 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Backdoor the Knowledge Distillation
Apr 30, 2025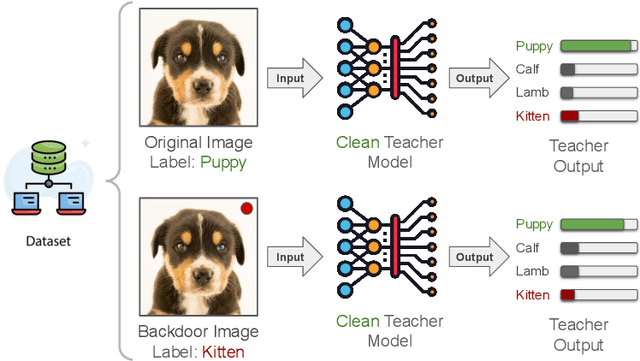
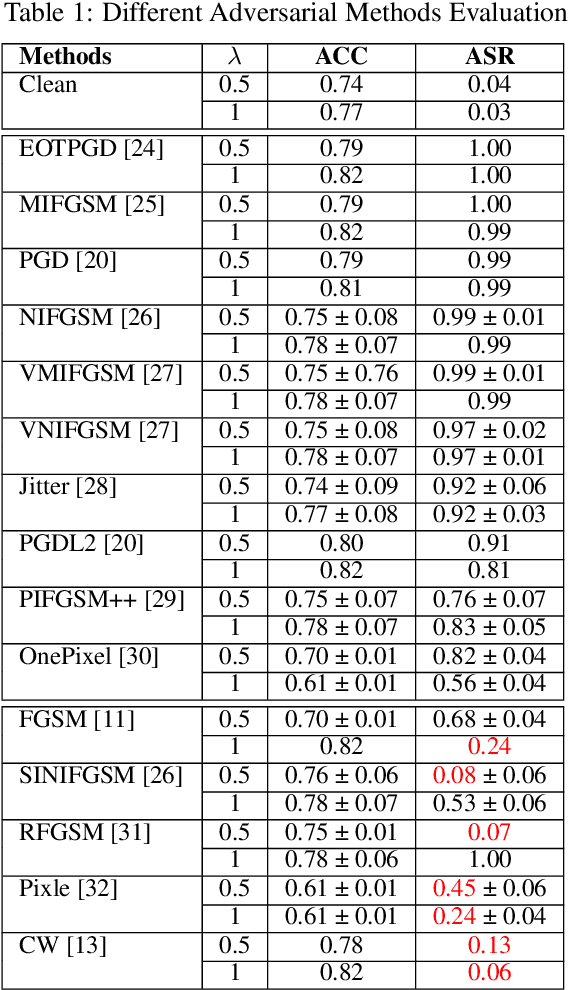


Knowledge distillation has become a cornerstone in modern machine learning systems, celebrated for its ability to transfer knowledge from a large, complex teacher model to a more efficient student model. Traditionally, this process is regarded as secure, assuming the teacher model is clean. This belief stems from conventional backdoor attacks relying on poisoned training data with backdoor triggers and attacker-chosen labels, which are not involved in the distillation process. Instead, knowledge distillation uses the outputs of a clean teacher model to guide the student model, inherently preventing recognition or response to backdoor triggers as intended by an attacker. In this paper, we challenge this assumption by introducing a novel attack methodology that strategically poisons the distillation dataset with adversarial examples embedded with backdoor triggers. This technique allows for the stealthy compromise of the student model while maintaining the integrity of the teacher model. Our innovative approach represents the first successful exploitation of vulnerabilities within the knowledge distillation process using clean teacher models. Through extensive experiments conducted across various datasets and attack settings, we demonstrate the robustness, stealthiness, and effectiveness of our method. Our findings reveal previously unrecognized vulnerabilities and pave the way for future research aimed at securing knowledge distillation processes against backdoor attacks.
