 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Task Shield: Enforcing Task Alignment to Defend Against Indirect Prompt Injection in LLM Agents
Dec 21, 2024Large Language Model (LLM) agents are increasingly being deployed as conversational assistants capable of performing complex real-world tasks through tool integration. This enhanced ability to interact with external systems and process various data sources, while powerful, introduces significant security vulnerabilities. In particular, indirect prompt injection attacks pose a critical threat, where malicious instructions embedded within external data sources can manipulate agents to deviate from user intentions. While existing defenses based on rule constraints, source spotlighting, and authentication protocols show promise, they struggle to maintain robust security while preserving task functionality. We propose a novel and orthogonal perspective that reframes agent security from preventing harmful actions to ensuring task alignment, requiring every agent action to serve user objectives. Based on this insight, we develop Task Shield, a test-time defense mechanism that systematically verifies whether each instruction and tool call contributes to user-specified goals. Through experiments on the AgentDojo benchmark, we demonstrate that Task Shield reduces attack success rates (2.07\%) while maintaining high task utility (69.79\%) on GPT-4o.
RoCourseNet: Distributionally Robust Training of a Prediction Aware Recourse Model
Jun 01, 2022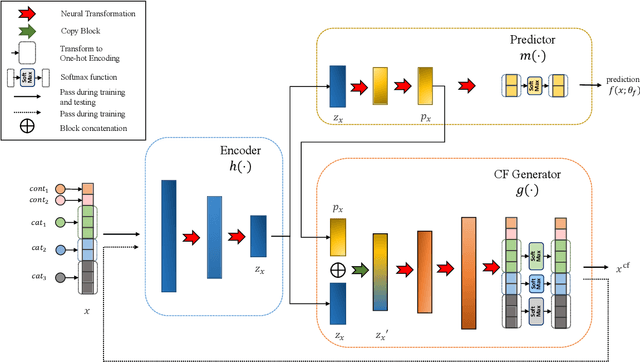
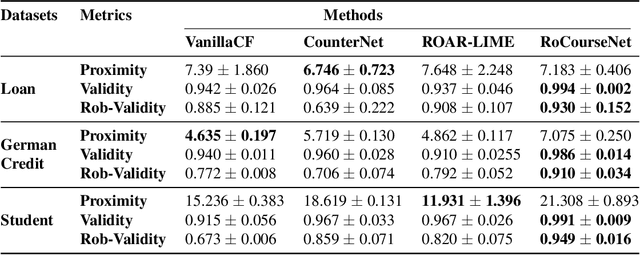
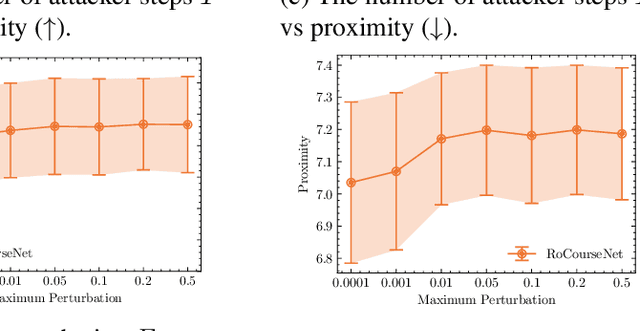
Counterfactual (CF) explanations for machine learning (ML) models are preferred by end-users, as they explain the predictions of ML models by providing a recourse case to individuals who are adversely impacted by predicted outcomes. Existing CF explanation methods generate recourses under the assumption that the underlying target ML model remains stationary over time. However, due to commonly occurring distributional shifts in training data, ML models constantly get updated in practice, which might render previously generated recourses invalid and diminish end-users trust in our algorithmic framework. To address this problem, we propose RoCourseNet, a training framework that jointly optimizes for predictions and robust recourses to future data shifts. We have three main contributions: (i) We propose a novel virtual data shift (VDS) algorithm to find worst-case shifted ML models by explicitly considering the worst-case data shift in the training dataset. (ii) We leverage adversarial training to solve a novel tri-level optimization problem inside RoCourseNet, which simultaneously generates predictions and corresponding robust recourses. (iii) Finally, we evaluate RoCourseNet's performance on three real-world datasets and show that RoCourseNet outperforms state-of-the-art baselines by 10% in generating robust CF explanations.
