 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning on Heterogeneous, Edge, and Quantum Hardware for Particle Physics (ML-HEQUPP)
Feb 24, 2026The next generation of particle physics experiments will face a new era of challenges in data acquisition, due to unprecedented data rates and volumes along with extreme environments and operational constraints. Harnessing this data for scientific discovery demands real-time inference and decision-making, intelligent data reduction, and efficient processing architectures beyond current capabilities. Crucial to the success of this experimental paradigm are several emerging technologies, such as artificial intelligence and machine learning (AI/ML) and silicon microelectronics, and the advent of quantum algorithms and processing. Their intersection includes areas of research such as low-power and low-latency devices for edge computing, heterogeneous accelerator systems, reconfigurable hardware, novel codesign and synthesis strategies, readout for cryogenic or high-radiation environments, and analog computing. This white paper presents a community-driven vision to identify and prioritize research and development opportunities in hardware-based ML systems and corresponding physics applications, contributing towards a successful transition to the new data frontier of fundamental science.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Unsupervised Framework for Evaluating and Explaining Structural Node Embeddings of Graphs
Jun 19, 2023



An embedding is a mapping from a set of nodes of a network into a real vector space. Embeddings can have various aims like capturing the underlying graph topology and structure, node-to-node relationship, or other relevant information about the graph, its subgraphs or nodes themselves. A practical challenge with using embeddings is that there are many available variants to choose from. Selecting a small set of most promising embeddings from the long list of possible options for a given task is challenging and often requires domain expertise. Embeddings can be categorized into two main types: classical embeddings and structural embeddings. Classical embeddings focus on learning both local and global proximity of nodes, while structural embeddings learn information specifically about the local structure of nodes' neighbourhood. For classical node embeddings there exists a framework which helps data scientists to identify (in an unsupervised way) a few embeddings that are worth further investigation. Unfortunately, no such framework exists for structural embeddings. In this paper we propose a framework for unsupervised ranking of structural graph embeddings. The proposed framework, apart from assigning an aggregate quality score for a structural embedding, additionally gives a data scientist insights into properties of this embedding. It produces information which predefined node features the embedding learns, how well it learns them, and which dimensions in the embedded space represent the predefined node features. Using this information the user gets a level of explainability to an otherwise complex black-box embedding algorithm.
Quantized Gromov-Wasserstein
May 04, 2021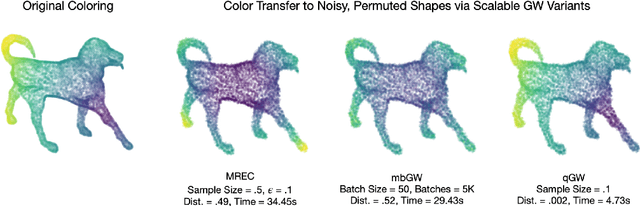
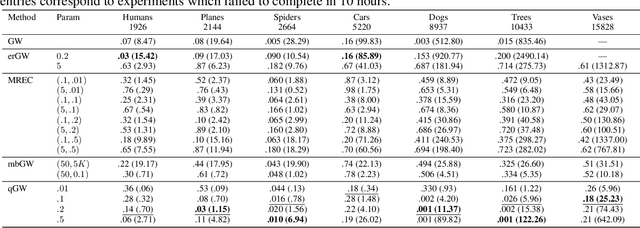

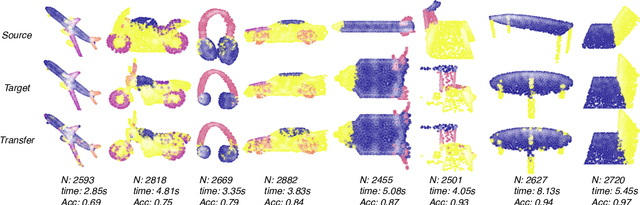
The Gromov-Wasserstein (GW) framework adapts ideas from optimal transport to allow for the comparison of probability distributions defined on different metric spaces. Scalable computation of GW distances and associated matchings on graphs and point clouds have recently been made possible by state-of-the-art algorithms such as S-GWL and MREC. Each of these algorithmic breakthroughs relies on decomposing the underlying spaces into parts and performing matchings on these parts, adding recursion as needed. While very successful in practice, theoretical guarantees on such methods are limited. Inspired by recent advances in the theory of quantization for metric measure spaces, we define Quantized Gromov Wasserstein (qGW): a metric that treats parts as fundamental objects and fits into a hierarchy of theoretical upper bounds for the GW problem. This formulation motivates a new algorithm for approximating optimal GW matchings which yields algorithmic speedups and reductions in memory complexity. Consequently, we are able to go beyond outperforming state-of-the-art and apply GW matching at scales that are an order of magnitude larger than in the existing literature, including datasets containing over 1M points.
