 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoneyIoT: Adaptive High-Interaction Honeypot for IoT Devices Through Reinforcement Learning
May 10, 2023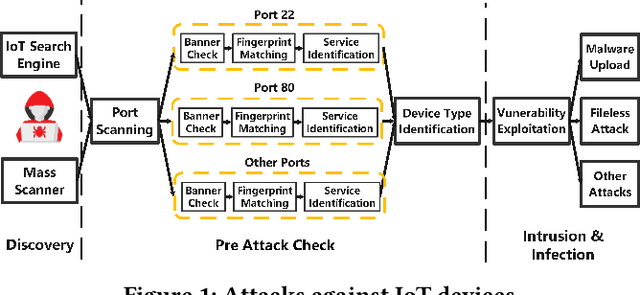

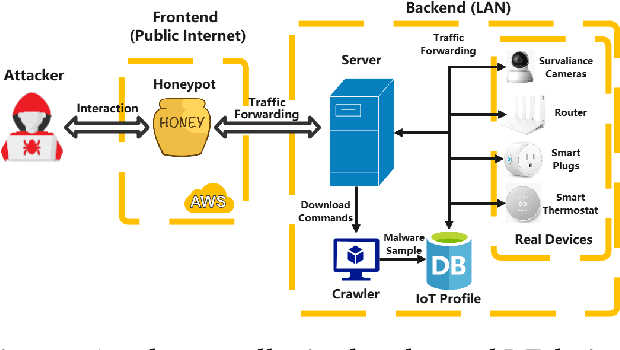

As IoT devices are becoming widely deployed, there exist many threats to IoT-based systems due to their inherent vulnerabilities. One effective approach to improving IoT security is to deploy IoT honeypot systems, which can collect attack information and reveal the methods and strategies used by attackers. However, building high-interaction IoT honeypots is challenging due to the heterogeneity of IoT devices. Vulnerabilities in IoT devices typically depend on specific device types or firmware versions, which encourages attackers to perform pre-attack checks to gather device information before launching attacks. Moreover, conventional honeypots are easily detected because their replying logic differs from that of the IoT devices they try to mimic. To address these problems, we develop an adaptive high-interaction honeypot for IoT devices, called HoneyIoT. We first build a real device based attack trace collection system to learn how attackers interact with IoT devices. We then model the attack behavior through markov decision process and leverage reinforcement learning techniques to learn the best responses to engage attackers based on the attack trace. We also use differential analysis techniques to mutate response values in some fields to generate high-fidelity responses. HoneyIoT has been deployed on the public Internet. Experimental results show that HoneyIoT can effectively bypass the pre-attack checks and mislead the attackers into uploading malware. Furthermore, HoneyIoT is covert against widely used reconnaissance and honeypot detection tools.
Prediction of GPU Failures Under Deep Learning Workloads
Jan 27, 2022
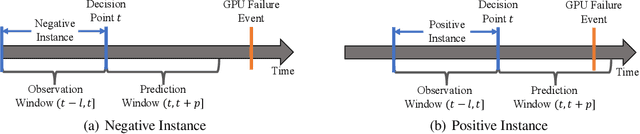
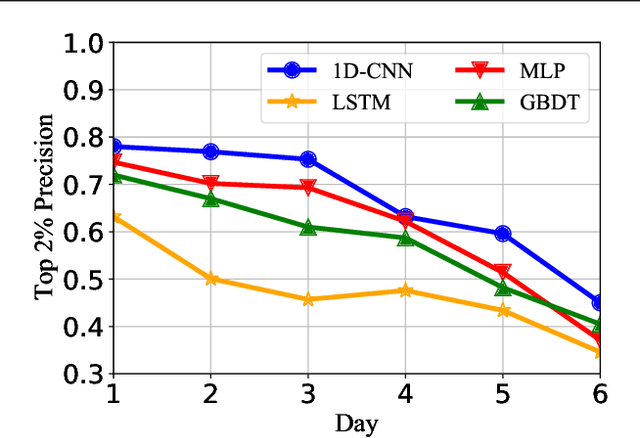

Graphics processing units (GPUs) are the de facto standard for processing deep learning (DL) tasks. Meanwhile, GPU failures, which are inevitable, cause severe consequences in DL tasks: they disrupt distributed trainings, crash inference services, and result in service level agreement violations. To mitigate the problem caused by GPU failures, we propose to predict failures by using ML models. This paper is the first to study prediction models of GPU failures under large-scale production deep learning workloads. As a starting point, we evaluate classic prediction models and observe that predictions of these models are both inaccurate and unstable. To improve the precision and stability of predictions, we propose several techniques, including parallel and cascade model-ensemble mechanisms and a sliding training method. We evaluate the performances of our various techniques on a four-month production dataset including 350 million entries. The results show that our proposed techniques improve the prediction precision from 46.3\% to 84.0\%.