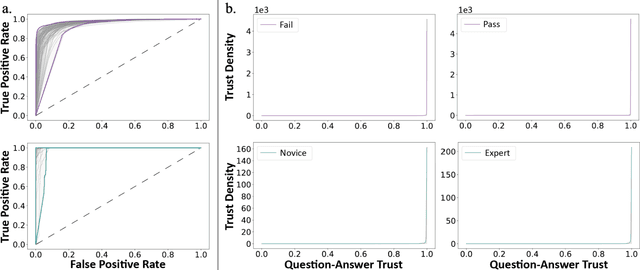
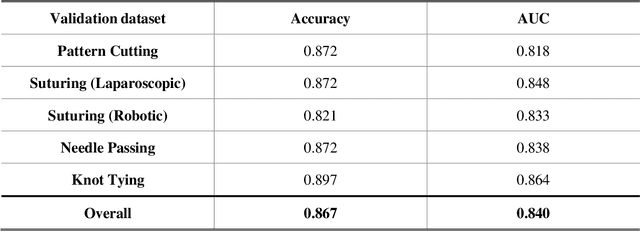
Deep Learning (DL) has achieved automatic and objective assessment of surgical skills. However, DL models are data-hungry and restricted to their training domain. This prevents them from transitioning to new tasks where data is limited. Hence, domain adaptation is crucial to implement DL in real life. Here, we propose a meta-learning model, A-VBANet, that can deliver domain-agnostic surgical skill classification via one-shot learning. We develop the A-VBANet on five laparoscopic and robotic surgical simulators. Additionally, we test it on operating room (OR) videos of laparoscopic cholecystectomy. Our model successfully adapts with accuracies up to 99.5% in one-shot and 99.9% in few-shot settings for simulated tasks and 89.7% for laparoscopic cholecystectomy. For the first time, we provide a domain-agnostic procedure for video-based assessment of surgical skills. A significant implication of this approach is that it allows the use of data from surgical simulators to assess performance in the operating room.
Video-based Formative and Summative Assessment of Surgical Tasks using Deep Learning
Mar 17, 2022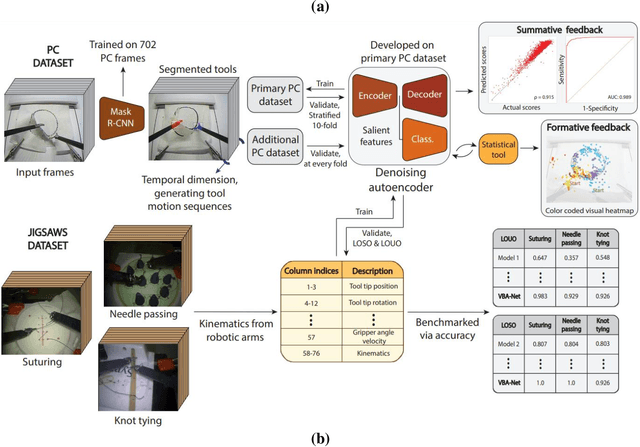
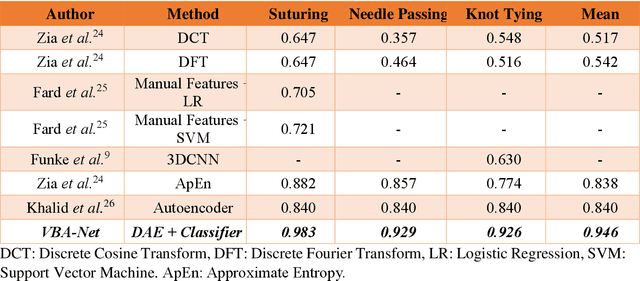
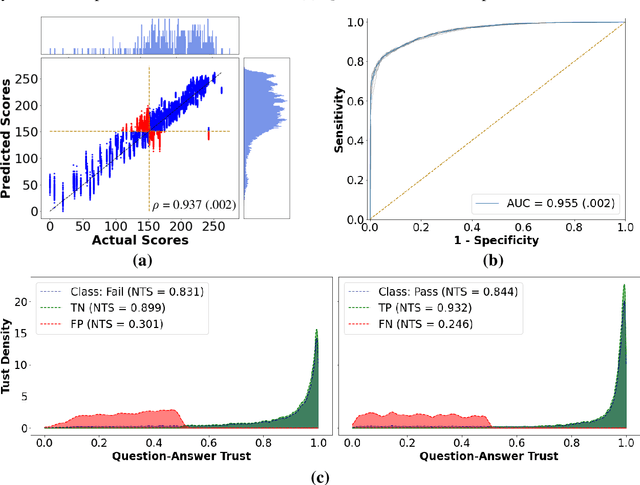
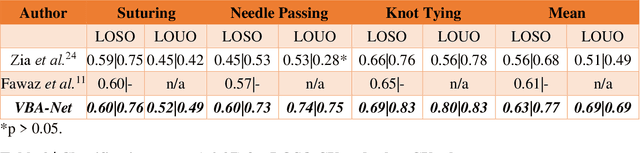
To ensure satisfactory clinical outcomes, surgical skill assessment must be objective, time-efficient, and preferentially automated - none of which is currently achievable. Video-based assessment (VBA) is being deployed in intraoperative and simulation settings to evaluate technical skill execution. However, VBA remains manually- and time-intensive and prone to subjective interpretation and poor inter-rater reliability. Herein, we propose a deep learning (DL) model that can automatically and objectively provide a high-stakes summative assessment of surgical skill execution based on video feeds and low-stakes formative assessment to guide surgical skill acquisition. Formative assessment is generated using heatmaps of visual features that correlate with surgical performance. Hence, the DL model paves the way to the quantitative and reproducible evaluation of surgical tasks from videos with the potential for broad dissemination in surgical training, certification, and credentialing.