Deep Neural Networks for the Assessment of Surgical Skills: A Systematic Review
Mar 03, 2021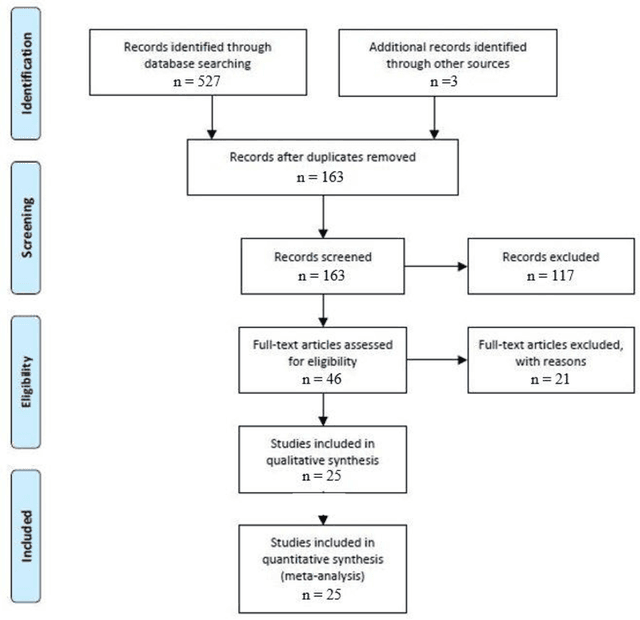
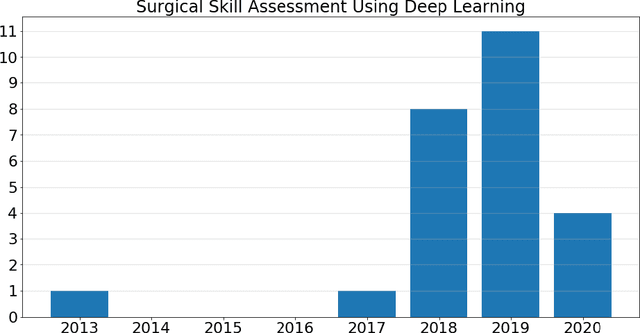
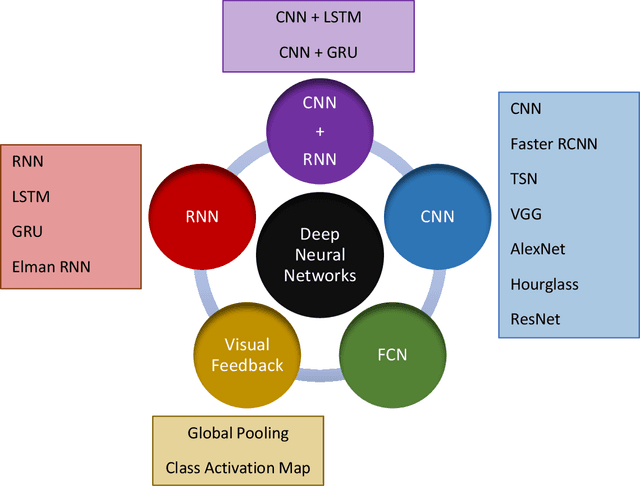
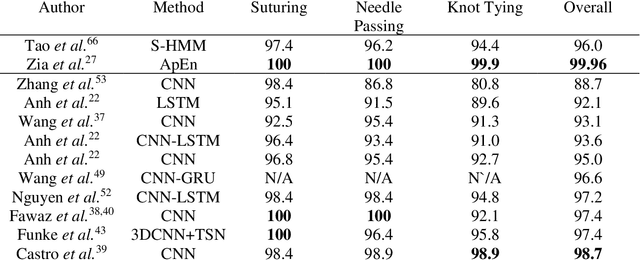
Surgical training in medical school residency programs has followed the apprenticeship model. The learning and assessment process is inherently subjective and time-consuming. Thus, there is a need for objective methods to assess surgical skills. Here, we use the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines to systematically survey the literature on the use of Deep Neural Networks for automated and objective surgical skill assessment, with a focus on kinematic data as putative markers of surgical competency. There is considerable recent interest in deep neural networks (DNN) due to the availability of powerful algorithms, multiple datasets, some of which are publicly available, as well as efficient computational hardware to train and host them. We have reviewed 530 papers, of which we selected 25 for this systematic review. Based on this review, we concluded that DNNs are powerful tools for automated, objective surgical skill assessment using both kinematic and video data. The field would benefit from large, publicly available, annotated datasets that are representative of the surgical trainee and expert demographics and multimodal data beyond kinematics and videos.