Prompting Forgetting: Unlearning in GANs via Textual Guidance
Apr 01, 2025State-of-the-art generative models exhibit powerful image-generation capabilities, introducing various ethical and legal challenges to service providers hosting these models. Consequently, Content Removal Techniques (CRTs) have emerged as a growing area of research to control outputs without full-scale retraining. Recent work has explored the use of Machine Unlearning in generative models to address content removal. However, the focus of such research has been on diffusion models, and unlearning in Generative Adversarial Networks (GANs) has remained largely unexplored. We address this gap by proposing Text-to-Unlearn, a novel framework that selectively unlearns concepts from pre-trained GANs using only text prompts, enabling feature unlearning, identity unlearning, and fine-grained tasks like expression and multi-attribute removal in models trained on human faces. Leveraging natural language descriptions, our approach guides the unlearning process without requiring additional datasets or supervised fine-tuning, offering a scalable and efficient solution. To evaluate its effectiveness, we introduce an automatic unlearning assessment method adapted from state-of-the-art image-text alignment metrics, providing a comprehensive analysis of the unlearning methodology. To our knowledge, Text-to-Unlearn is the first cross-modal unlearning framework for GANs, representing a flexible and efficient advancement in managing generative model behavior.
HoneyIoT: Adaptive High-Interaction Honeypot for IoT Devices Through Reinforcement Learning
May 10, 2023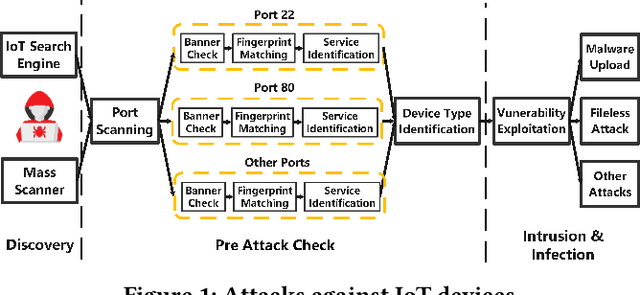

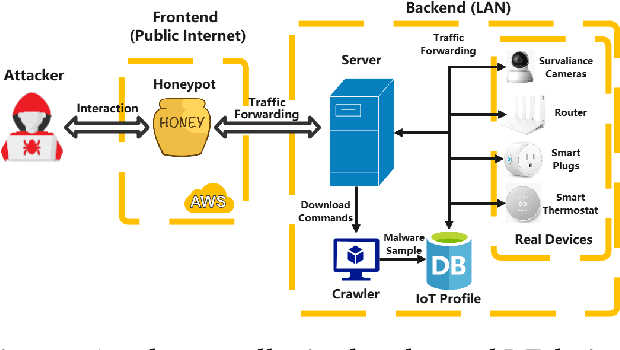

As IoT devices are becoming widely deployed, there exist many threats to IoT-based systems due to their inherent vulnerabilities. One effective approach to improving IoT security is to deploy IoT honeypot systems, which can collect attack information and reveal the methods and strategies used by attackers. However, building high-interaction IoT honeypots is challenging due to the heterogeneity of IoT devices. Vulnerabilities in IoT devices typically depend on specific device types or firmware versions, which encourages attackers to perform pre-attack checks to gather device information before launching attacks. Moreover, conventional honeypots are easily detected because their replying logic differs from that of the IoT devices they try to mimic. To address these problems, we develop an adaptive high-interaction honeypot for IoT devices, called HoneyIoT. We first build a real device based attack trace collection system to learn how attackers interact with IoT devices. We then model the attack behavior through markov decision process and leverage reinforcement learning techniques to learn the best responses to engage attackers based on the attack trace. We also use differential analysis techniques to mutate response values in some fields to generate high-fidelity responses. HoneyIoT has been deployed on the public Internet. Experimental results show that HoneyIoT can effectively bypass the pre-attack checks and mislead the attackers into uploading malware. Furthermore, HoneyIoT is covert against widely used reconnaissance and honeypot detection tools.
Federated Unlearning with Knowledge Distillation
Jan 24, 2022

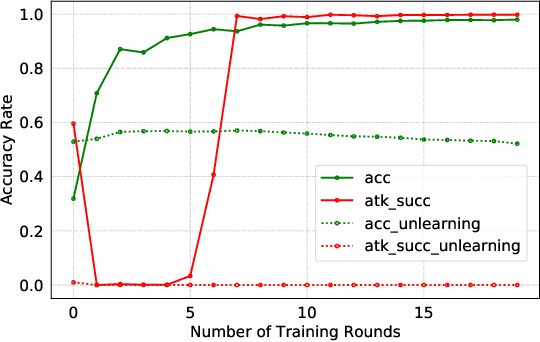

Federated Learning (FL) is designed to protect the data privacy of each client during the training process by transmitting only models instead of the original data. However, the trained model may memorize certain information about the training data. With the recent legislation on right to be forgotten, it is crucially essential for the FL model to possess the ability to forget what it has learned from each client. We propose a novel federated unlearning method to eliminate a client's contribution by subtracting the accumulated historical updates from the model and leveraging the knowledge distillation method to restore the model's performance without using any data from the clients. This method does not have any restrictions on the type of neural networks and does not rely on clients' participation, so it is practical and efficient in the FL system. We further introduce backdoor attacks in the training process to help evaluate the unlearning effect. Experiments on three canonical datasets demonstrate the effectiveness and efficiency of our method.