Automated Detection of Doxing on Twitter
Feb 02, 2022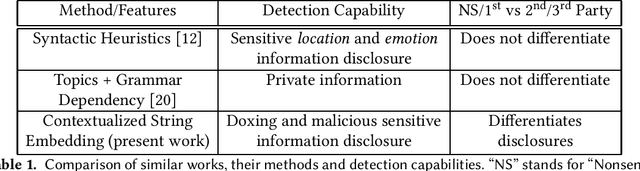
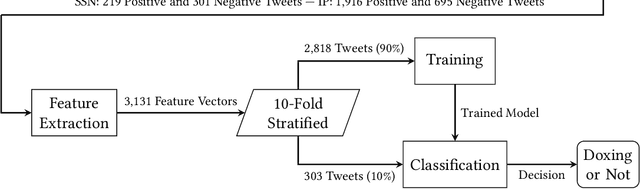
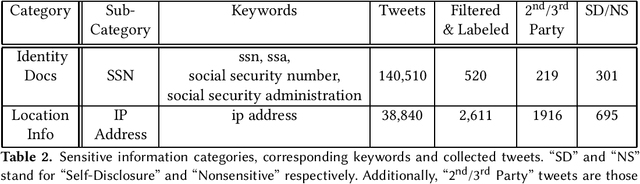
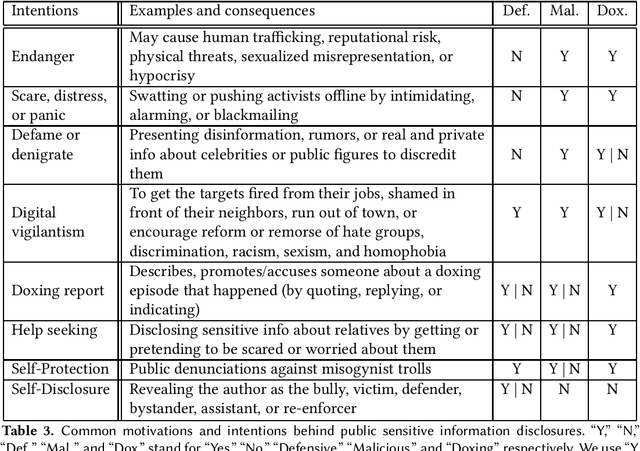
Doxing refers to the practice of disclosing sensitive personal information about a person without their consent. This form of cyberbullying is an unpleasant and sometimes dangerous phenomenon for online social networks. Although prior work exists on automated identification of other types of cyberbullying, a need exists for methods capable of detecting doxing on Twitter specifically. We propose and evaluate a set of approaches for automatically detecting second- and third-party disclosures on Twitter of sensitive private information, a subset of which constitutes doxing. We summarize our findings of common intentions behind doxing episodes and compare nine different approaches for automated detection based on string-matching and one-hot encoded heuristics, as well as word and contextualized string embedding representations of tweets. We identify an approach providing 96.86% accuracy and 97.37% recall using contextualized string embeddings and conclude by discussing the practicality of our proposed methods.
A Longitudinal Dataset of Twitter ISIS Users
Feb 02, 2022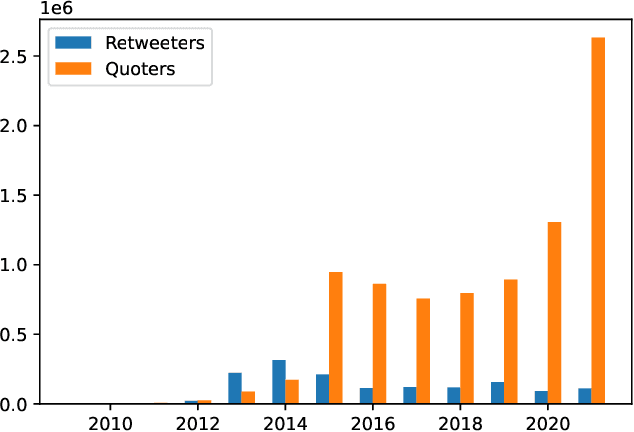

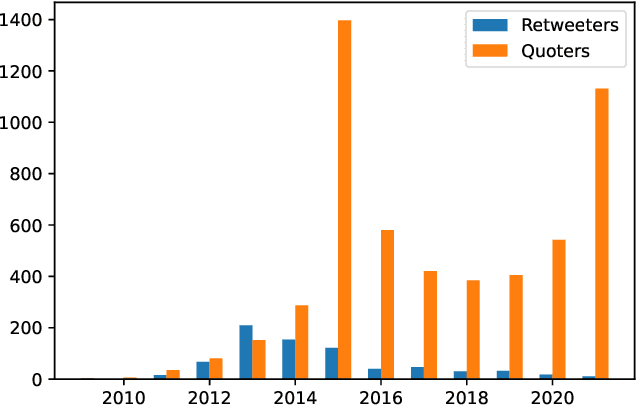

We present a large longitudinal dataset of tweets from two sets of users that are suspected to be affiliated with ISIS. These sets of users are identified based on a prior study and a campaign aimed at shutting down ISIS Twitter accounts. These users have engaged with known ISIS accounts at least once during 2014-2015 and are still active as of 2021. Some of them have directly supported the ISIS users and their tweets by retweeting them, and some of the users that have quoted tweets of ISIS, have uncertain connections to ISIS seed accounts. This study and the dataset represent a unique approach to analyzing ISIS data. Although much research exists on ISIS online activities, few studies have focused on individual accounts. Our approach to validating accounts as well as developing a framework for differentiating accounts' functionality (e.g., propaganda versus operational planning) offers a foundation for future research. We perform some descriptive statistics and preliminary analyses on our collected data to provide deeper insight and highlight the significance and practicality of such analyses. We further discuss several cross-disciplinary potential use cases and research directions.