Backdoor Embedding in Convolutional Neural Network Models via Invisible Perturbation
Aug 30, 2018
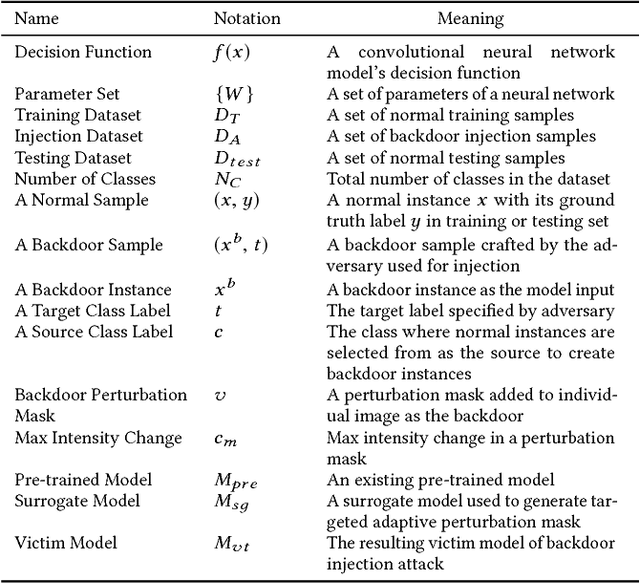
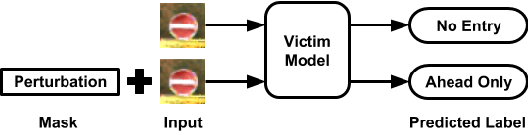
Deep learning models have consistently outperformed traditional machine learning models in various classification tasks, including image classification. As such, they have become increasingly prevalent in many real world applications including those where security is of great concern. Such popularity, however, may attract attackers to exploit the vulnerabilities of the deployed deep learning models and launch attacks against security-sensitive applications. In this paper, we focus on a specific type of data poisoning attack, which we refer to as a {\em backdoor injection attack}. The main goal of the adversary performing such attack is to generate and inject a backdoor into a deep learning model that can be triggered to recognize certain embedded patterns with a target label of the attacker's choice. Additionally, a backdoor injection attack should occur in a stealthy manner, without undermining the efficacy of the victim model. Specifically, we propose two approaches for generating a backdoor that is hardly perceptible yet effective in poisoning the model. We consider two attack settings, with backdoor injection carried out either before model training or during model updating. We carry out extensive experimental evaluations under various assumptions on the adversary model, and demonstrate that such attacks can be effective and achieve a high attack success rate (above $90\%$) at a small cost of model accuracy loss (below $1\%$) with a small injection rate (around $1\%$), even under the weakest assumption wherein the adversary has no knowledge either of the original training data or the classifier model.
Learned Iterative Decoding for Lossy Image Compression Systems
Mar 18, 2018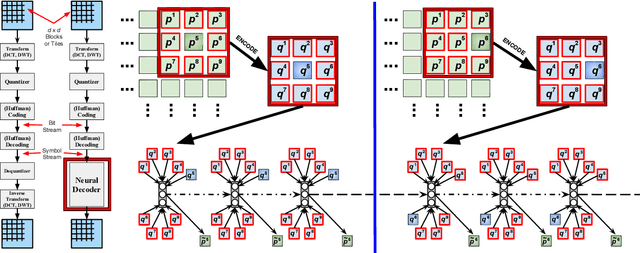

For lossy image compression systems, we develop an algorithm called iterative refinement, to improve the decoder's reconstruction compared with standard decoding techniques. Specifically, we propose a recurrent neural network approach for nonlinear, iterative decoding. Our neural decoder, which can work with any encoder, employs self-connected memory units that make use of both causal and non-causal spatial context information to progressively reduce reconstruction error over a fixed number of steps. We experiment with variations of our proposed estimator and obtain as much as a 0.8921 decibel (dB) gain over the standard JPEG algorithm and a 0.5848 dB gain over a state-of-the-art neural compression model.