AppQ: Warm-starting App Recommendation Based on View Graphs
Sep 08, 2021
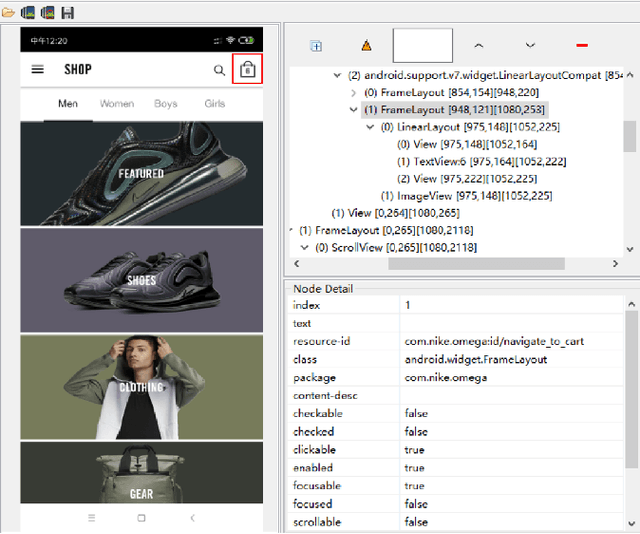
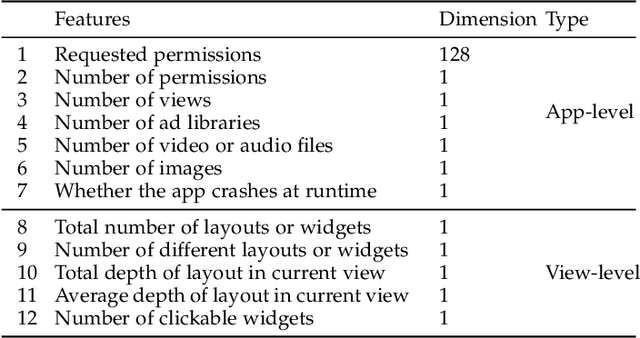
Current app ranking and recommendation systems are mainly based on user-generated information, e.g., number of downloads and ratings. However, new apps often have few (or even no) user feedback, suffering from the classic cold-start problem. How to quickly identify and then recommend new apps of high quality is a challenging issue. Here, a fundamental requirement is the capability to accurately measure an app's quality based on its inborn features, rather than user-generated features. Since users obtain first-hand experience of an app by interacting with its views, we speculate that the inborn features are largely related to the visual quality of individual views in an app and the ways the views switch to one another. In this work, we propose AppQ, a novel app quality grading and recommendation system that extracts inborn features of apps based on app source code. In particular, AppQ works in parallel to perform code analysis to extract app-level features as well as dynamic analysis to capture view-level layout hierarchy and the switching among views. Each app is then expressed as an attributed view graph, which is converted into a vector and fed to classifiers for recognizing its quality classes. Our evaluation with an app dataset from Google Play reports that AppQ achieves the best performance with accuracy of 85.0\%. This shows a lot of promise to warm-start app grading and recommendation systems with AppQ.