Deep Neural Networks for the Assessment of Surgical Skills: A Systematic Review
Mar 03, 2021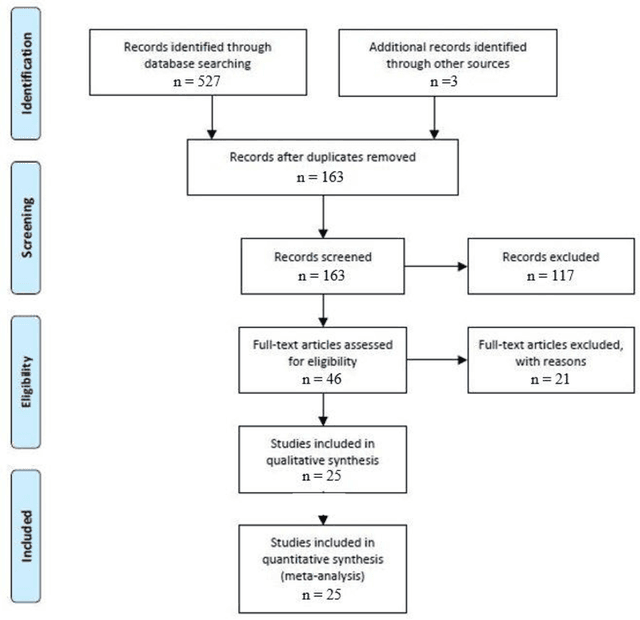
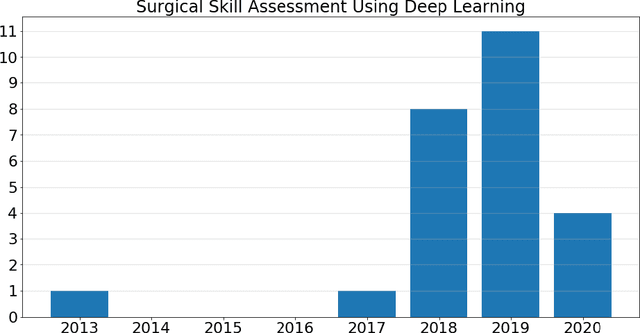
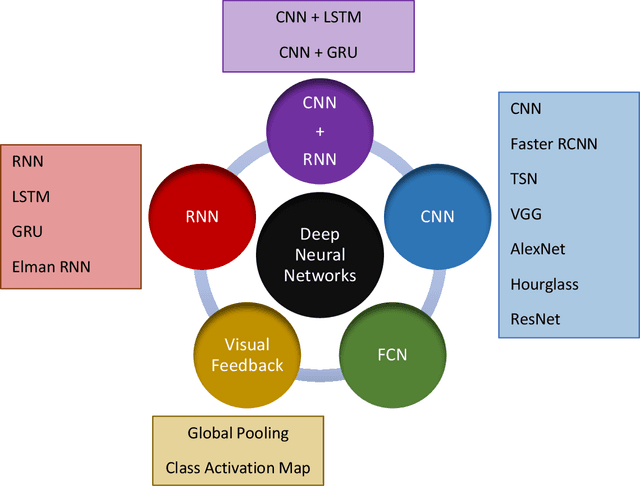
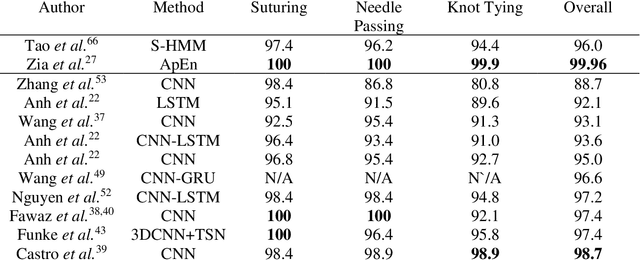
Surgical training in medical school residency programs has followed the apprenticeship model. The learning and assessment process is inherently subjective and time-consuming. Thus, there is a need for objective methods to assess surgical skills. Here, we use the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines to systematically survey the literature on the use of Deep Neural Networks for automated and objective surgical skill assessment, with a focus on kinematic data as putative markers of surgical competency. There is considerable recent interest in deep neural networks (DNN) due to the availability of powerful algorithms, multiple datasets, some of which are publicly available, as well as efficient computational hardware to train and host them. We have reviewed 530 papers, of which we selected 25 for this systematic review. Based on this review, we concluded that DNNs are powerful tools for automated, objective surgical skill assessment using both kinematic and video data. The field would benefit from large, publicly available, annotated datasets that are representative of the surgical trainee and expert demographics and multimodal data beyond kinematics and videos.