A Synthetic Prediction Market for Estimating Confidence in Published Work
Dec 23, 2021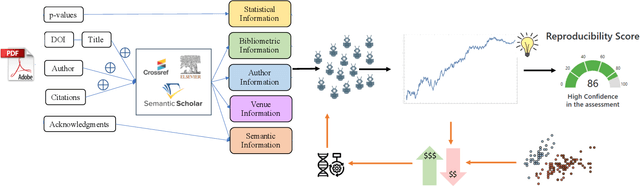
Explainably estimating confidence in published scholarly work offers opportunity for faster and more robust scientific progress. We develop a synthetic prediction market to assess the credibility of published claims in the social and behavioral sciences literature. We demonstrate our system and detail our findings using a collection of known replication projects. We suggest that this work lays the foundation for a research agenda that creatively uses AI for peer review.
Backdoor Embedding in Convolutional Neural Network Models via Invisible Perturbation
Aug 30, 2018
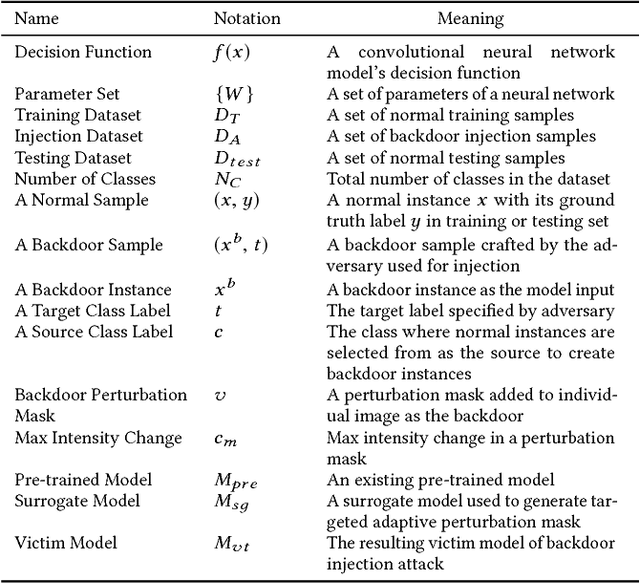
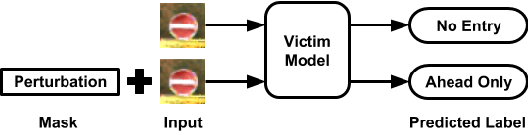
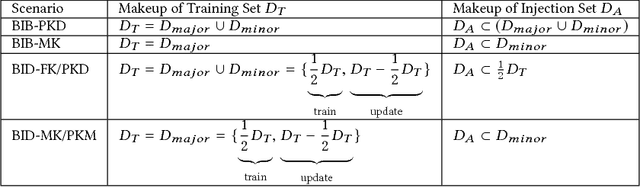
Deep learning models have consistently outperformed traditional machine learning models in various classification tasks, including image classification. As such, they have become increasingly prevalent in many real world applications including those where security is of great concern. Such popularity, however, may attract attackers to exploit the vulnerabilities of the deployed deep learning models and launch attacks against security-sensitive applications. In this paper, we focus on a specific type of data poisoning attack, which we refer to as a {\em backdoor injection attack}. The main goal of the adversary performing such attack is to generate and inject a backdoor into a deep learning model that can be triggered to recognize certain embedded patterns with a target label of the attacker's choice. Additionally, a backdoor injection attack should occur in a stealthy manner, without undermining the efficacy of the victim model. Specifically, we propose two approaches for generating a backdoor that is hardly perceptible yet effective in poisoning the model. We consider two attack settings, with backdoor injection carried out either before model training or during model updating. We carry out extensive experimental evaluations under various assumptions on the adversary model, and demonstrate that such attacks can be effective and achieve a high attack success rate (above $90\%$) at a small cost of model accuracy loss (below $1\%$) with a small injection rate (around $1\%$), even under the weakest assumption wherein the adversary has no knowledge either of the original training data or the classifier model.