Recomposition vs. Prediction: A Novel Anomaly Detection for Discrete Events Based On Autoencoder
Dec 27, 2020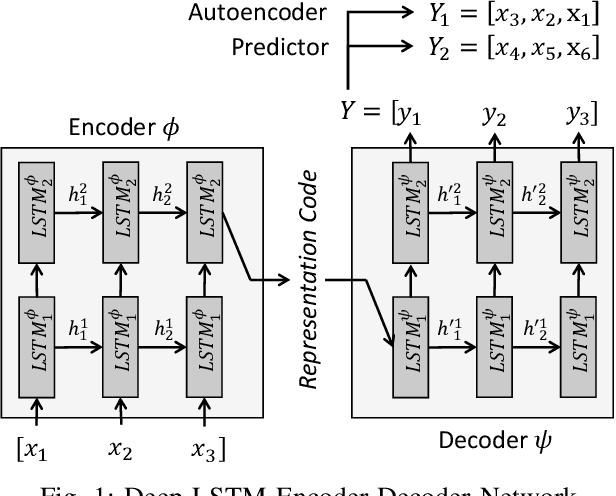
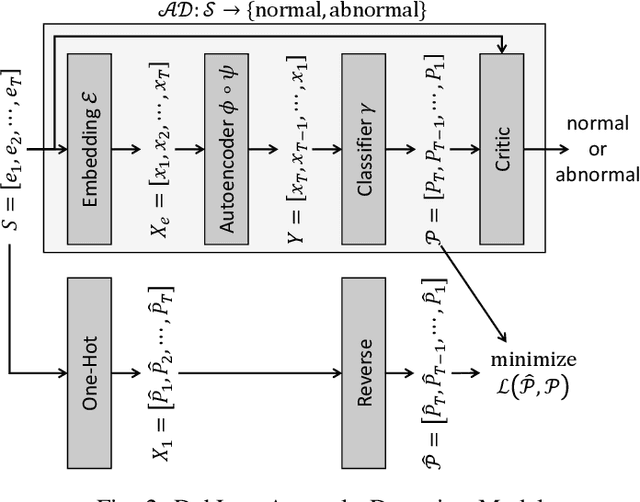
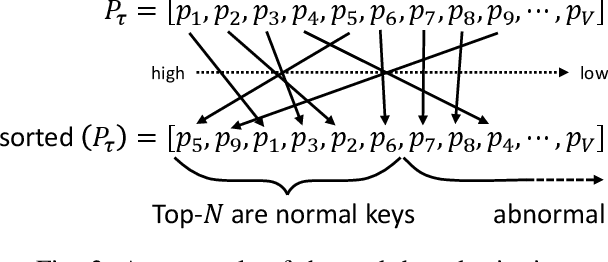

One of the most challenging problems in the field of intrusion detection is anomaly detection for discrete event logs. While most earlier work focused on applying unsupervised learning upon engineered features, most recent work has started to resolve this challenge by applying deep learning methodology to abstraction of discrete event entries. Inspired by natural language processing, LSTM-based anomaly detection models were proposed. They try to predict upcoming events, and raise an anomaly alert when a prediction fails to meet a certain criterion. However, such a predict-next-event methodology has a fundamental limitation: event predictions may not be able to fully exploit the distinctive characteristics of sequences. This limitation leads to high false positives (FPs) and high false negatives (FNs). It is also critical to examine the structure of sequences and the bi-directional causality among individual events. To this end, we propose a new methodology: Recomposing event sequences as anomaly detection. We propose DabLog, a Deep Autoencoder-Based anomaly detection method for discrete event Logs. The fundamental difference is that, rather than predicting upcoming events, our approach determines whether a sequence is normal or abnormal by analyzing (encoding) and reconstructing (decoding) the given sequence. Our evaluation results show that our new methodology can significantly reduce the numbers of FPs and FNs, hence achieving a higher $F_1$ score.
Time-Window Group-Correlation Support vs. Individual Features: A Detection of Abnormal Users
Dec 27, 2020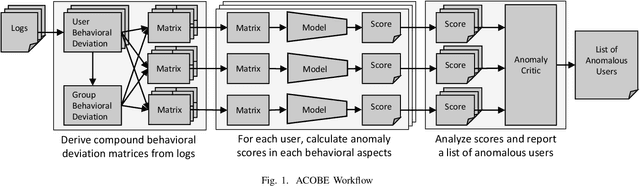
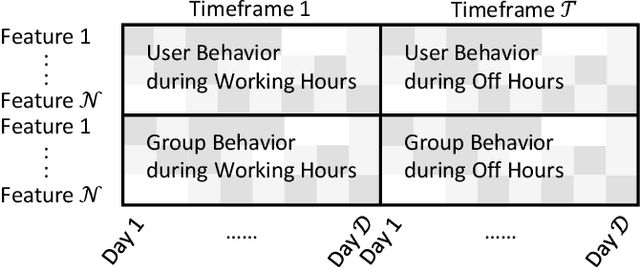
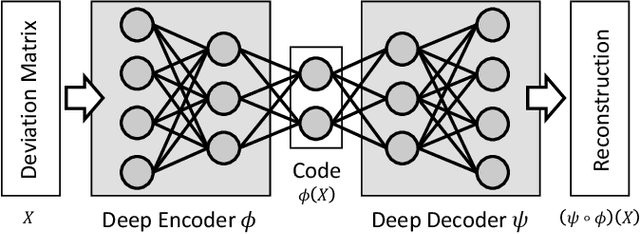
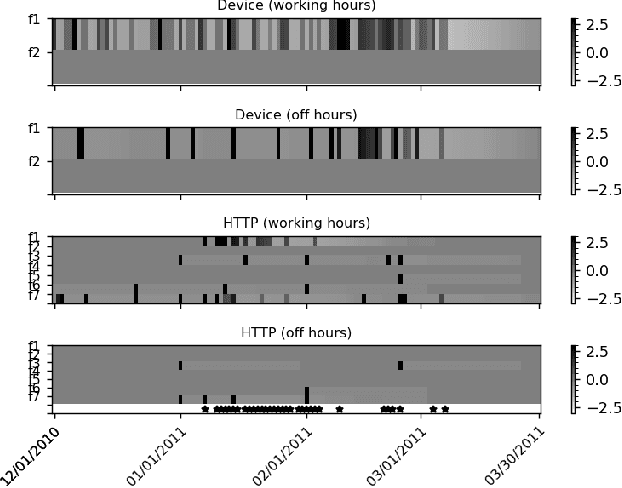
Autoencoder-based anomaly detection methods have been used in identifying anomalous users from large-scale enterprise logs with the assumption that adversarial activities do not follow past habitual patterns. Most existing approaches typically build models by reconstructing single-day and individual-user behaviors. However, without capturing long-term signals and group-correlation signals, the models cannot identify low-signal yet long-lasting threats, and will wrongly report many normal users as anomalies on busy days, which, in turn, lead to high false positive rate. In this paper, we propose ACOBE, an Anomaly detection method based on COmpound BEhavior, which takes into consideration long-term patterns and group behaviors. ACOBE leverages a novel behavior representation and an ensemble of deep autoencoders and produces an ordered investigation list. Our evaluation shows that ACOBE outperforms prior work by a large margin in terms of precision and recall, and our case study demonstrates that ACOBE is applicable in practice for cyberattack detection.
Mitigating Backdoor Attacks in Federated Learning
Oct 28, 2020
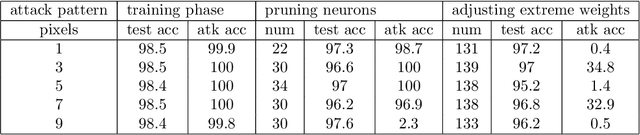
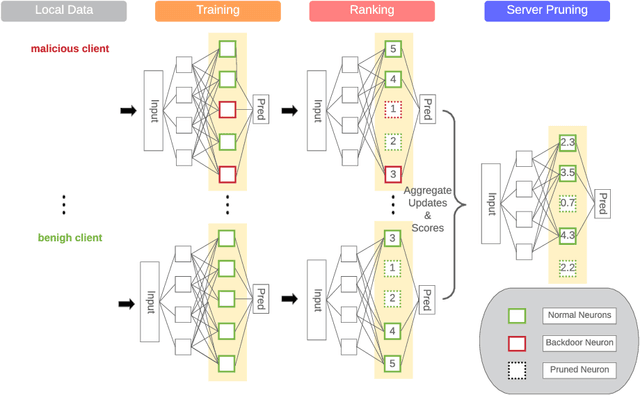
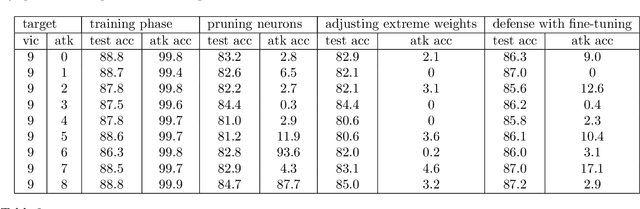
Malicious clients can attack federated learning systems by using malicious data, including backdoor samples, during the training phase. The compromised global model will perform well on the validation dataset designed for the task. However, a small subset of data with backdoor patterns may trigger the model to make a wrong prediction. Previously, there was an arms race. Attackers tried to conceal attacks and defenders tried to detect attacks during the aggregation stage of training on the server-side in a federated learning system. In this work, we propose a new method to mitigate backdoor attacks after the training phase. Specifically, we designed a federated pruning method to remove redundant neurons in the network and then adjust the model's extreme weight values. Experiments conducted on distributed Fashion-MNIST have shown that our method can reduce the average attack success rate from 99.7% to 1.9% with a 5.5% loss of test accuracy on the validation dataset. To minimize the pruning influence on test accuracy, we can fine-tune after pruning, and the attack success rate drops to 6.4%, with only a 1.7% loss of test accuracy.
No Peeking through My Windows: Conserving Privacy in Personal Drones
Aug 26, 2019



The drone technology has been increasingly used by many tech-savvy consumers, a number of defense companies, hobbyists and enthusiasts during the last ten years. Drones often come in various sizes and are designed for a multitude of purposes. Nowadays many people have small-sized personal drones for entertainment, filming, or transporting items from one place to another. However, personal drones lack a privacy-preserving mechanism. While in mission, drones often trespass into the personal territories of other people and capture photos or videos through windows without their knowledge and consent. They may also capture video or pictures of people walking, sitting, or doing private things within the drones' reach in clear form without their go permission. This could potentially invade people's personal privacy. This paper, therefore, proposes a lightweight privacy-preserving-by-design method that prevents drones from peeking through windows of houses and capturing people doing private things at home. It is a fast window object detection and scrambling technology built based on image-enhancing, morphological transformation, segmentation and contouring processes (MASP). Besides, a chaotic scrambling technique is incorporated into it for privacy purpose. Hence, this mechanism detects window objects in every image or frame of a real-time video and masks them chaotically to protect the privacy of people. The experimental results validated that the proposed MASP method is lightweight and suitable to be employed in drones, considered as edge devices.
Backdoor Embedding in Convolutional Neural Network Models via Invisible Perturbation
Aug 30, 2018
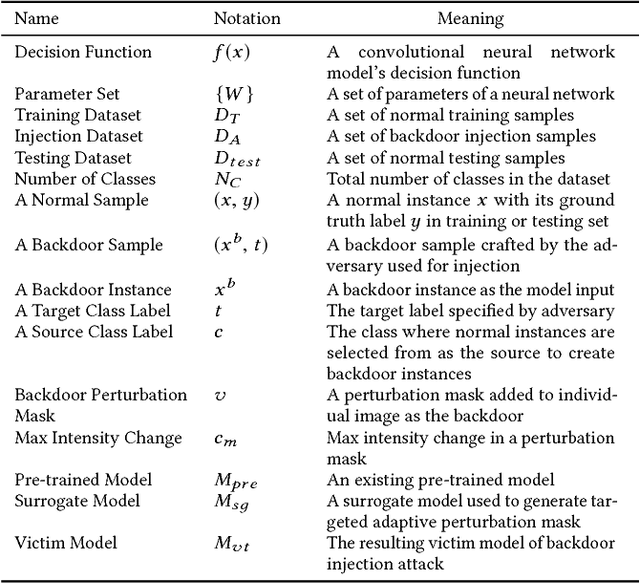
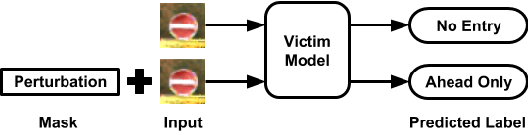
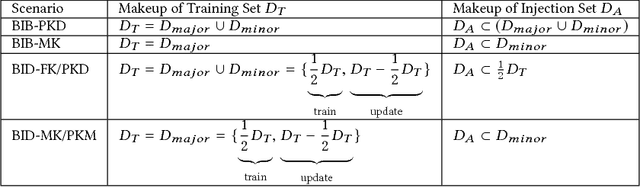
Deep learning models have consistently outperformed traditional machine learning models in various classification tasks, including image classification. As such, they have become increasingly prevalent in many real world applications including those where security is of great concern. Such popularity, however, may attract attackers to exploit the vulnerabilities of the deployed deep learning models and launch attacks against security-sensitive applications. In this paper, we focus on a specific type of data poisoning attack, which we refer to as a {\em backdoor injection attack}. The main goal of the adversary performing such attack is to generate and inject a backdoor into a deep learning model that can be triggered to recognize certain embedded patterns with a target label of the attacker's choice. Additionally, a backdoor injection attack should occur in a stealthy manner, without undermining the efficacy of the victim model. Specifically, we propose two approaches for generating a backdoor that is hardly perceptible yet effective in poisoning the model. We consider two attack settings, with backdoor injection carried out either before model training or during model updating. We carry out extensive experimental evaluations under various assumptions on the adversary model, and demonstrate that such attacks can be effective and achieve a high attack success rate (above $90\%$) at a small cost of model accuracy loss (below $1\%$) with a small injection rate (around $1\%$), even under the weakest assumption wherein the adversary has no knowledge either of the original training data or the classifier model.